
What Happens When You Append Rows to a Pandas DataFrame
Understanding the internal working of Pandas DataFrame.

Consider the following graph. It depicts the run-time of a row append operation on Pandas DataFrame.
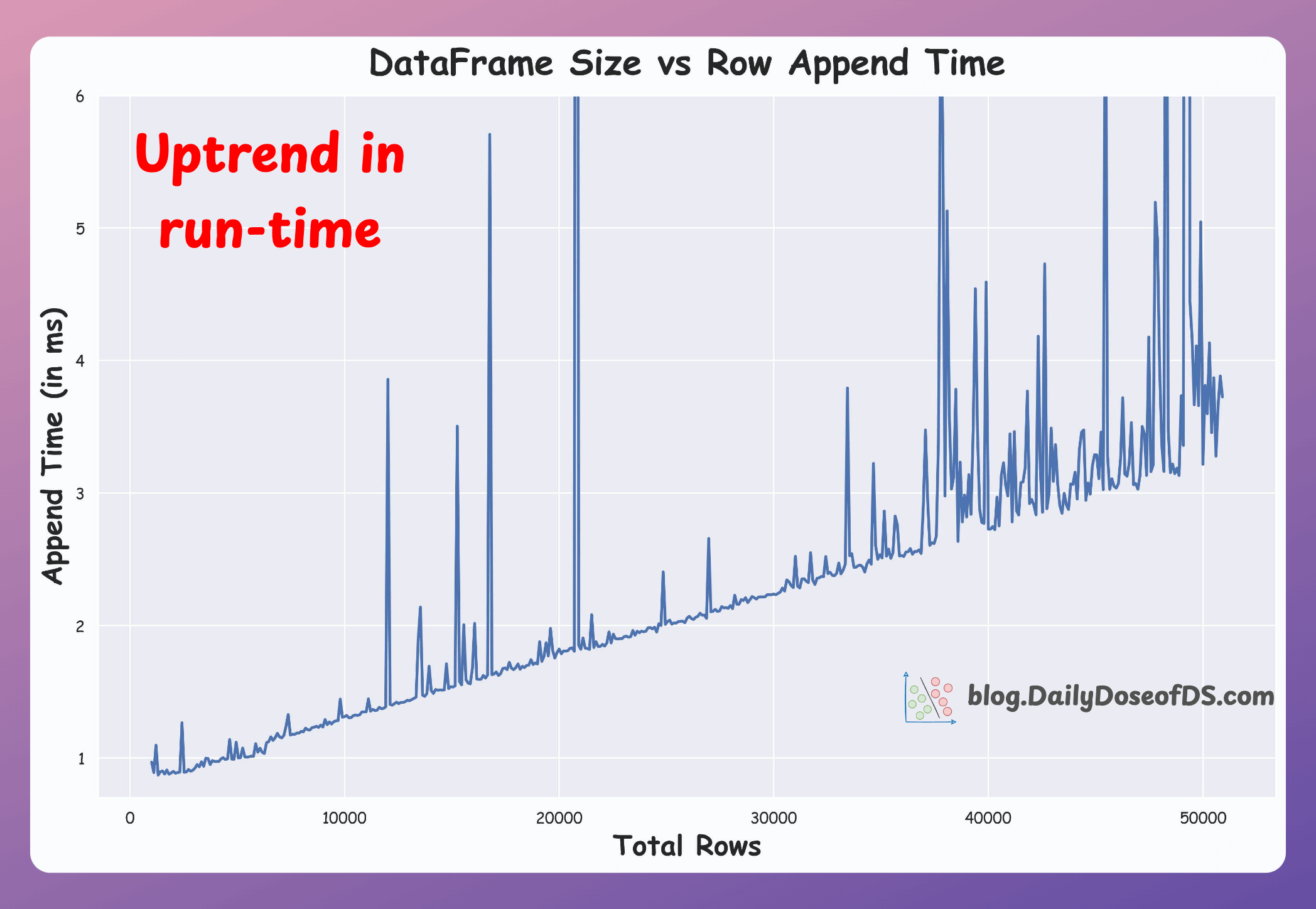
Why do we observe an uptrend here?
And why are there so many spikes in between?
Let’s understand this today.
Why append run-time increases?
To understand this, first, we must learn about Pandas DataFrame data structure and how it is stored in memory.
