
What is (was?) GIL in Python?
Update from Python 3.13.

Python 3.13 was released recently.
Of the many interesting updates (which I intend to cover this week), the update that you can disable GIL (global interpreter lock) is getting the most attention.

However, even before I can explain what this update means, it’s essential to understand what GIL is in the first place and why Python had been using it so far.
Let’s dive in!
Some fundamentals
A process is isolated from other processes and operates in its own memory space. This isolation means that if one process crashes, it typically does not affect other processes.
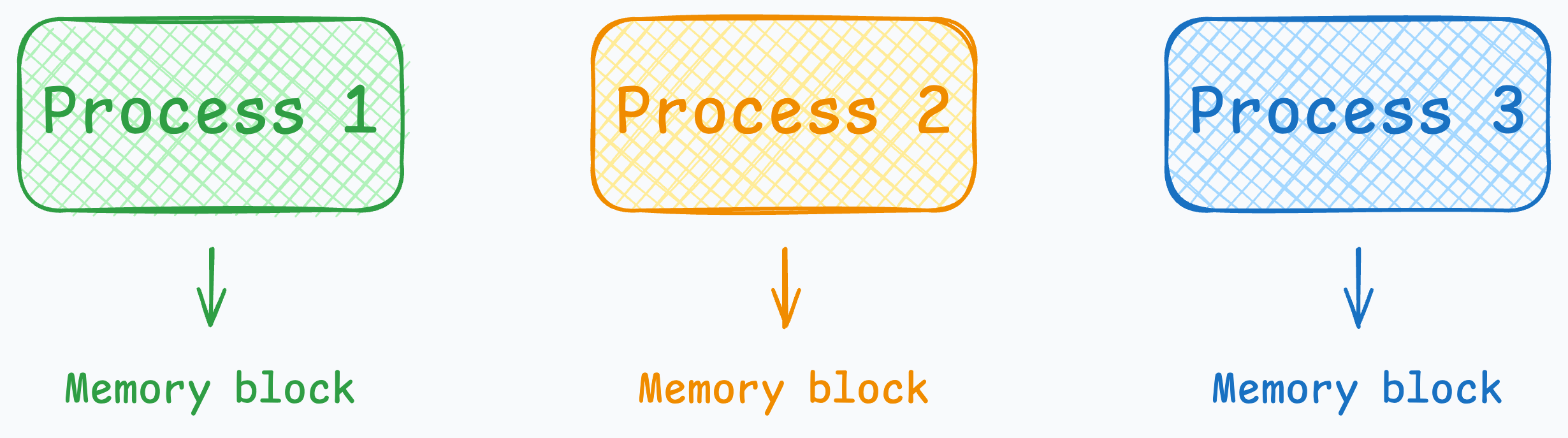
Multi-threading occurs when a single process has multiple threads. These threads share the same resources, like memory.

GIL explained visually
Simply put, GIL (global interpreter lock) restricts a process from running more than ONE thread at a time, as depicted below:

In other words, while a process can have multiple threads, ONLY ONE can run at a given time.
Quite evidently, the process cannot use multiple CPU cores for performance optimization, which means multi-threading leads to similar (or even poor) performance as single-threading.
Let me show you this real quick with a code demo!
First, we start with some imports and define a long function:

The code for single threading, wherein we invoke the same function twice, is demonstrated below:

With multi-threading, however, we can create two threads, one for each function. This is demonstrated below:

As shown above, this performs hardly any better than single-threading.
The reason?
GIL.
By the way, as you might expect, we do experience a run-time boost with multi-processing:

