
When is Random Splitting Fatal for ML Models?
Here's when to avoid it.

One thing we hear in almost all introductory ML lessons is to split the given data RANDOMLY into train and validation sets.
Random splitting makes sense because it ensures that the data is divided without any bias.
However, I have come across many situations where random splitting is fatal for model building. Yet, many people don’t realize it.
And I am not talking about temporal datasets here.
Let me explain!
Scenario
Consider you are building a model that generates captions for images.

Due to the inherent nature of language, every image can have many different captions:

Now, you might realize what would happen if we randomly split this dataset into train and validation sets.
During the random split, the same data point (image) will be available in the train and validation sets.
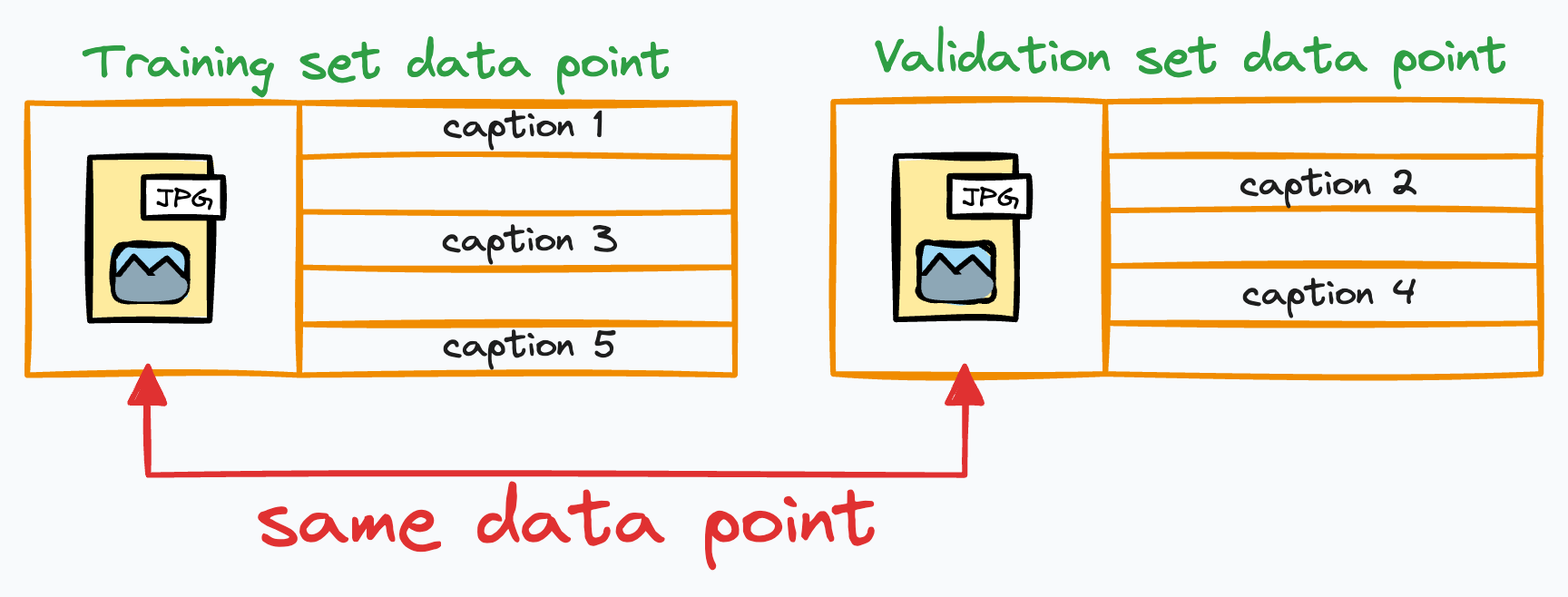
This is a typical example of data leakage, which results in high overfitting!
This type of leakage is also known as group leakage.
Solution
From the above discussion, it is clear that random splitting is the cause of the problem.
Group shuffle split helps us solve this.
There are two steps:
Group all training instances corresponding to one image (or features that may result in leakage, any other grouping criteria, etc.).
After grouping, the whole group must be randomly sent to either the training set or the validation set.

