
What is Contrastive Learning?
A popular ML interview question, explained with a use case.

A 50x easier method to use the cloud!
Using the cloud is much harder than programming itself. Running any simple Python workflow on the cloud requires:
navigating consoles
setting IAM policies
writing YAML configs
monitoring billing spikes
Coiled lets you run any Python code by adding just two lines of code. In the snippet below, we used Coiled to analyse 1TB of data on the cloud (this can run 100% privately on your own cloud infra):

Import coiled.
Create a cluster by specifying hardware, region, etc.
Coiled is free for most users, with 500 free CPU hours per month, and you can:
Run queries on any big cloud VM,
Run independent jobs in parallel on many VMs,
Run coordinated analyses on VM clusters, and more.
You can learn more about running DataFrame queries on Coiled in this blog →
Thanks to Coiled for partnering today!
What is Contrastive Learning?
Contrastive Learning is a popular self-supervised learning technique that teaches models to learn useful representations by comparing samples.
Let’s understand more by considering a real-world task.
As an ML engineer, imagine you are responsible for building a face unlock system.
Let’s look through some possible options:
1) Building a Binary classifier
Output 1 if the true user is opening the mobile; 0 otherwise.
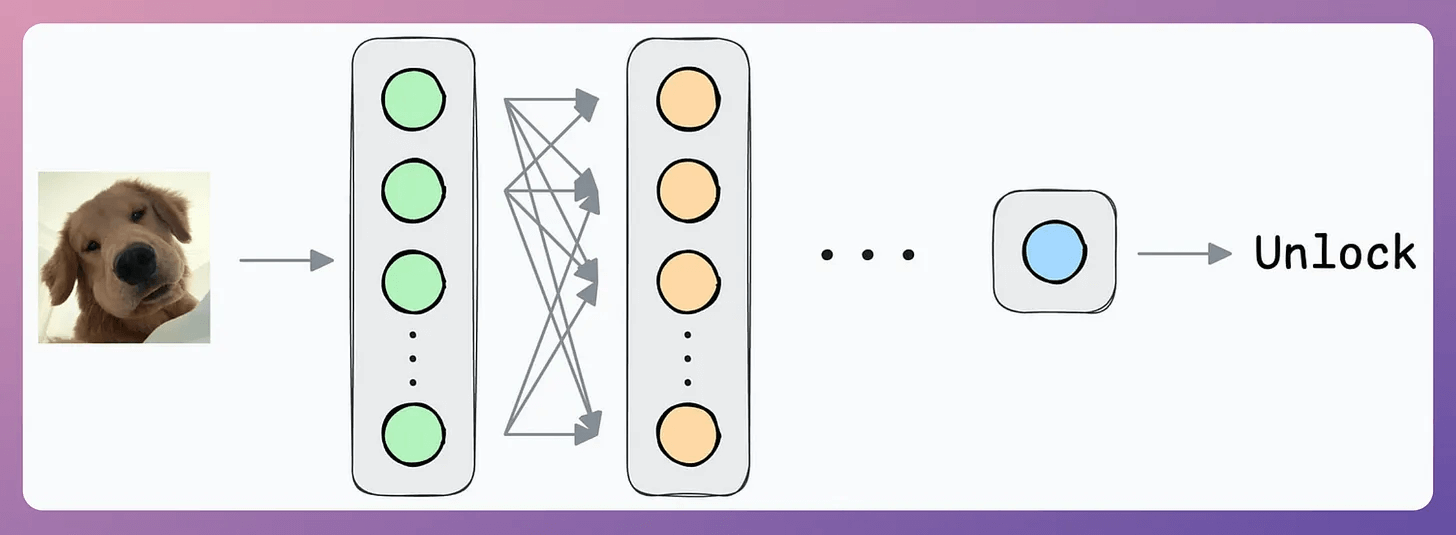
Initially, you can ask the user to input facial data to train the model.
But that’s where you identify the problem.
Their inputs will belong to “Class 1.”

Now, you can’t ask the user to find someone to volunteer for “Class 0” samples since it’s too much hassle for them.
Also, you need diverse “Class 0” samples. Samples from just one or two faces might not be sufficient.
The next possible solution you think of is…
Maybe ship some negative samples (Class 0) to the device to train the model.

Might work.