A DataFrame is a column-major data structure.
This means that consecutive elements in a column are stored next to each other in memory, as depicted below:
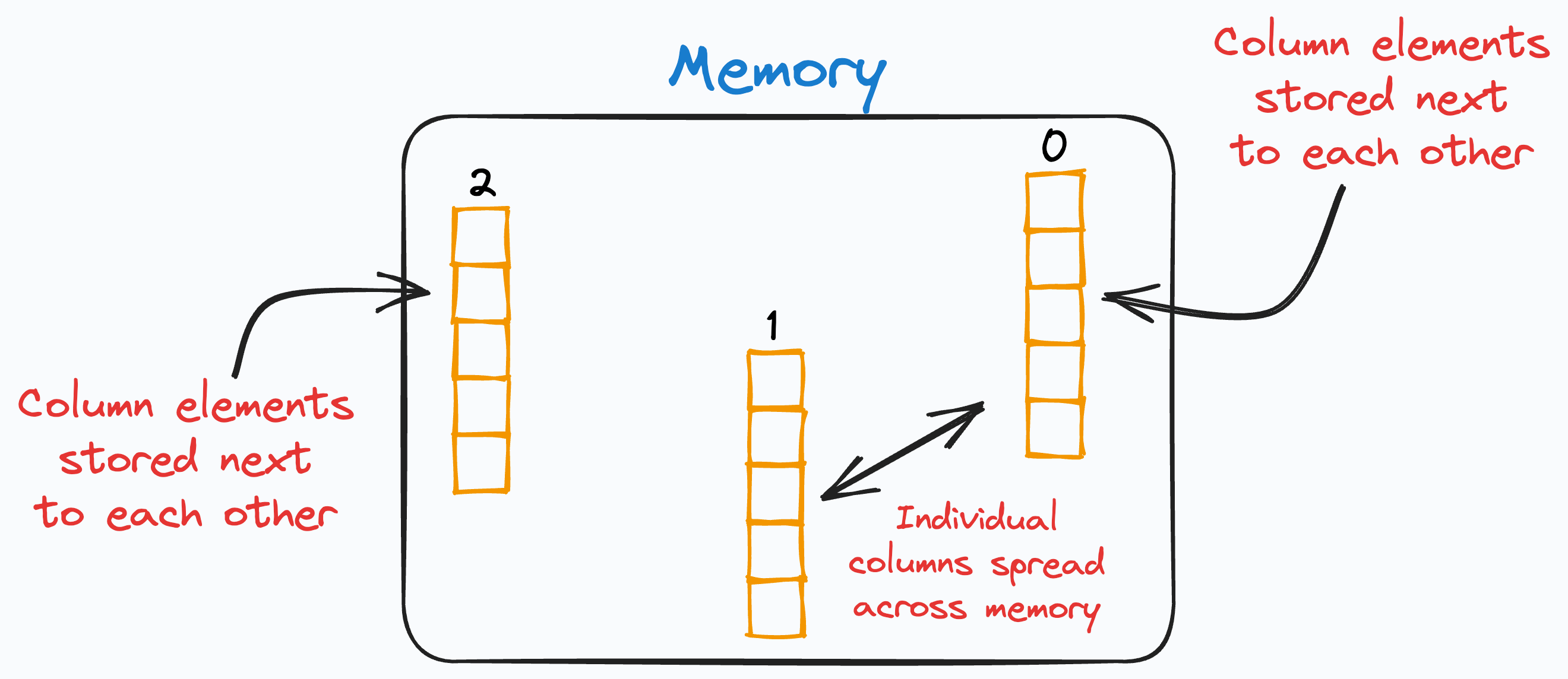
Of course, the individual columns may be spread across different locations in memory. However, the elements of each column are ALWAYS together.
Now, as new rows are added, Pandas always tries to preserve its column-major form.
But while adding new rows, at times, there’s not enough space to accommodate them while also preserving the column-major structure.
In such a case, existing data is moved to a new memory location where Pandas finds a contiguous block of memory.
Thus, as the size grows, memory reallocation gets more frequent, and the run time keeps increasing.
