
Who Actually Builds AI Image Models (and Who Builds on Top)
The 2026 AI Image generation landscape.

Vibe train your AI agents
There’s a new method that could replace LLM-as-a-judge for production agents.
Most teams rely on a giant LLM as a judge to evaluate and guard their agent. But it has two major drawbacks:
It’s slow and expensive at inference time
It often misses domain-specific failures
Vibe training flips this.
Researchers at Plurai distilled a small language model that’s specialized for your agent’s exact use case. The SLM becomes your evaluator and your runtime guardrail, both in one.

The training data isn’t hand-curated either.
They spin up a swarm of adversarial agents that debate and stress-test every use case your agent is supposed to handle. That synthetic interaction data trains the specialized SLM.
So the judge actually understands what wrong looks like in your specific domain.
The reported gains vs. standard LLM-as-a-judge setups:
~8x faster inference
~50% fewer evaluation errors
Smaller, faster, and more accurate because it’s specialized for the job. The SLM-for-agents thesis is playing out in a very concrete way.
If LLM-as-a-judge is your current evaluation layer, this is worth benchmarking against.
And you can try it live here →
Thanks to Plurai for partnering today!
Who actually builds AI Image models
The AI image generation ecosystem runs only on about a dozen companies that train their own models from scratch.
Some build models and ship consumer products around them. Others build and distribute models as open weights or APIs without a consumer product. A growing group started as product companies and now trains their own models for control and differentiation. And a final layer routes requests across all of them.
That number has stayed roughly constant since early 2024, even as the total number of AI image products has exploded.
Training a frontier image model requires 800M+ image-text pairs, thousands of GPU-hours, and a research team iterating on diffusion or autoregressive architectures for months.
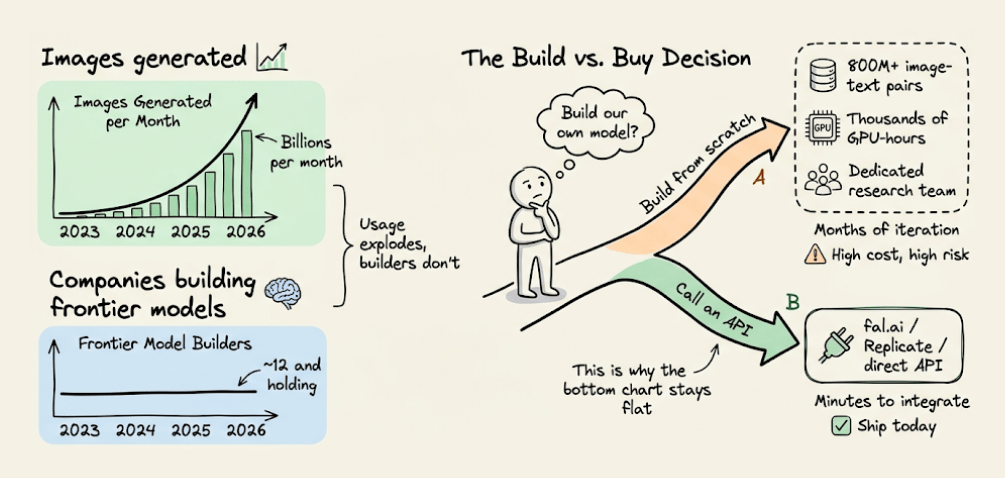
Most companies invoke an API instead. But which API you pick, and which layer of this stack your provider sits on, determines everything downstream, like your per-image cost, your latency budget, whether you can fine-tune for your use case, and how much you depend on someone else's roadmap.
This dynamic has produced a four-layer stack defined by a core distinction: whether a company owns the foundational model or builds on top of it.
This stack includes:
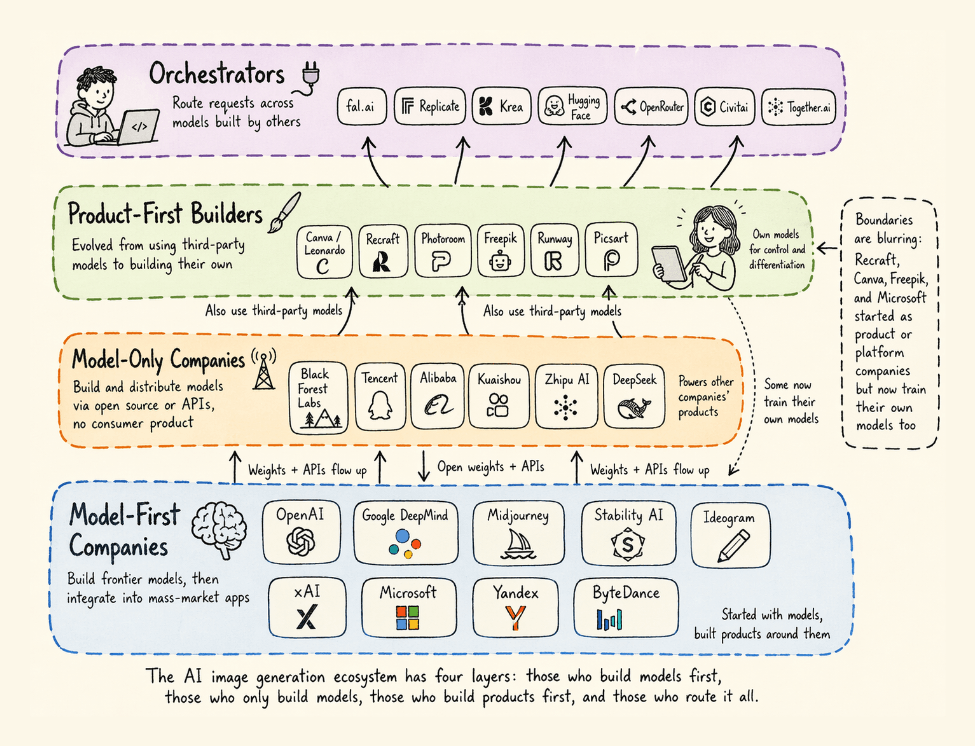
Model-first companies (frontier model builders that have integrated their models into mass-market apps)
Model-only companies that build and distribute foundational models via open source or APIs with no consumer product
Product-first builders, companies that evolved from using third-party tools to building their own models for control and differentiation
And finally, Orchestrators (platforms that provide convenient access and routing to models built by others).
