
Where Did the GPU Memory Go?
Estimating memory consumption of GPT models.

SambaNova Cloud: 10x faster alternative to GPUs for LLM Inference →
The entire Llama-3 family was a massive deal for open-source AI development.
However, GPUs were not built for large-scale inferences at this scale. This limited their true potential in Llama-3 in production systems.
SambaNova solved this by providing the world’s fastest AI inference using its specialized hardware stack (RDUs)—a 10x faster alternative to GPU.
Steps:
Select the model from the dashboard:

Next, you can integrate inference in your LLM apps with SambaNova Cloud using its Llama-index integration as follows:

Done!
Start using SambaNova’s fastest inference engine here →
Thanks to SambaNova for showing us their inference engine and partnering with us on today's newsletter.
Where Did the GPU Memory Go?
Continuing our discussion from SambaNova, consider this:
GPT-2 (XL) has 1.5 Billion parameters, and its parameters consume ~3GB of memory in 16-bit precision.
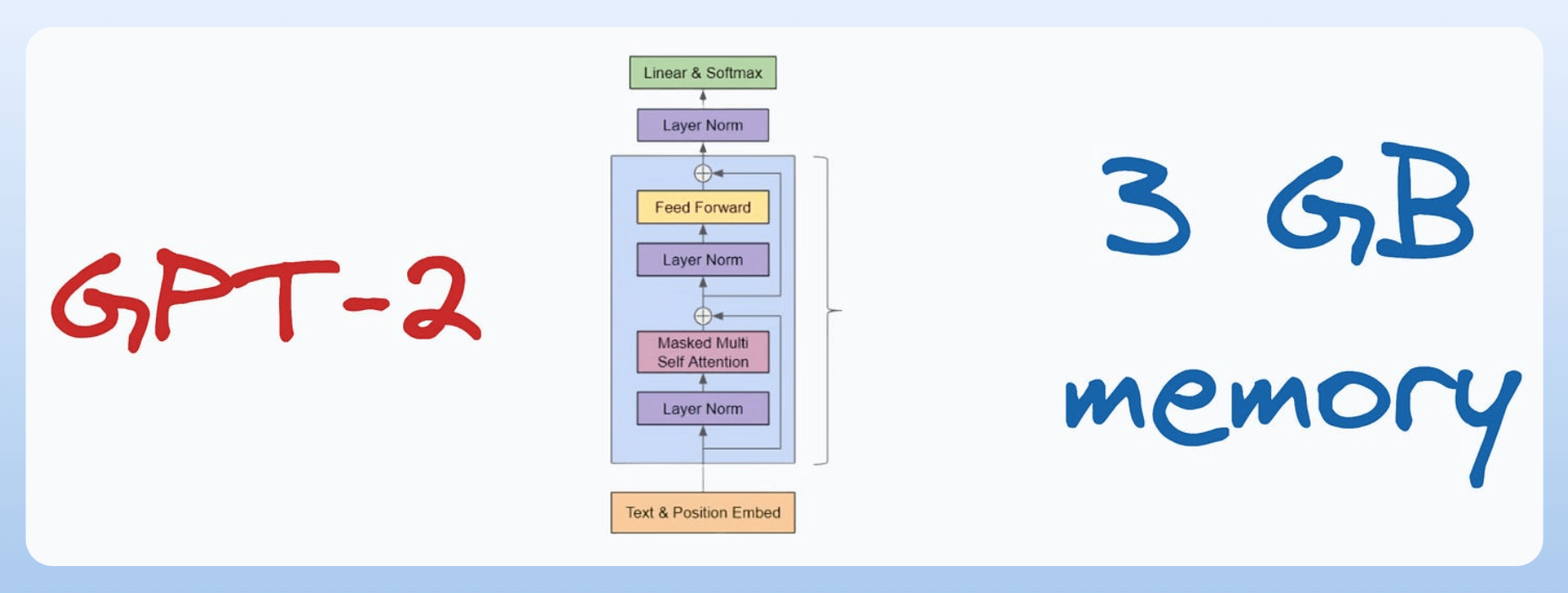
However, one can barely train a 3GB GPT-2 model on a single GPU with 32GB of memory.
Let’s do the memory computation today to understand this.
#1) Optimizer states, gradients, and parameter memory
Mixed precision training is widely used to speed up model training, where we utilize lower-precision float16 along with float32.
Thus, if the model has Φ parameters, then:
Weights consume 2*Φ bytes.
Gradients consume 2*Φ bytes.
Here, the figure “2” represents a memory consumption of 2 bytes/paramter (16-bit).