But then you realize another problem:
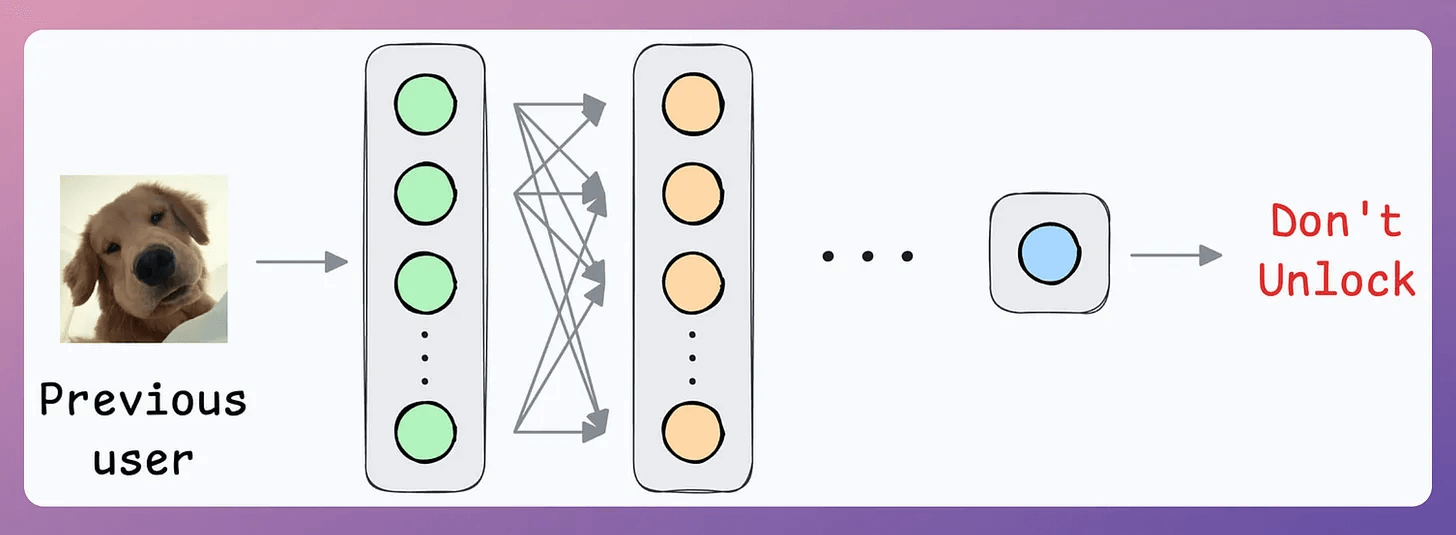
What if another person wants to use the same device?
Since all new samples will belong to the “new face” during adaptation, what if the model forgets the first face?
2) How about transfer learning?
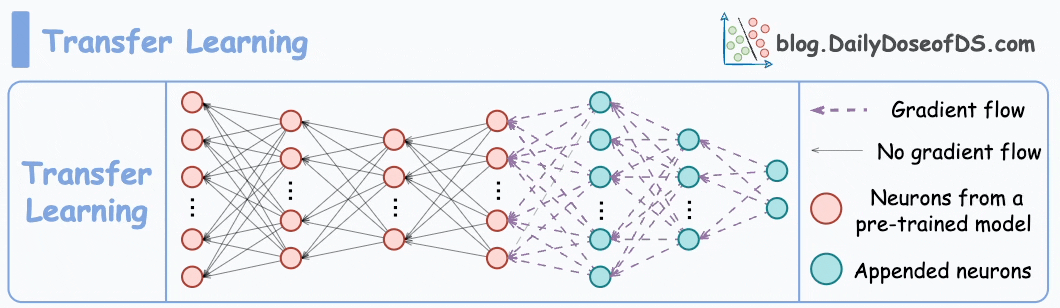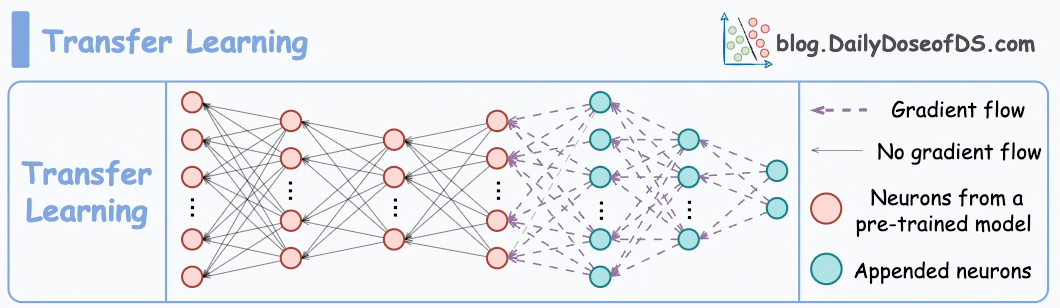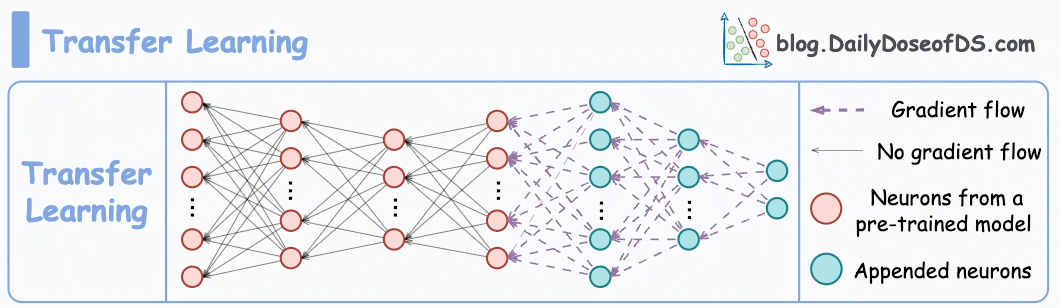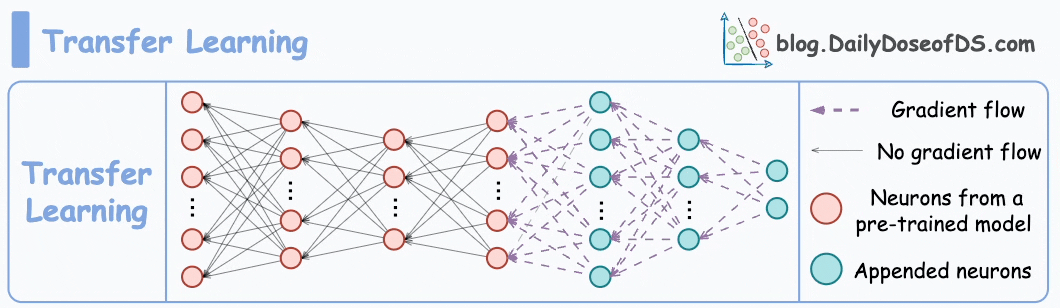
Train a neural network model (base model) on some related task → This will happen before shipping the model to the user’s device.
Next, replace the last few layers of the base model with untrained layers and ship it to the device.
The first few layers would have learned to identify the key facial features, and from there on, training on the user’s face won’t require much data.
But yet again, you realize that you shall run into the same problems you observed with the binary classification model since the new layers will still be designed to predict 1 or 0.
Solution: Contrastive learning using Siamese Networks
At its core, a Siamese network determines whether two inputs are similar.