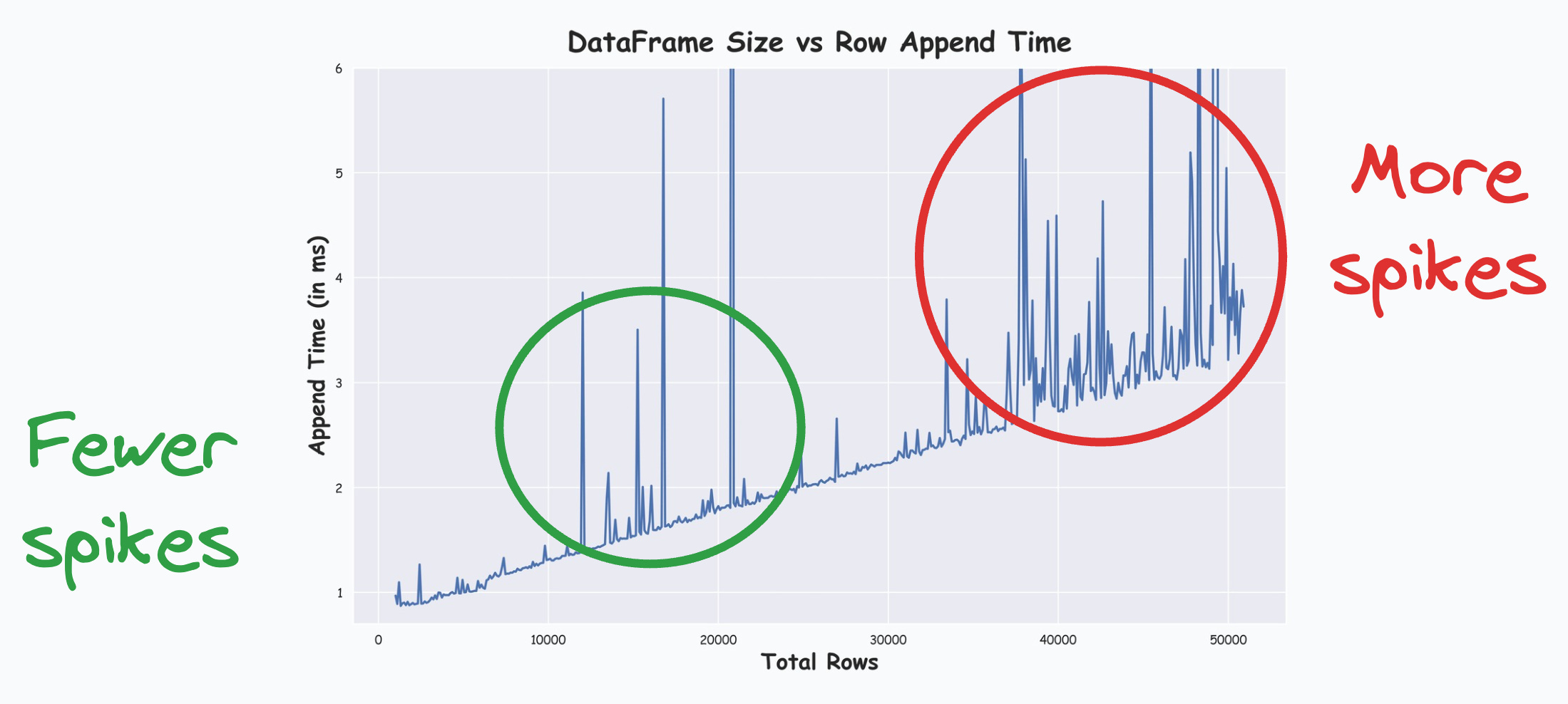
This explains the run-time increase we saw earlier.
How to mitigate this?
It is clear that the increase in run-time solely arises because Pandas is trying to maintain its column-major structure.
While the run-time of append operation is in milliseconds, which may not matter too much in many situations, nonetheless, if you care about it:
First, convert the DataFrame to another data structure — a dictionary or a NumPy array.
Then, carry out the append operations in this data structure
When you are done, convert it back to a Pandas DataFrame.
That said, please note that this is just about appending new rows.
Adding new columns is not a problem since it does not conflict with other columns.
👉 Over to you: What could be some other ways to mitigate this?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Highly insightful Avi. Thanks for sharing
I thought that Pandas used Numpy under the hood. If so how converting pandas column into Numpy to add a row would change the pattern you mention ( reallocation ) ?