Let’s walk through each layer, who the real players are, and where the boundaries are collapsing.

Four types of companies in AI image generation
1. Model‑first companies / frontier builders
These are companies that started with a foundational model (trained from scratch) and later integrated it into their own mass‑market user product.
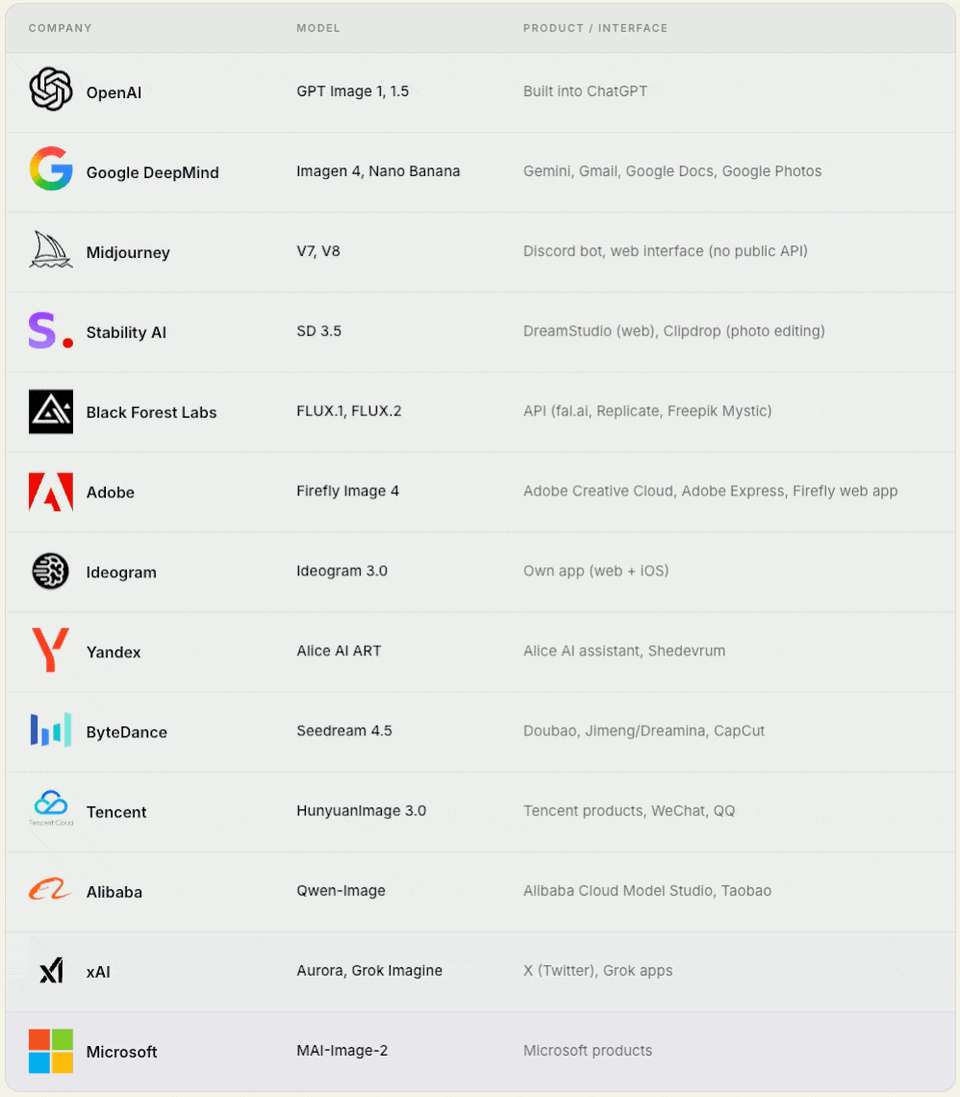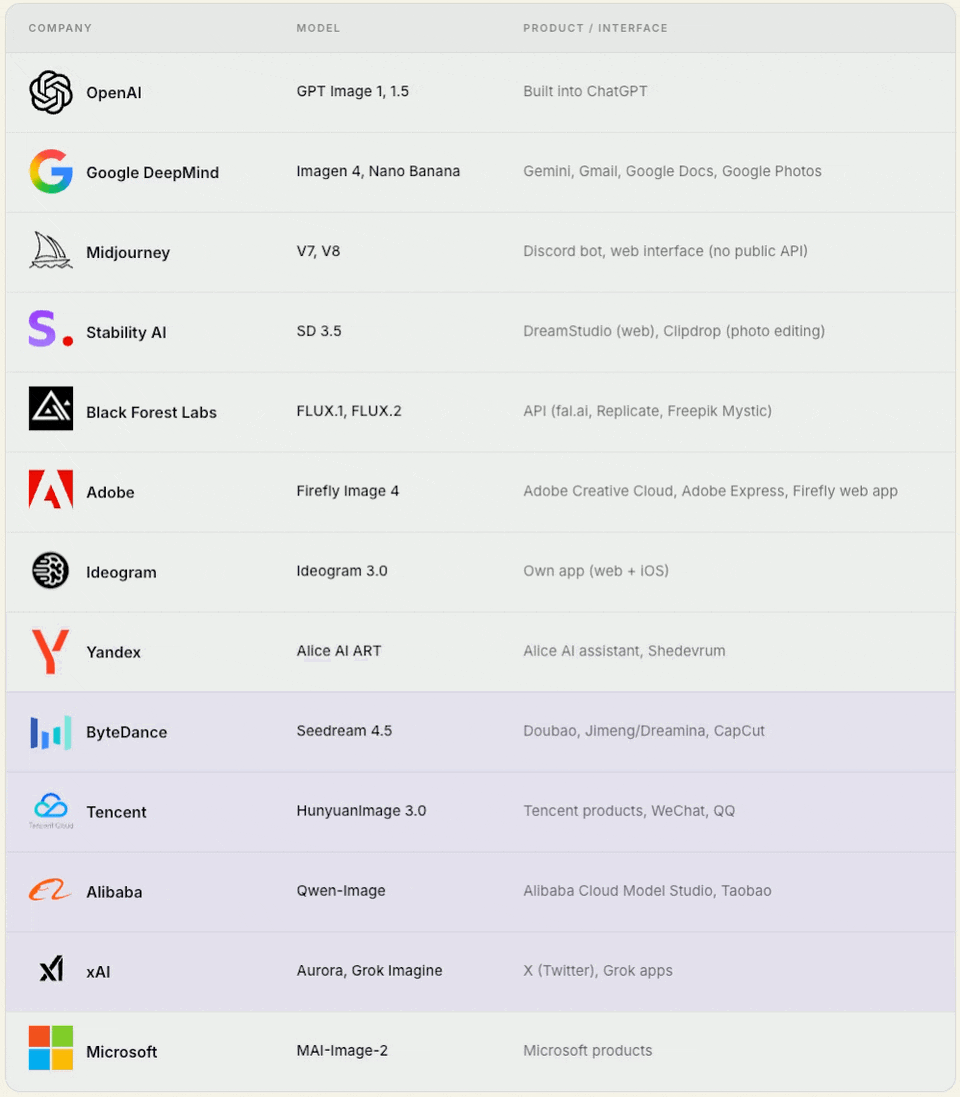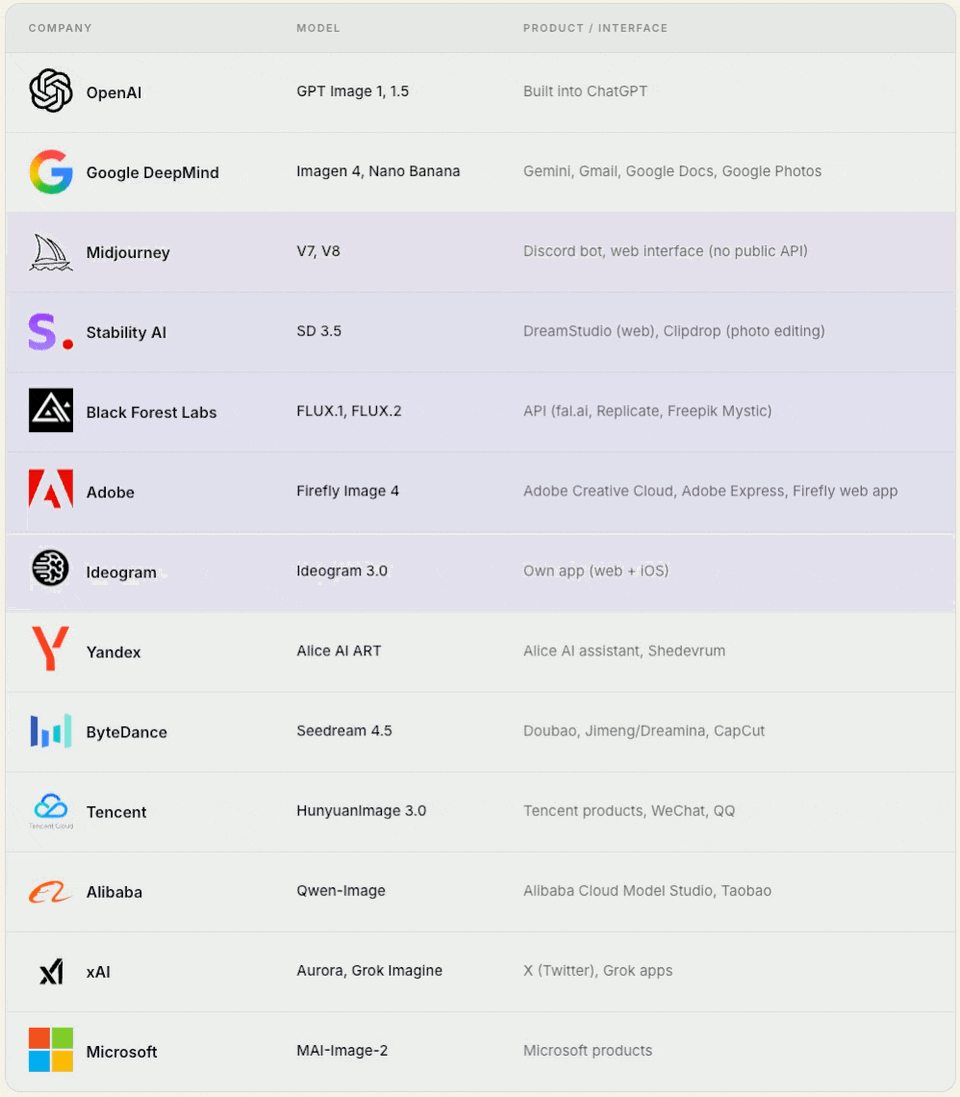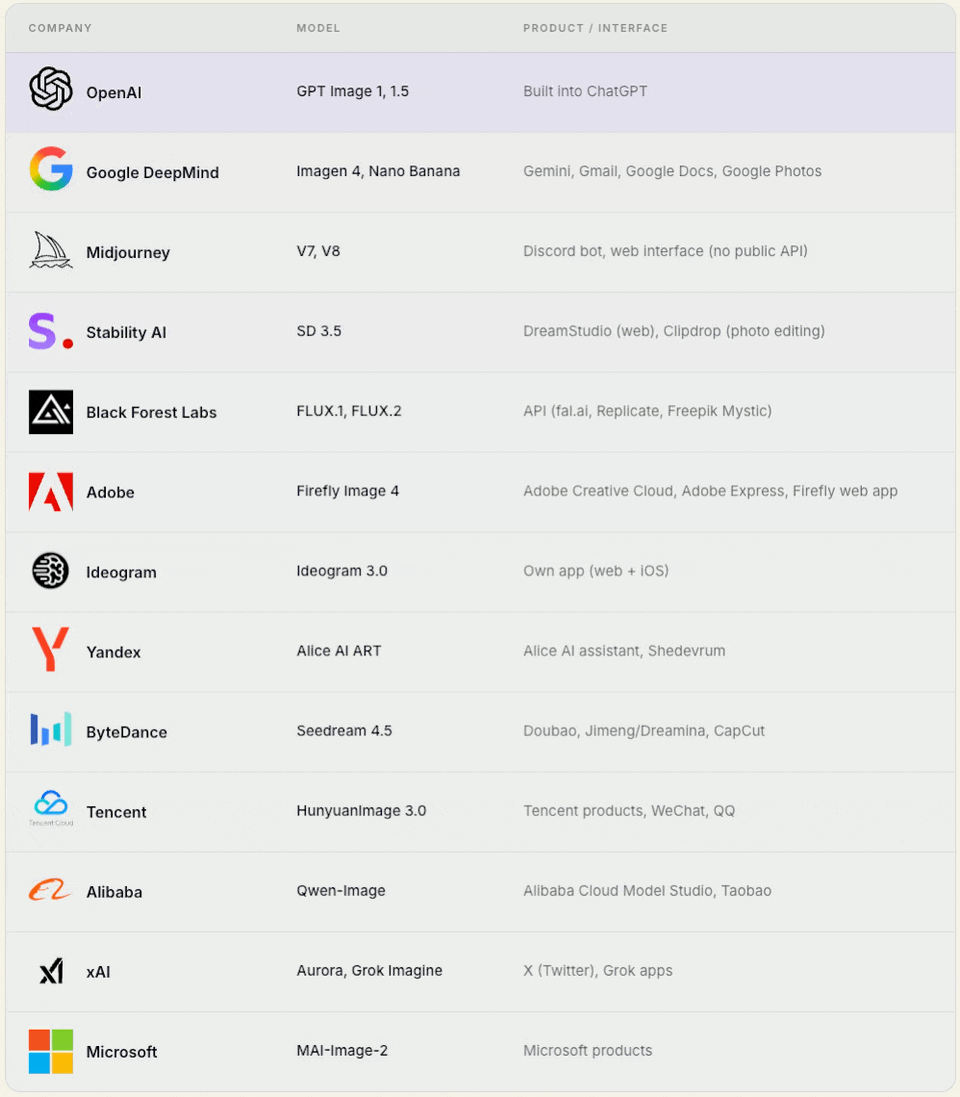
Note: Some of these companies offer API-based access to their models, but most users access them through their own mass-market products.
2. Model‑only companies / foundational contributors
These companies build foundational models from scratch but do not build a mass‑market product around them.
Their priority is making the model accessible to others via open weights, API, or commercial licensing.