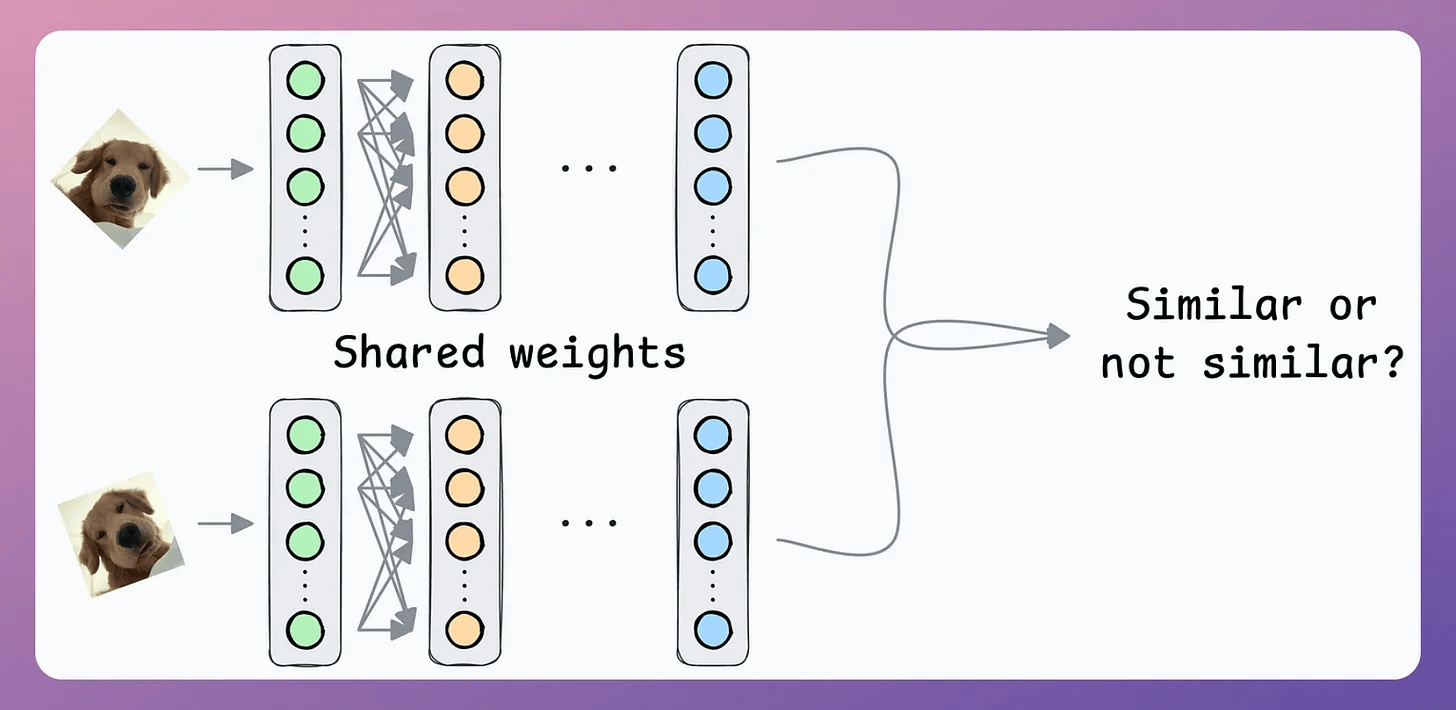
It does this by learning to effectively map both inputs to a shared embedding space (the blue layer above):
If the distance between the embeddings is LOW, they are similar.
If the distance between the embeddings is HIGH, they are dissimilar.
They are beneficial for tasks where the goal is to compare two data points rather than to classify them into predefined categories/classes.
This is how it will work in our case:
Create a dataset of face pairs:

If a pair belongs to the same person, the true label will be 0.
If a pair belongs to different people, the true label will be 1.
After creating this data, define a network like this:
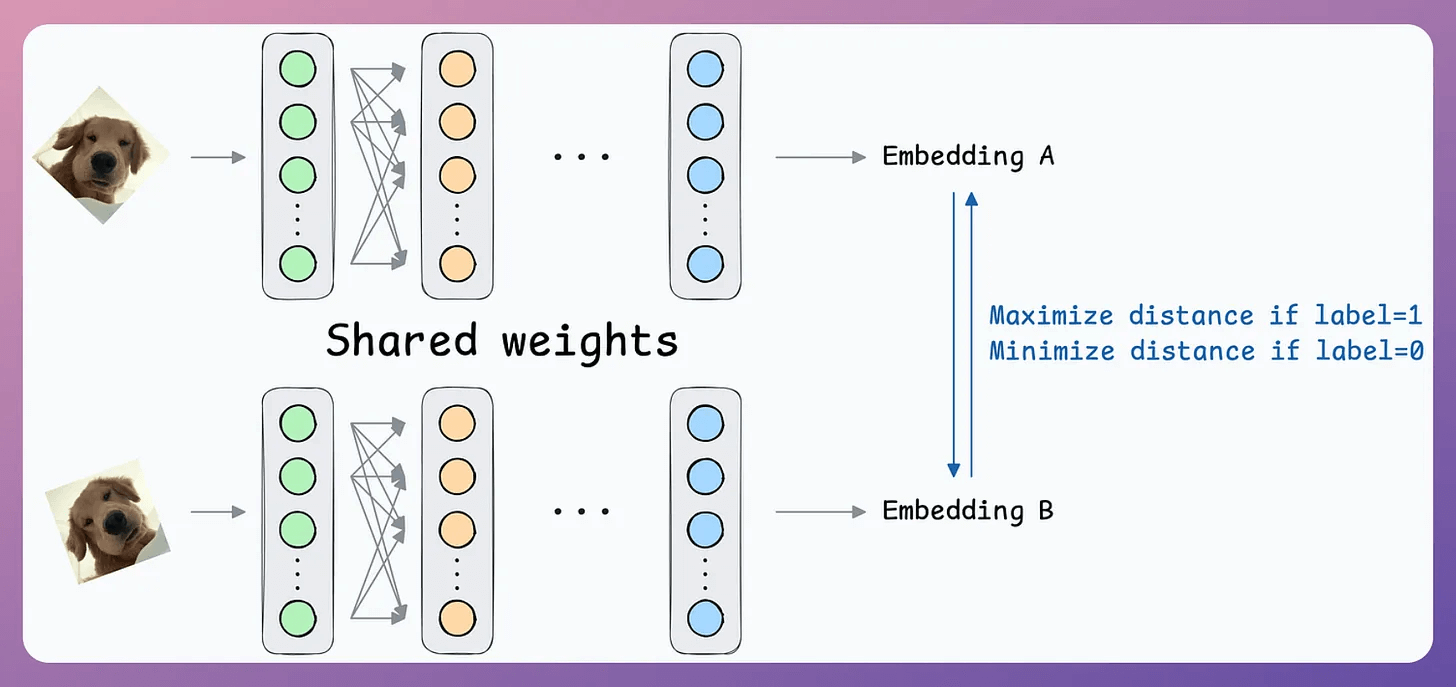
Pass both inputs through the same network to generate two embeddings.