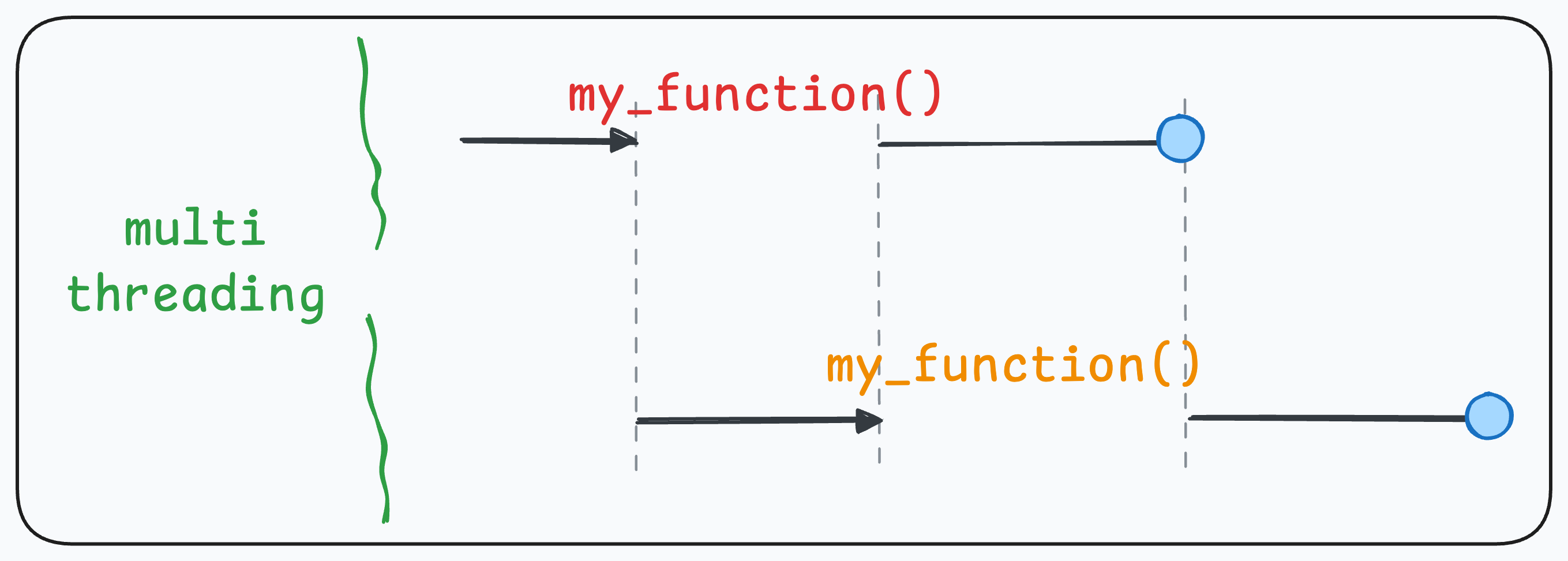
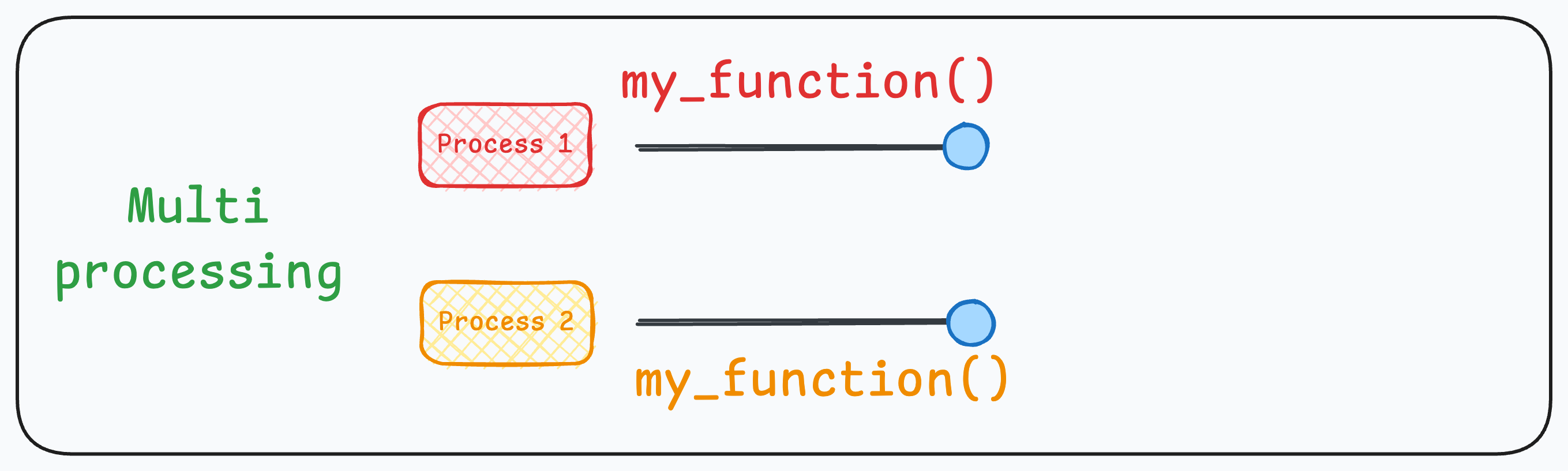
The above three scenarios (single-threading, multi-threading, and multi-processing) can be explained visually as follows:
Single-threading: A single thread executes the same function twice in order.

Multi-threading: Each thread is assigned the job to execute the function once. Due to GIL, however, only one thread can run at a time:
Multi-processing: Each function is executed under a different process:
If this is clear, you might be having two questions now:
1) Why has Python been using GIL even when it is clearly suboptimal?
Thread safety.
When multiple threads run in a process and share the same resources (such as memory), problems can arise when they try to access and modify the same data.
For instance, consider we have a Python list, and we want to run two operations with two threads:

If t1 runs before t2, we get the following output:

If t2 runs before t1, we get the following output:

Different outputs!
More formally, this can lead to race conditions, where the outcome depends on the timing of the threads’ execution.
If these are not carefully controlled, it can lead to unpredictable behavior.
This, along with a few more reasons, just made it convenient to enforce that only one thread can execute at any given time.
On a side note, GIL usually affects CPU-bound tasks and not I/O-bound tasks, where multi-threading can still be useful.
2) If multi-processing works, why not use that as a workaround?
This is easier said than done.
Unlike threads, which share the same memory space, processes are isolated.
As a result, they cannot directly share data as threads do.
While there are inter-process communication (IPC) mechanisms like pipes, queues, or shared memory to exchange information between processes, they add a ton of complexity.
Thankfully, Python 3.13 allows us to disable GIL, which means a process can fully utilize all CPU cores.
I have been testing Python 3.13 lately, so I intend to share these updates in a detailed newsletter issue this week.
👉 Over to you: What are some other reasons for enforcing GIL in Python?
That said, if you want to get hands-on with actual GPU programming using CUDA, learn about how CUDA operates GPU’s threads, blocks, grids (with visuals), etc., we covered it here: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 100,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Awesome, Thanks for sharing, waiting for the detailed article.