
What's Inside Python 3.14?
+ building your chatgpt with karpathy's nanochat.

Build your own ChatGPT from scratch using Karpathy’s nanochat!

Karpathy’s nanochat is a single, clean, minimal, and hackable codebase to build a modern LLM.
By setting this up, you’ll learn how to:
train a tokenizer from the ground up
pre-training: master next-word prediction
mid-training: teach the model to hold conversations
sft: fine-tune on high-quality dialogue datasets
evaluate and log every step of the process
We’ve created a LightningAI studio on this that you can reproduce with a single click (zero setup required).

You can build your own ChatGPT here →
What’s Inside Python 3.14?
Last week, we talked about the GIL update in Python 3.14.
To recap, GIL (global interpreter lock) restricts a process from running more than ONE thread at a time, as depicted below:
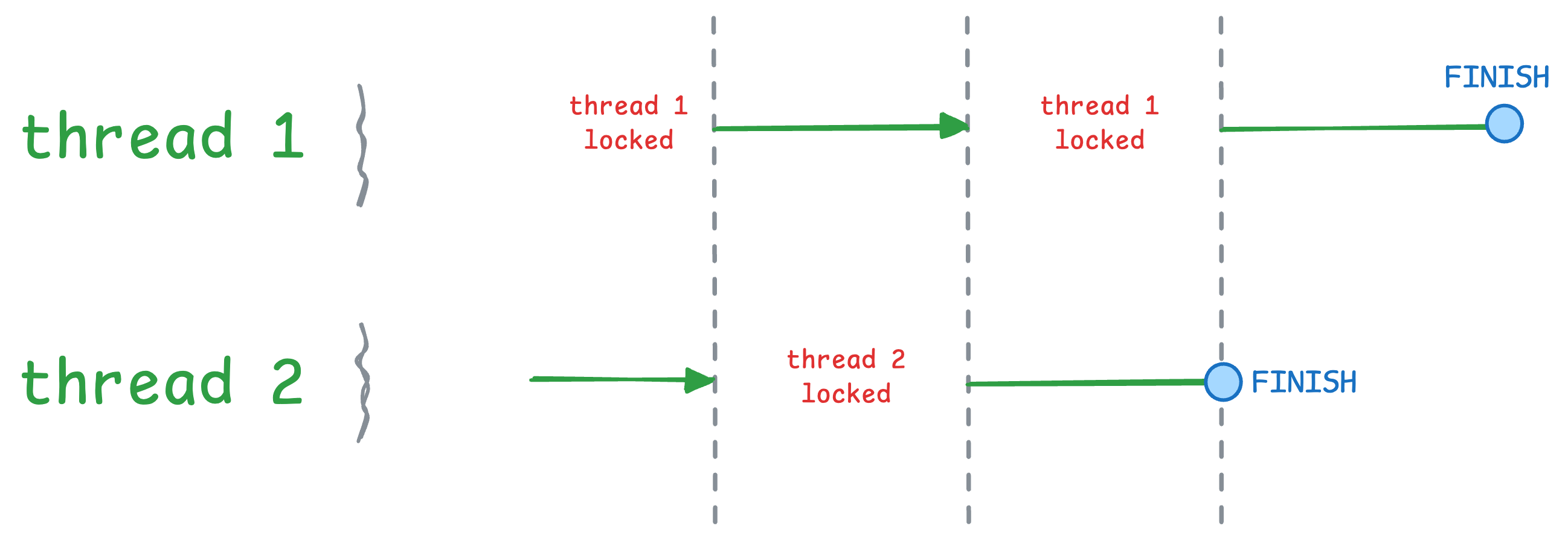
So earlier, even if you wrote multi-threaded code, Python could only run one thread at a time, giving no performance benefit.
But Python 3.14 lets you disable GIL, which means Python can actually run your multi-threaded code as expected.
Python 3.14 has several other updates. Let’s cover them today!