If the true label is 0 (same person) → minimize the distance between the two embeddings.
If the true label is 1 (different person) → maximize the distance between the two embeddings.
Contrastive loss (defined below) helps us train such a model:
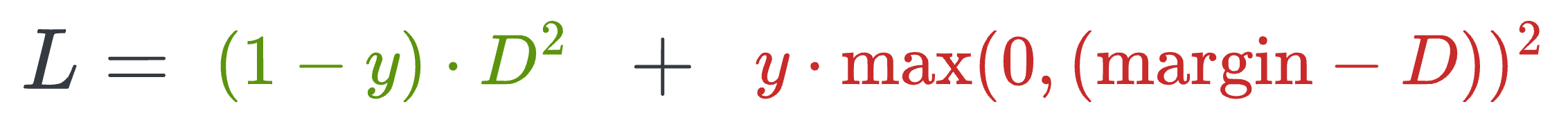
where:
yis the true label.Dis the distance between two embeddings.marginis a hyperparameter, typically greater than 1.
Here’s how this particular loss function helps:
When
y=1(different people), the loss will be the following, which will be minimum when D is close to themarginvalue, leading to more distance between the embeddings.
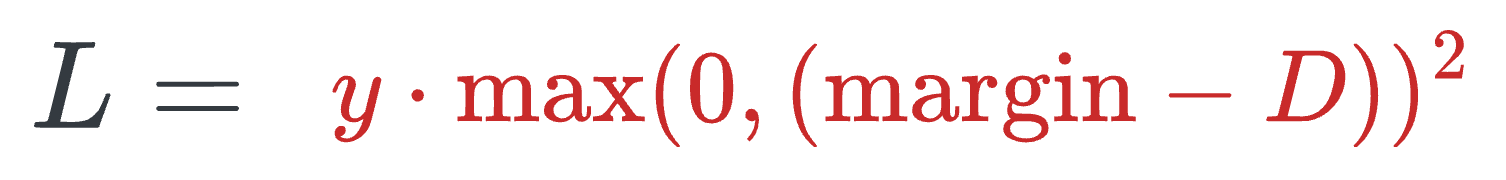
When y=0 (same person), the loss will be the following, which will be minimum when D is close to 0, leading to a low distance between the embeddings.