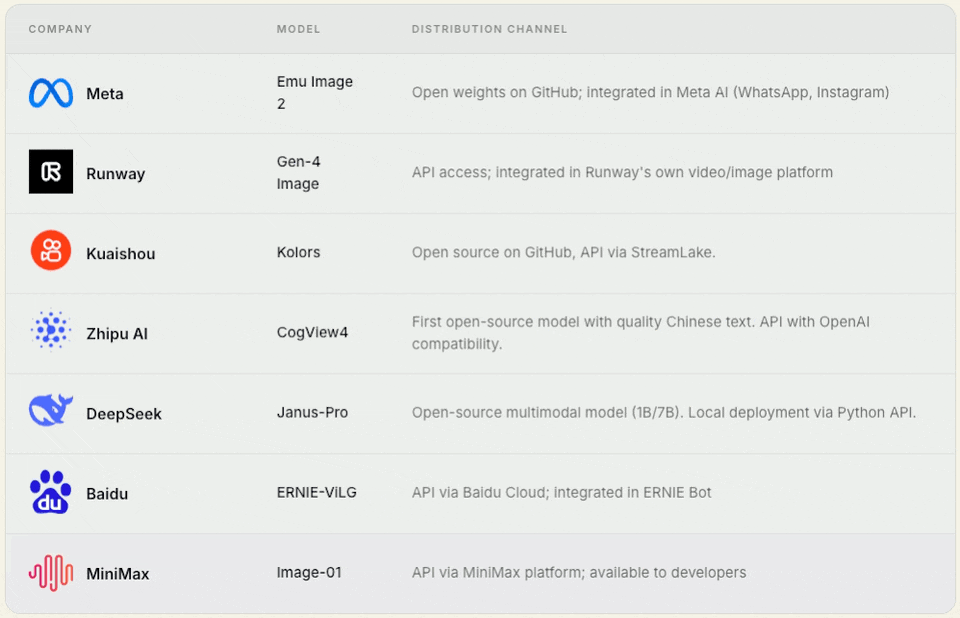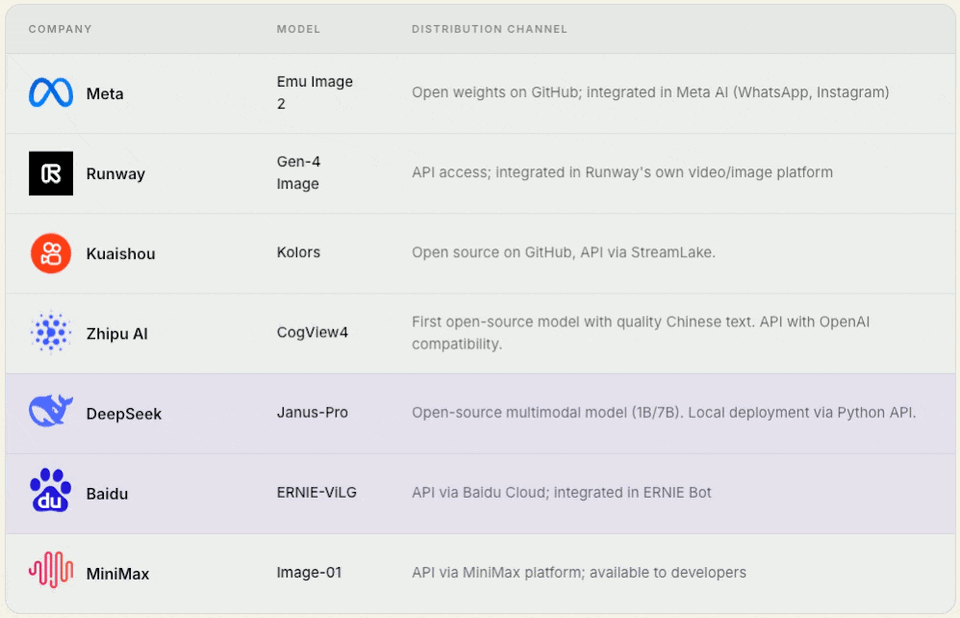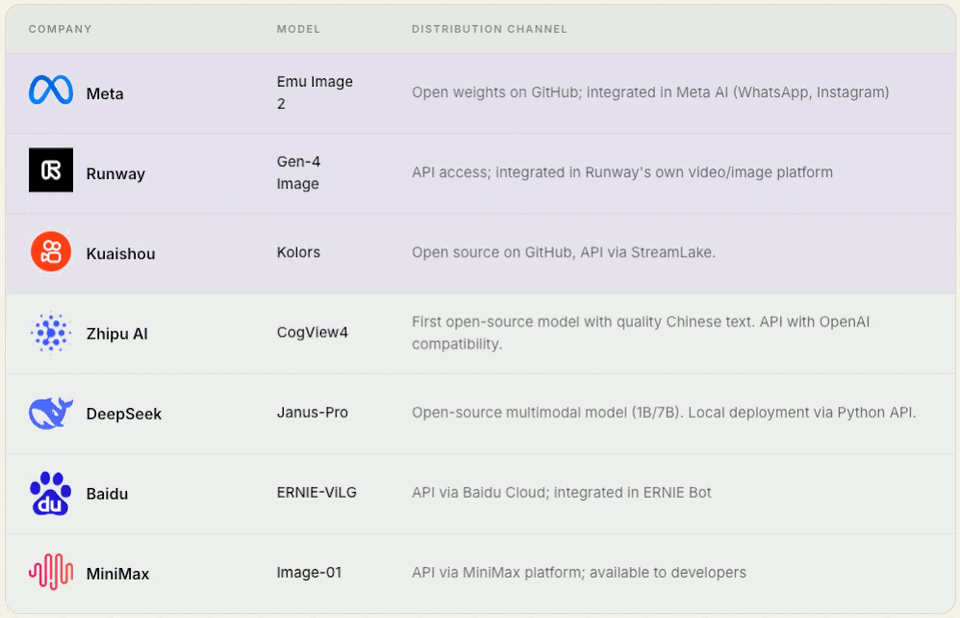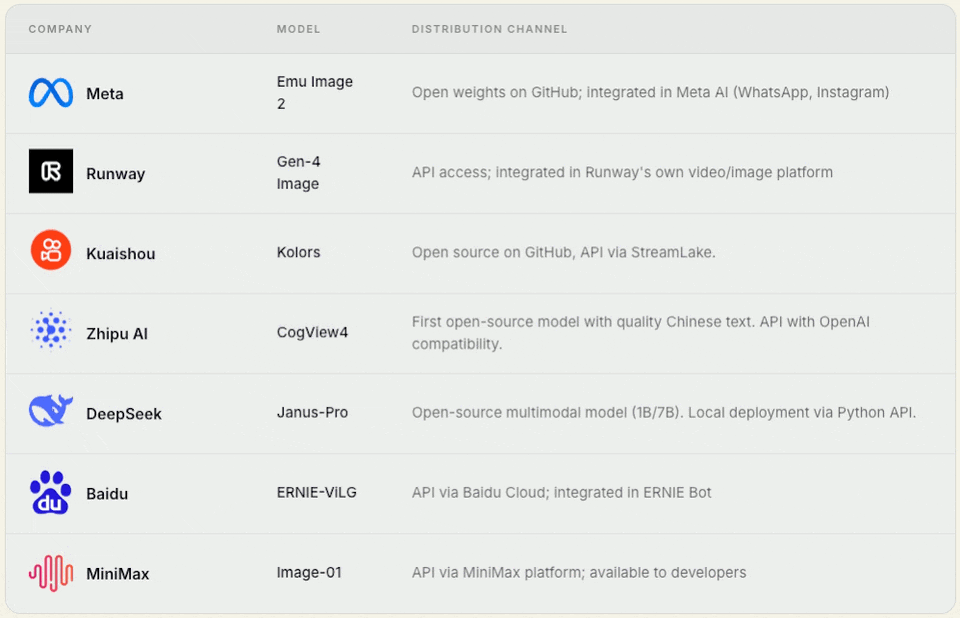
Some of these companies (Tencent, Alibaba) also have their own products. Still, their open‑source/API strategy is so significant that they belong here — their models live separately from their products.
3. Product-first builders
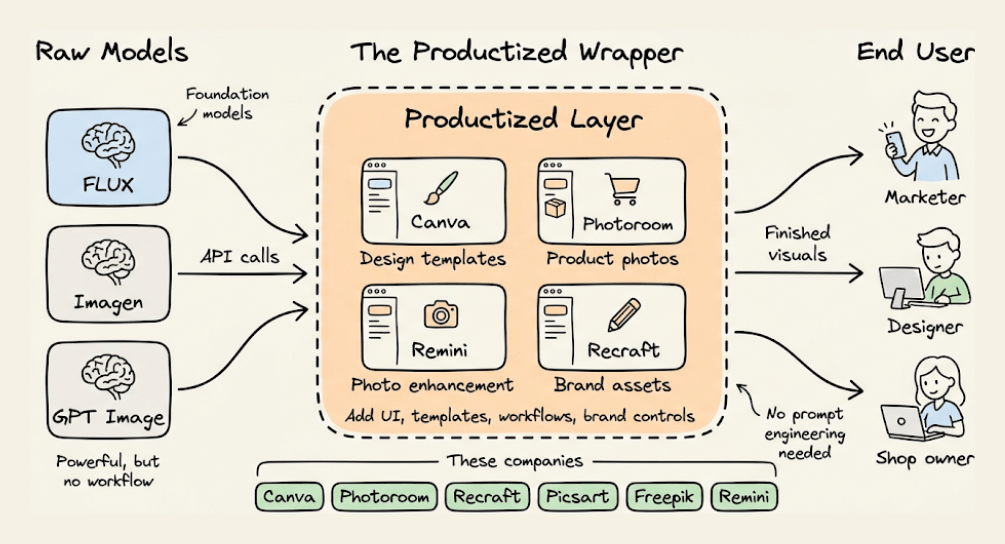
Companies that started as product solutions (design, e‑commerce, photo editing) using third‑party models, then realized they needed their own model to control quality, differentiation, and costs.