This will prevent the group leakage we witnessed earlier and prevent overfitting.
One thing to note here is that in the above example, all features in the dataset, i.e., the image pixels, contributed to the grouping criteria.
But more generally speaking, there could only be a subset of features that must be grouped together for data splitting.
For instance, consider a dataset containing medical imaging data. Each sample consists of multiple images (e.g., different views of the same patient’s body part), and the model is intended to detect the severity of a disease.
In this case, it is crucial to group all images corresponding to the same patient together and then perform data splitting. Otherwise, it will result in data leakage and the model will not generalize well to new patients.
Demo
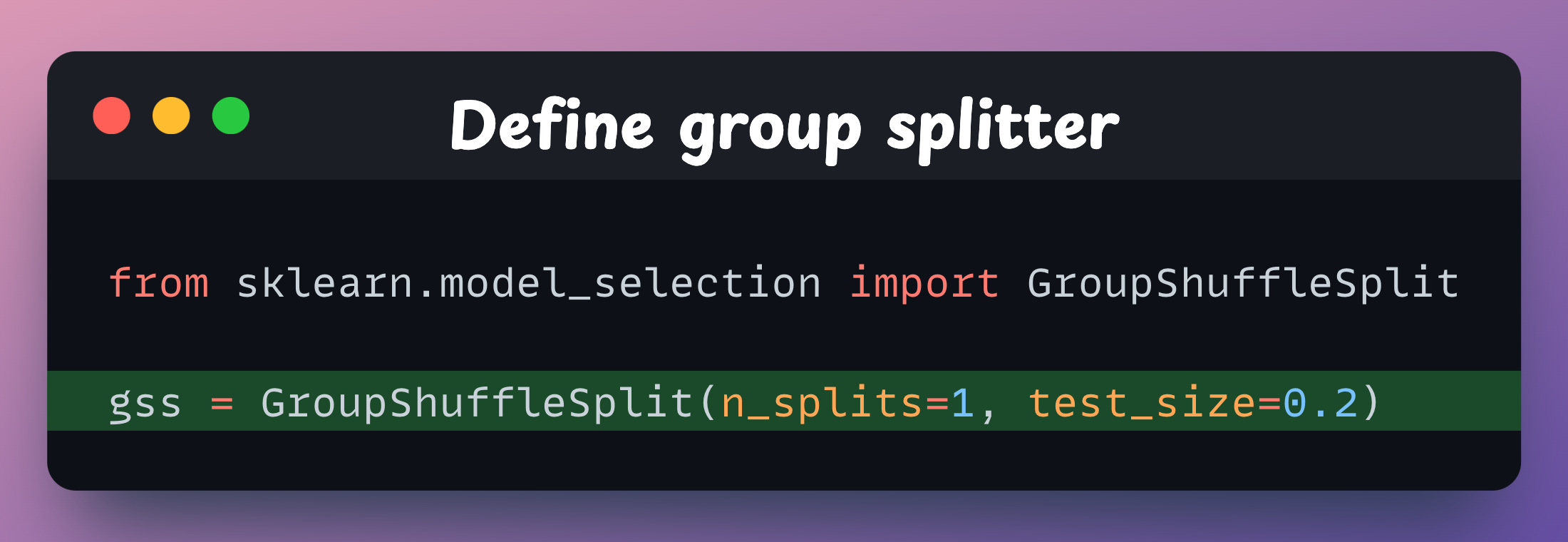
If you use Sklearn, the GroupShuffleSplit implements this idea.

Consider we have the following dataset:

x1andx2are the features.yis the target variable.groupdenotes the grouping criteria.
First, we import the GroupShuffleSplit from sklearn and instantiate the object:
The split() method of this object lets us perform group splitting:

This returns a generator, and we can unpack it to get the following output:

As demonstrated above:
The data points in groups “A” and “C” are together in the training set.
The data points in group “B” are together in the validation/test set.
Other than the above technique, I discussed 11 more high-utility techniques in a recent article here: 11 Powerful Techniques To Supercharge Your ML Models.
👉 Over to you: What are some other ways data leakage may kick in?
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
i think stratify is also similiar right? but does group split make sure the distribution uniformity?
Nice blog avi bro. I have a small doubt that what should we pass as group parameter? Also instead of group shuffle split, can we divide the whole dataset into train test and valid and make pipelines for avoiding the data leakage ( I'm saying by considering the tabular data) ? Will that technique works well for image data??