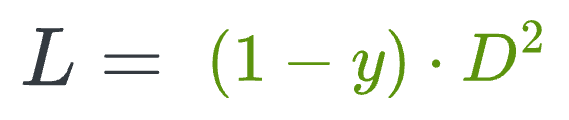
This way, we can ensure that:
when the inputs are similar, they lie closer in the embedding space.
when the inputs are dissimilar, they lie far in the embedding space.
Siamese Networks in face unlock
Here’s how it will help in the face unlock application.
First, train the model on several image pairs using contrastive loss.
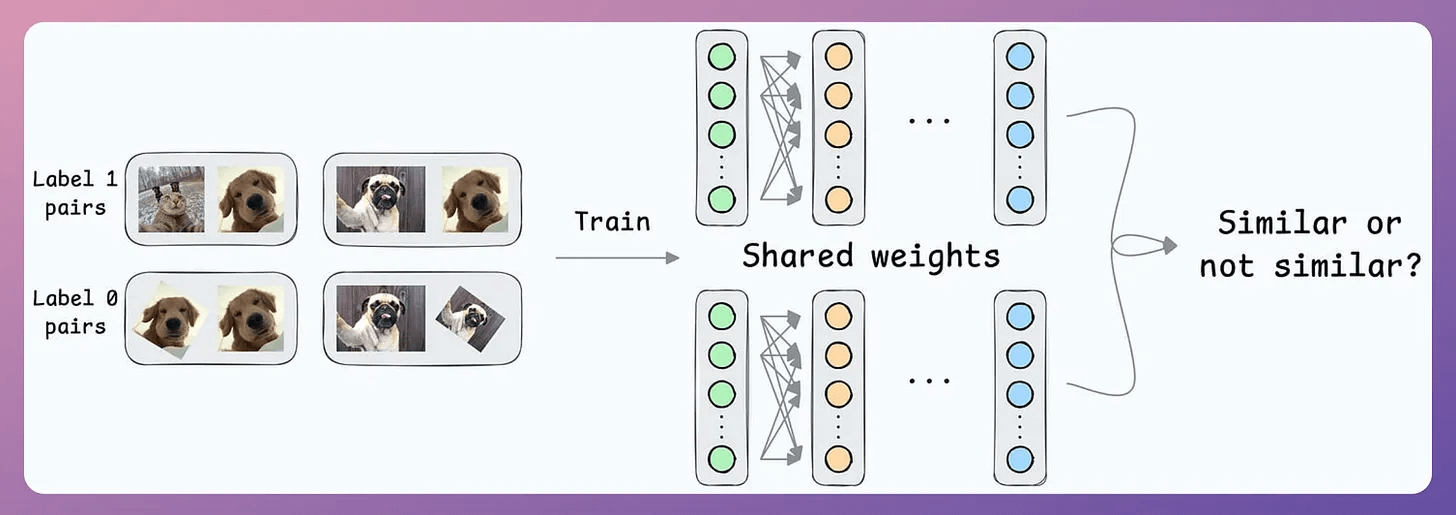
This model (likely after model compression) will be shipped to the user’s device.
During the setup phase, the user will provide facial data, which will create a user embedding:
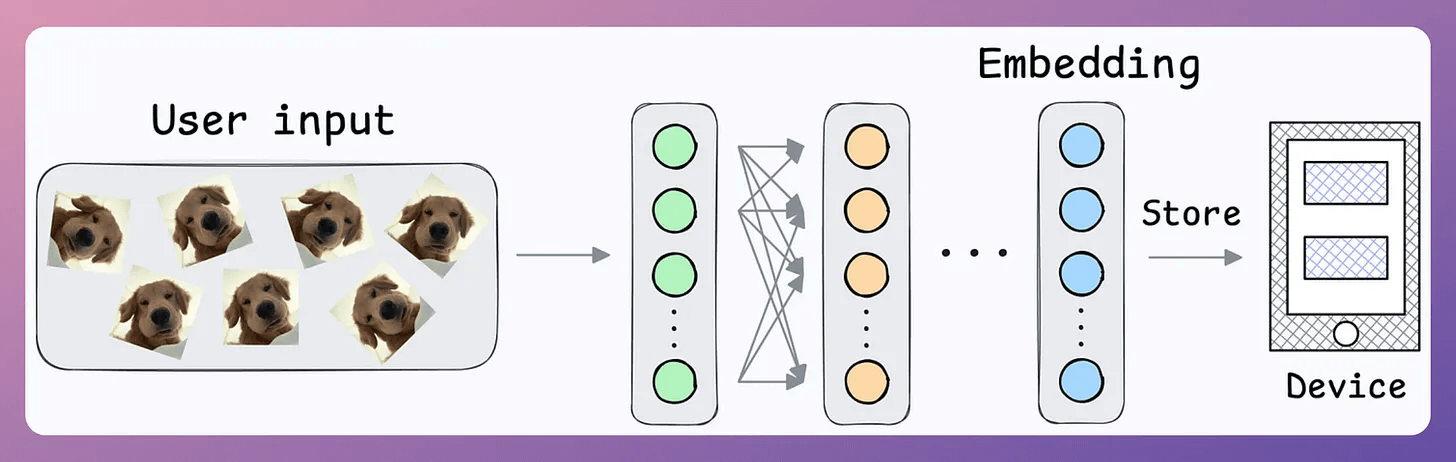
This embedding will be stored in the device’s memory.