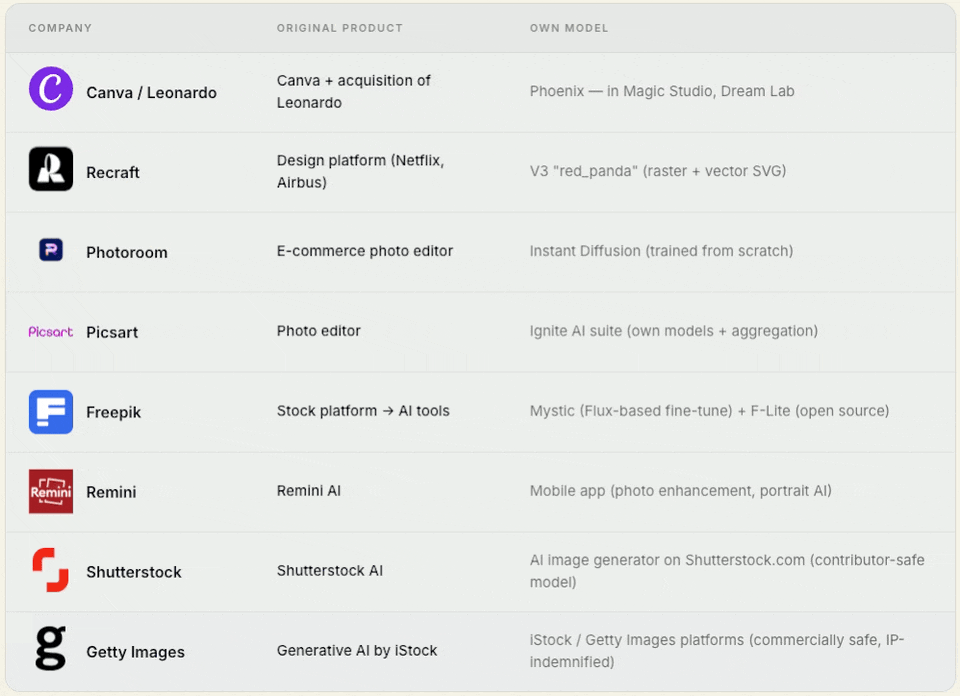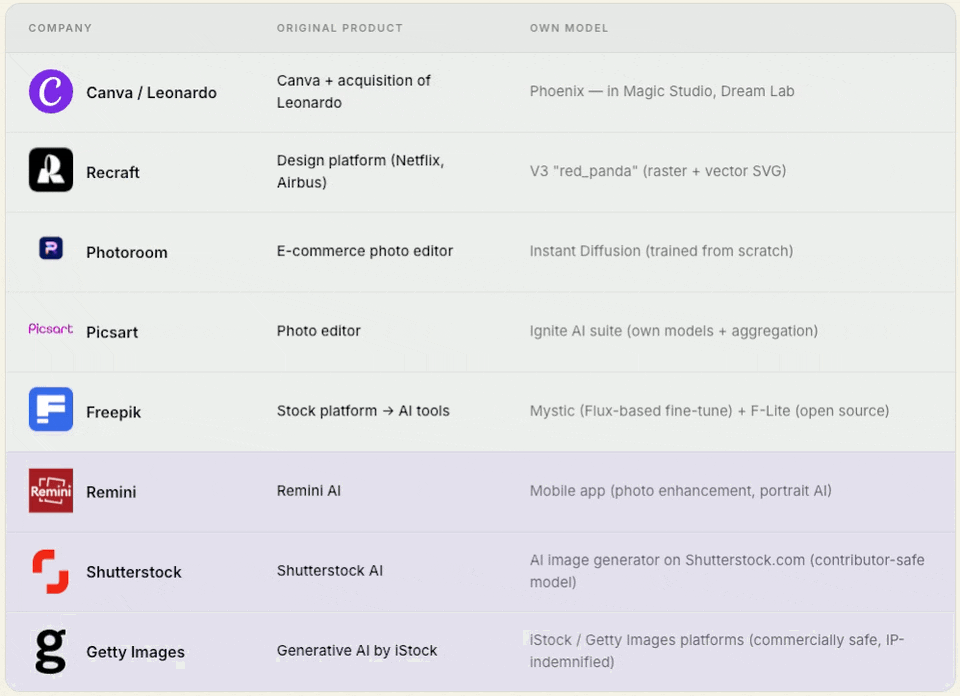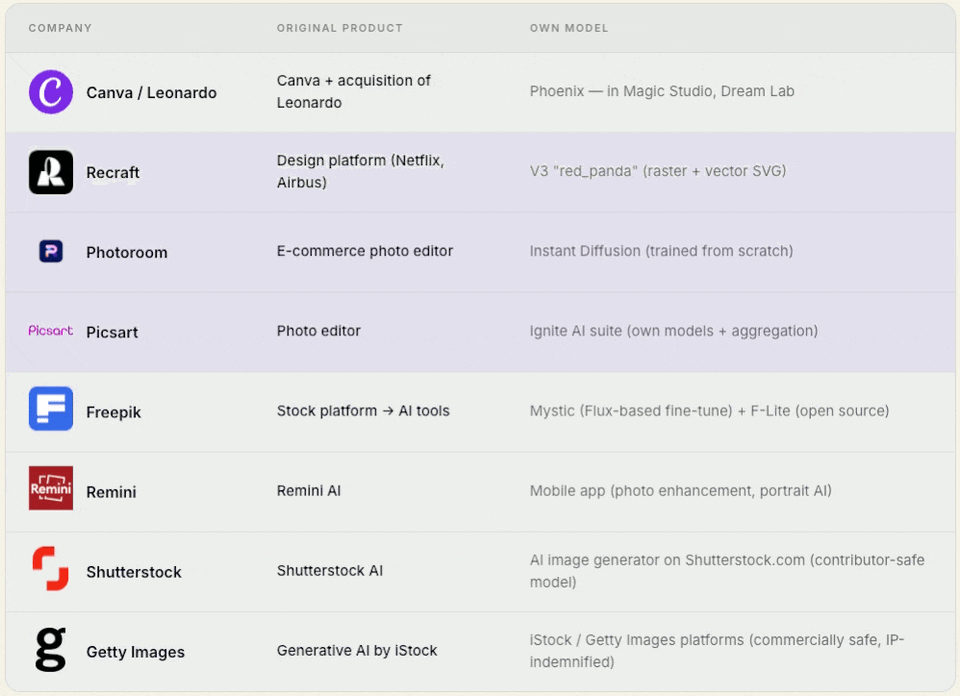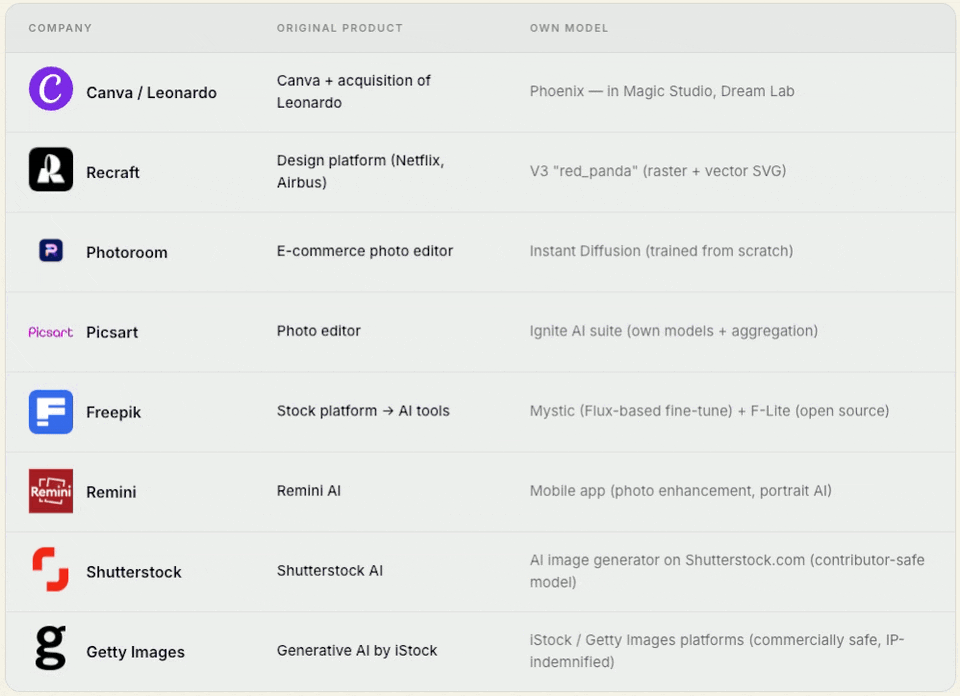
Today, they are full model builders.
4. Orchestrators/Inference platforms
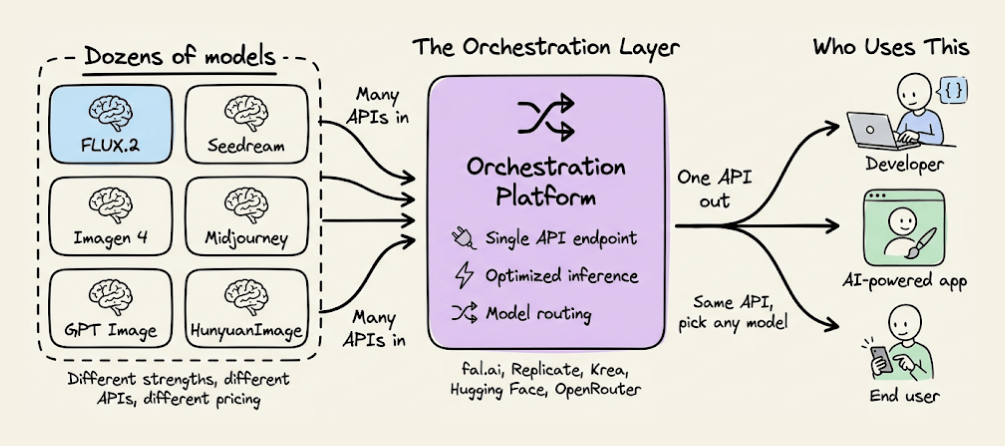
These companies do not train their own foundational models. They provide access to others’ models, unified APIs, interfaces, or hosting for fine-tuning. They create value through convenient access but do not control the model layer.

Hybrid case: Adobe Firefly
Adobe doesn’t fit into one category. It is simultaneously:
a model builder (Firefly Image Model 4 and Ultra, 18B+ assets, customization via Foundry),
An orchestrator because Firefly Boards let users pick Google Imagen 3, OpenAI GPT Image, and others alongside Adobe’s own models.
Adobe has strengthened its position by becoming both a model builder and a major orchestrator of AI models for the creative industry.
This is a unique hybrid showing where the market is heading.
Where does the value go long‑term?
If you own your own foundational model, trained from scratch (pretraining), you control:
your cost structure (no API bills),
your latency and deployment,
your differentiation (no one else has the same model),
your independence (no one can cut you off).
If you don’t own a model, you compete on UX, curation, or price, but you are always a tenant on someone else’s land.
Only about a dozen companies worldwide train their own models from scratch and produce mass-market products. The rest, hundreds of apps and platforms, are built on top of those.
That distinction, owning your model or not, remains the most important line on the map.
👉 Over to you: Do you think the product‑born model builders (Recraft, Canva) will eventually overtake the lab‑born ones (OpenAI, Midjourney)? Or does being a model‑first company still carry an unassailable advantage?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.