Moreover, the updates at the end of the backward propagation (step 7 below) are performed under 32-bit for effective computation, which leads to another 4*Φ bytes for model parameters.
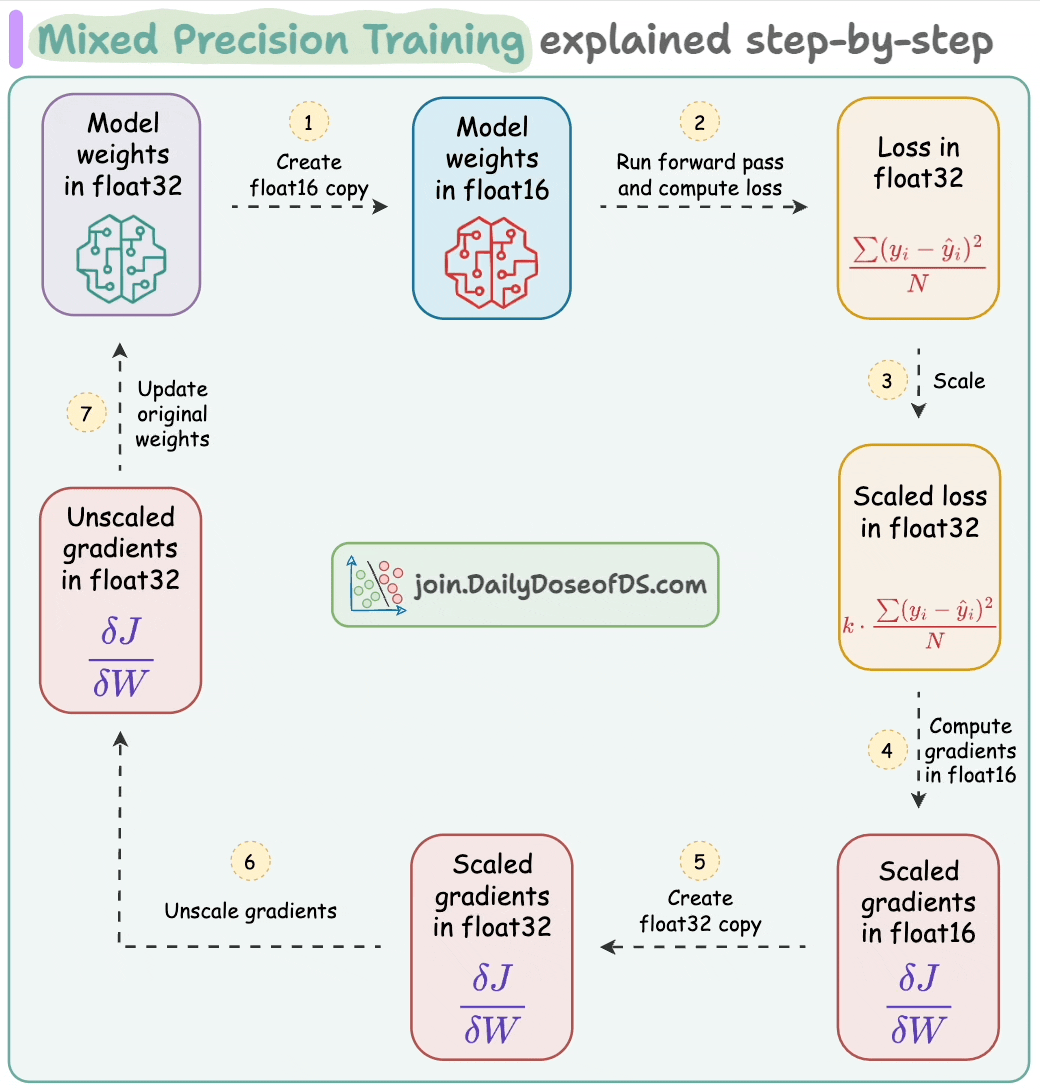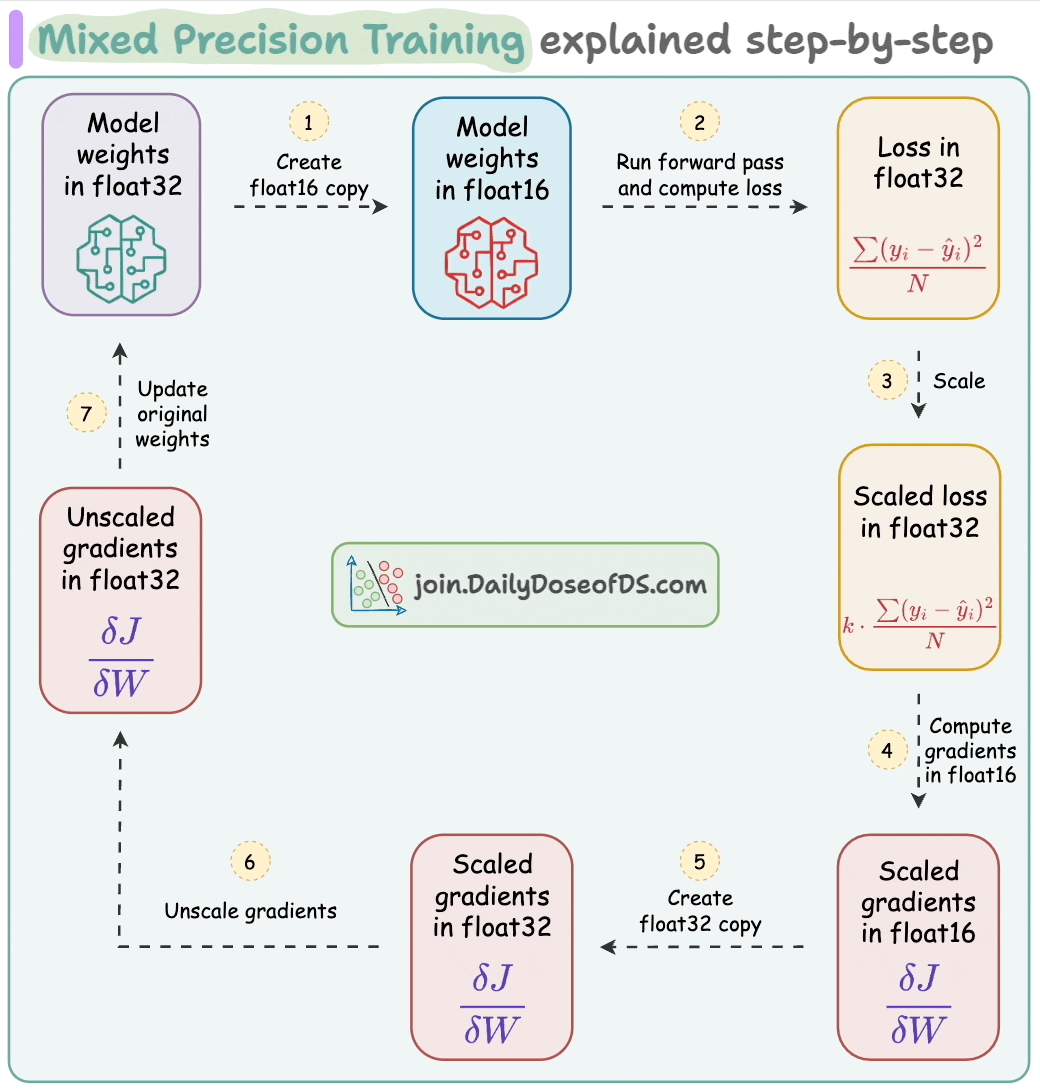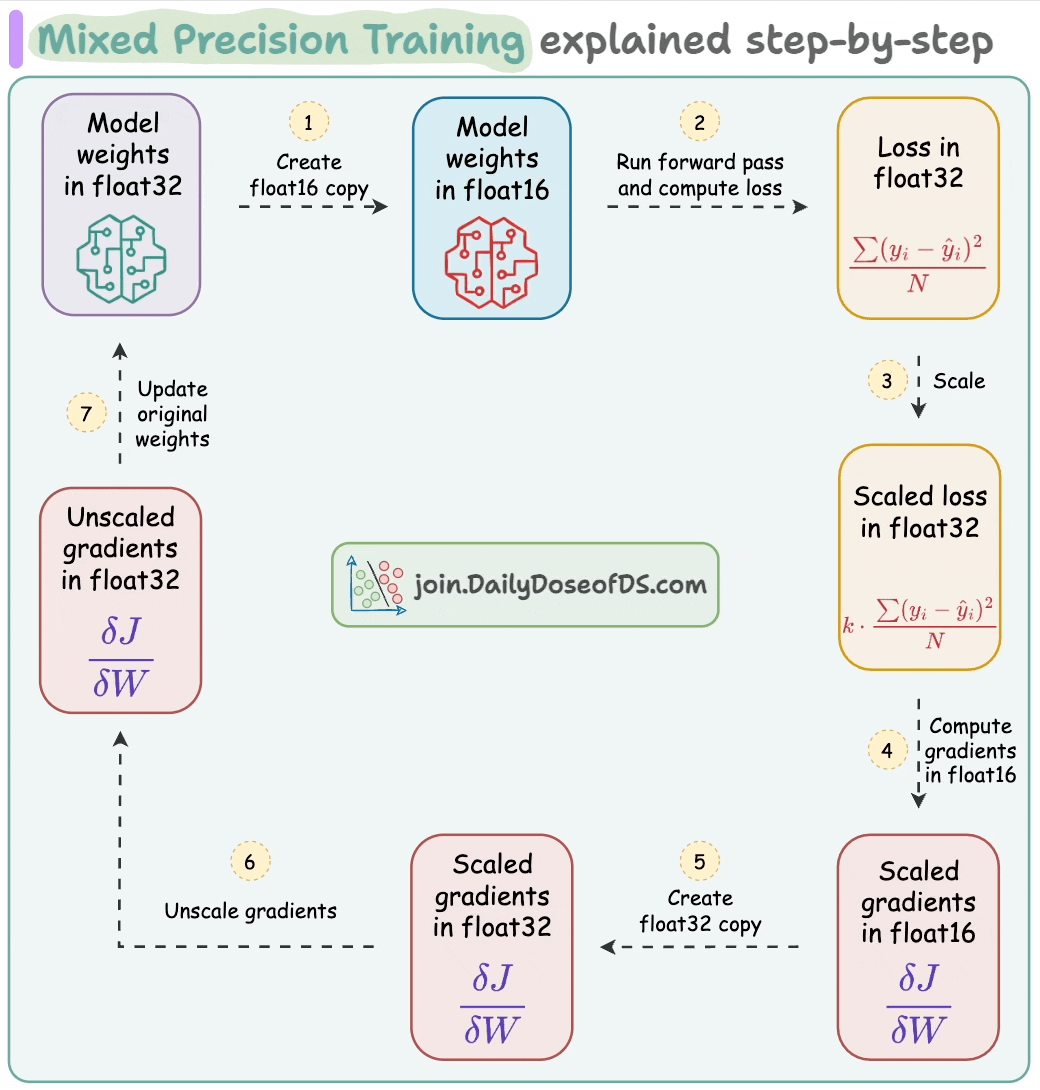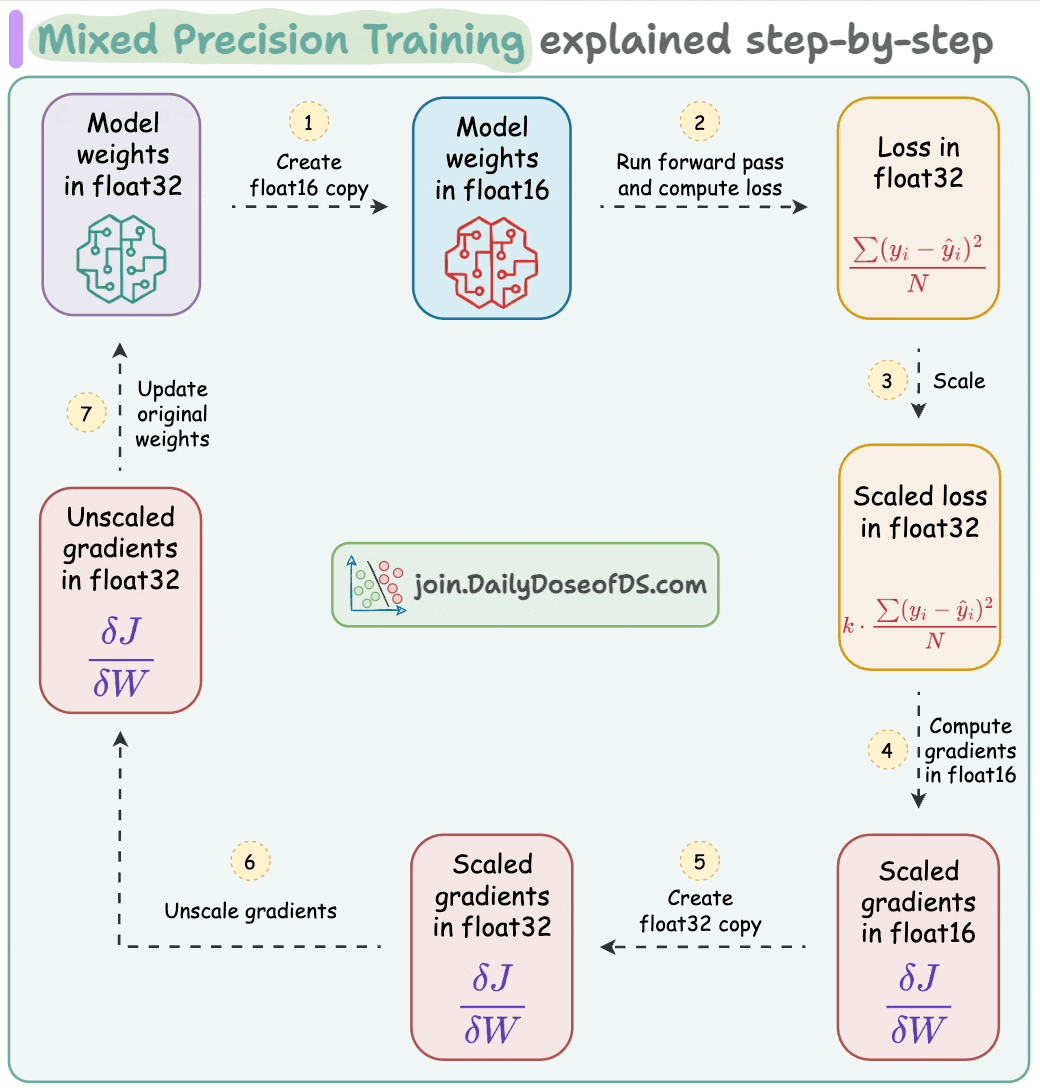
Lastly, the Adam itself stores two optimizer states to compute the updates—momentum and variance of the gradients, both in 32-bit precision:

This means we further need:
4*Φ bytes for momentum.
Another 4*Φ bytes for variance.
Here, the figure “4” represents a memory consumption of 4 bytes/paramter (32-bit).
Let’s sum them up:

That’s 16*Φ, or 24GB of memory.
#2) Activations
The total number of activations computed in one transform block of GPT-2 are:

Thus, across all transformer blocks, this comes out to be:

Plugging in the values for GPT2-XL, we get:

This totals ~30B activations. As each activation is represented in 16-bit, all activations consume 60GB of memory.
With techniques like activation checkpointing (we discussed it here with implementation), this could be brought down to about 8-9GB at the expense of 25-30% more run-time.
Our current memory consumption stands close to 32-35 GB.
#3) Other overheads
Memory fragmentation is another issue which produces unused gaps between allocated memory blocks:

Due to this, the memory allocation requests fail because of the unavailability of contiguous memory blocks.
About 5-15% of memory may go unutilized due to fragmentation.
Conclusion
The above discussion shows that one can barely train a ~3GB GPT-2 model with 36GB of GPU memory.
This will help you reflect on the inherent challenges of training even bigger LLMs.
Thus, even one additional layer leads to multiple GBs of additional memory requirement.
Multi-GPU training is at the forefront of these models, which we covered here: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, here’s an article that teaches CUDA programming from scratch: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming
👉 Over to you: What are some other challenges in building large deep learning models?