Next, when the user wants to unlock the mobile, a new embedding can be generated and compared against the available embedding:
Action: Unlock the mobile if the distance is small.
Done!
Note that no further training was required here, like in the earlier case of binary classification.
Also, what if multiple people want to add their face IDs?
No problem.
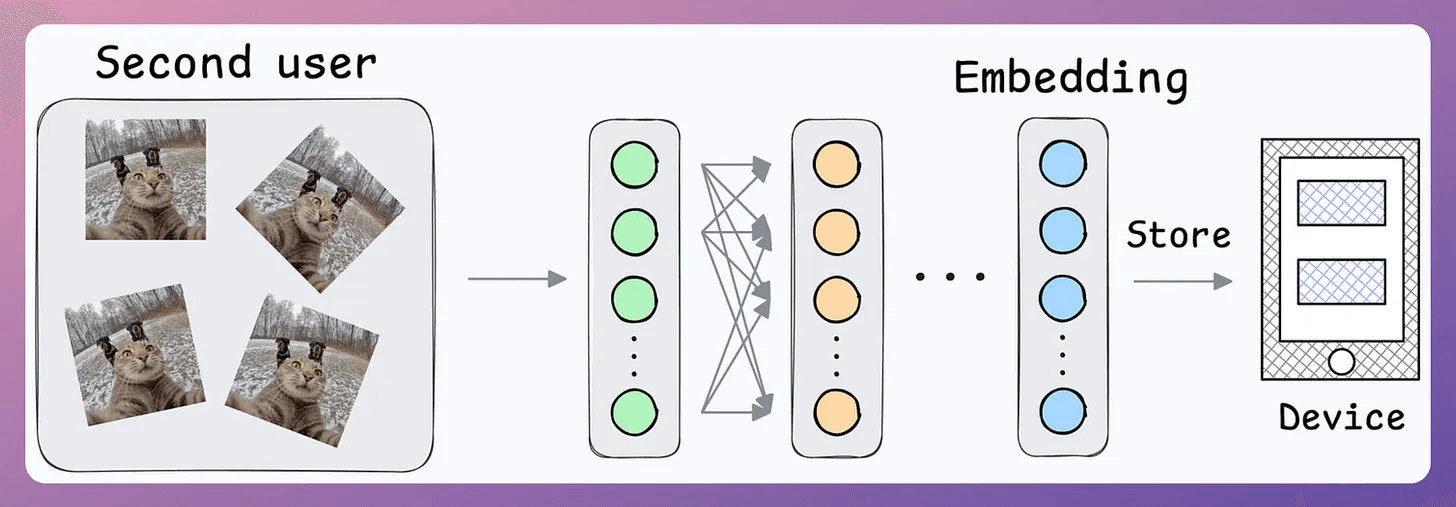
Create another embedding for the new user.
During unlock, compare the incoming user against all stored embeddings.
We shall discuss a simple implementation of Siamese Networks using PyTorch soon!
Until then, here’s some further hands-on reading to learn how to build on-device ML applications:
Learn how to build privacy-first ML systems (with implementations): Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
👉 Over to you: Siamese Networks are not the only way to solve this problem. What other architectures can work?
Thanks for reading!