Enhanced REPL and debugging
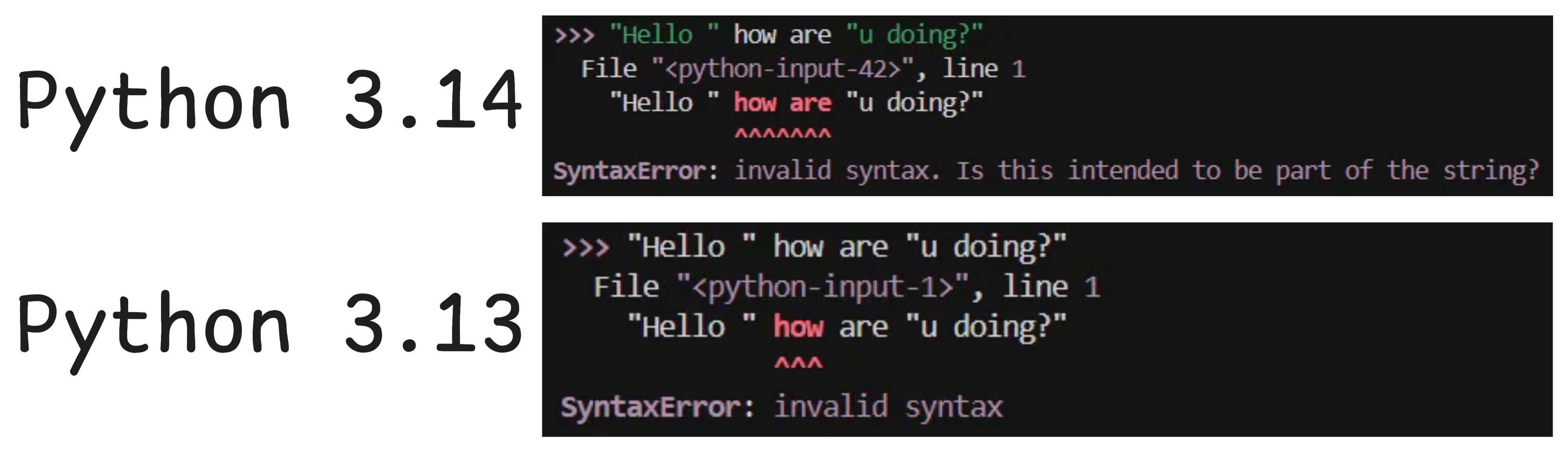
Python 3.13 introduced major changes to the interactive interpreter (also known as REPL), such as multiline editing and auto indentation:


Python 3.14 has improved this by introducing two new changes:
Syntax highlighting: Real-time syntax highlighting with configurable color themes

Code completion: Autocompletion of module names inside
importstatements:
Moving on, Python is now more capable of recognizing common typos and suggesting the correct keyword or syntax.
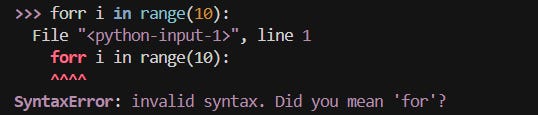
Here’s another comparison of error messages between 3.14 and 3.13:
Template Strings (T-strings)
Python 3.14 introduces a brand new string literal: Template Strings (or T-strings), prefixed with t or T.
Traditional f-strings immediately execute expressions, which can be problematic if the expression contains malicious code or unescaped HTML/SQL from user input.

T-strings delay this execution, allowing users to sanitize or validate the dynamic parts of the string before it’s finalized.

Deferred evaluation of Annotations
Python 3.14 enables deferred evaluation of annotations. This means type hints are no longer evaluated immediately when a class or function is defined.
Let’s understand this.
Traditionally, Python would try to resolve a type hint (like a class name) the moment it read the line of code. So if the class was defined later in the code, you got a NameError like shown below:
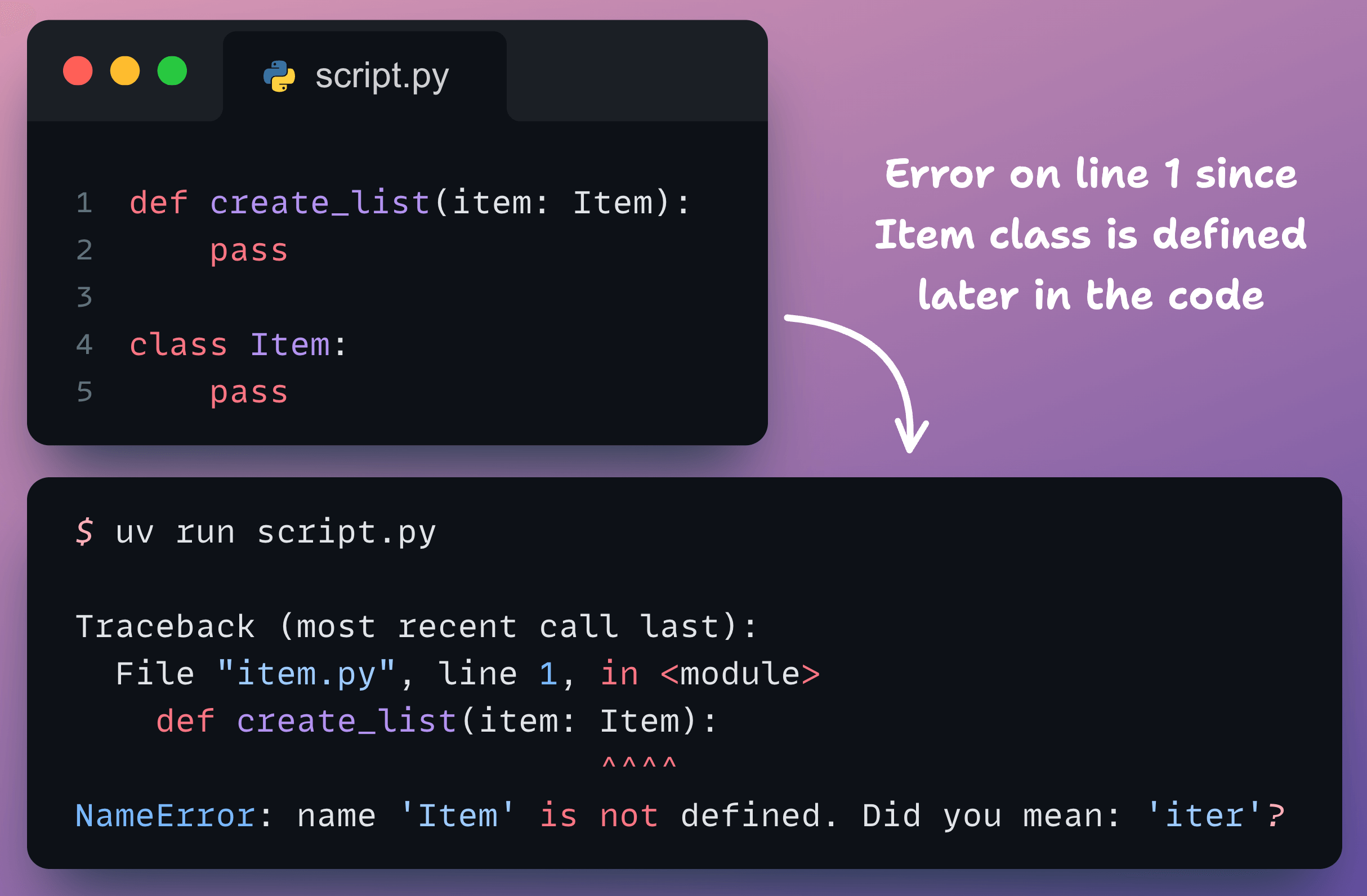
Python introduced the annotations attribute to solve this in earlier versions:
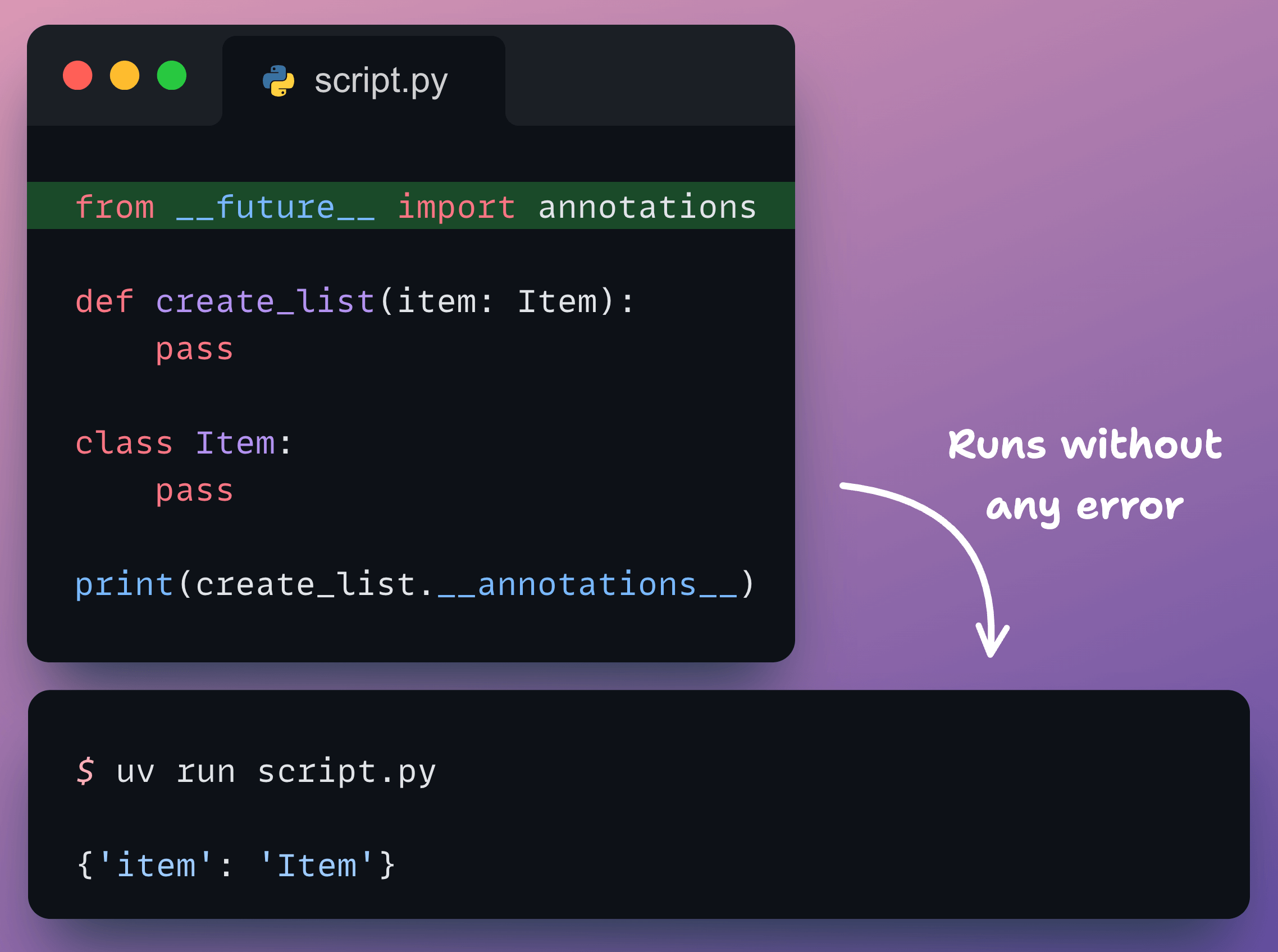
But this method was not that robust. It led to an additional import, and it faced several issues with libraries like Pydantic and FastAPI making it incompatible.
Therefore, in search of a more robust design, deferred evaluation is introduced as a new update to the Python ecosystem.
Python 3.14 solves everything because type hints are safely stored as strings and are only evaluated when a tool explicitly requests them.
This change eliminates the need to wrap types in quotes (e.g., item: ‘Item’) or use the old from __future__ import annotations just to solve ordering problems.
While there are many more upgrades, we think the ones covered above are some of the most relevant.
👉 Over to you: Did we miss something important?
[Recap] 8 RAG architectures AI engineers should know
We prepared the following visual that details 8 types of RAG architectures used in AI systems:
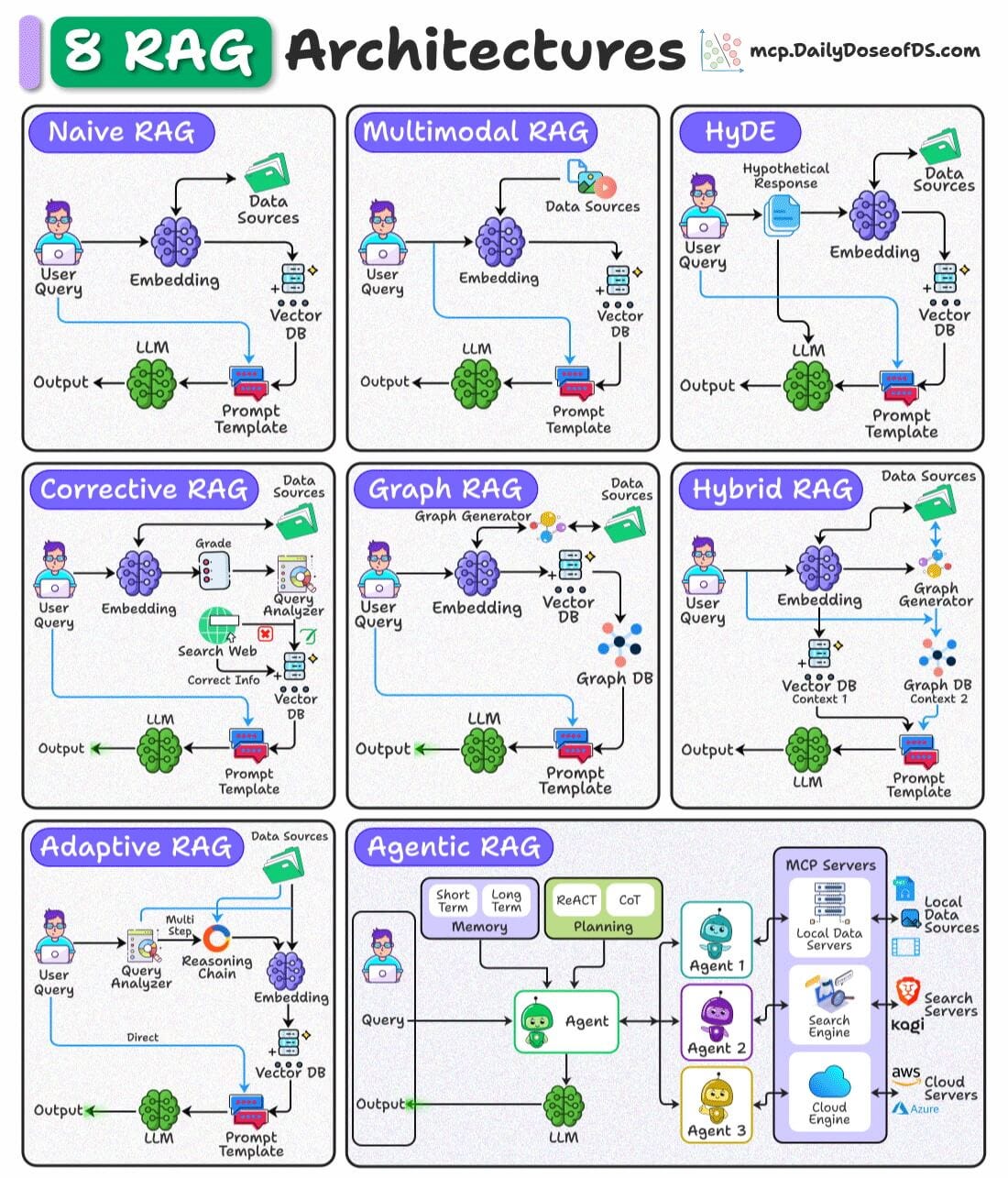
Let’s discuss them briefly:
Retrieves documents purely based on vector similarity between the query embedding and stored embeddings.
Works best for simple, fact-based queries where direct semantic matching suffices.
Handles multiple data types (text, images, audio, etc.) by embedding and retrieving across modalities.
Ideal for cross-modal retrieval tasks like answering a text query with both text and image context.
Queries are not semantically similar to documents.
This technique generates a hypothetical answer document from the query before retrieval.
Uses this generated document’s embedding to find more relevant real documents.
Validates retrieved results by comparing them against trusted sources (e.g., web search).
Ensures up-to-date and accurate information, filtering or correcting retrieved content before passing to the LLM.
Converts retrieved content into a knowledge graph to capture relationships and entities.
Enhances reasoning by providing structured context alongside raw text to the LLM.
6) Hybrid RAG
Combines dense vector retrieval with graph-based retrieval in a single pipeline.
Useful when the task requires both unstructured text and structured relational data for richer answers.
7) Adaptive RAG
Dynamically decides if a query requires a simple direct retrieval or a multi-step reasoning chain.
Breaks complex queries into smaller sub-queries for better coverage and accuracy.
Uses AI agents with planning, reasoning (ReAct, CoT), and memory to orchestrate retrieval from multiple sources.
Best suited for complex workflows that require tool use, external APIs, or combining multiple RAG techniques.
We have covered several of these architectures with implementations in our RAG series to fully prepare you for building production-grade RAG systems:
👉 Over to you: Which RAG architecture do you use the most?
Thanks for reading!