
Why Agent Crashes Are Nothing Like Database Crashes
...and Google's solution that handles them.

The operating system for AI research labs!
Transformer Lab is an open-source ML platform that orchestrates GPUs across any cloud and runs any training or eval workflow you define:
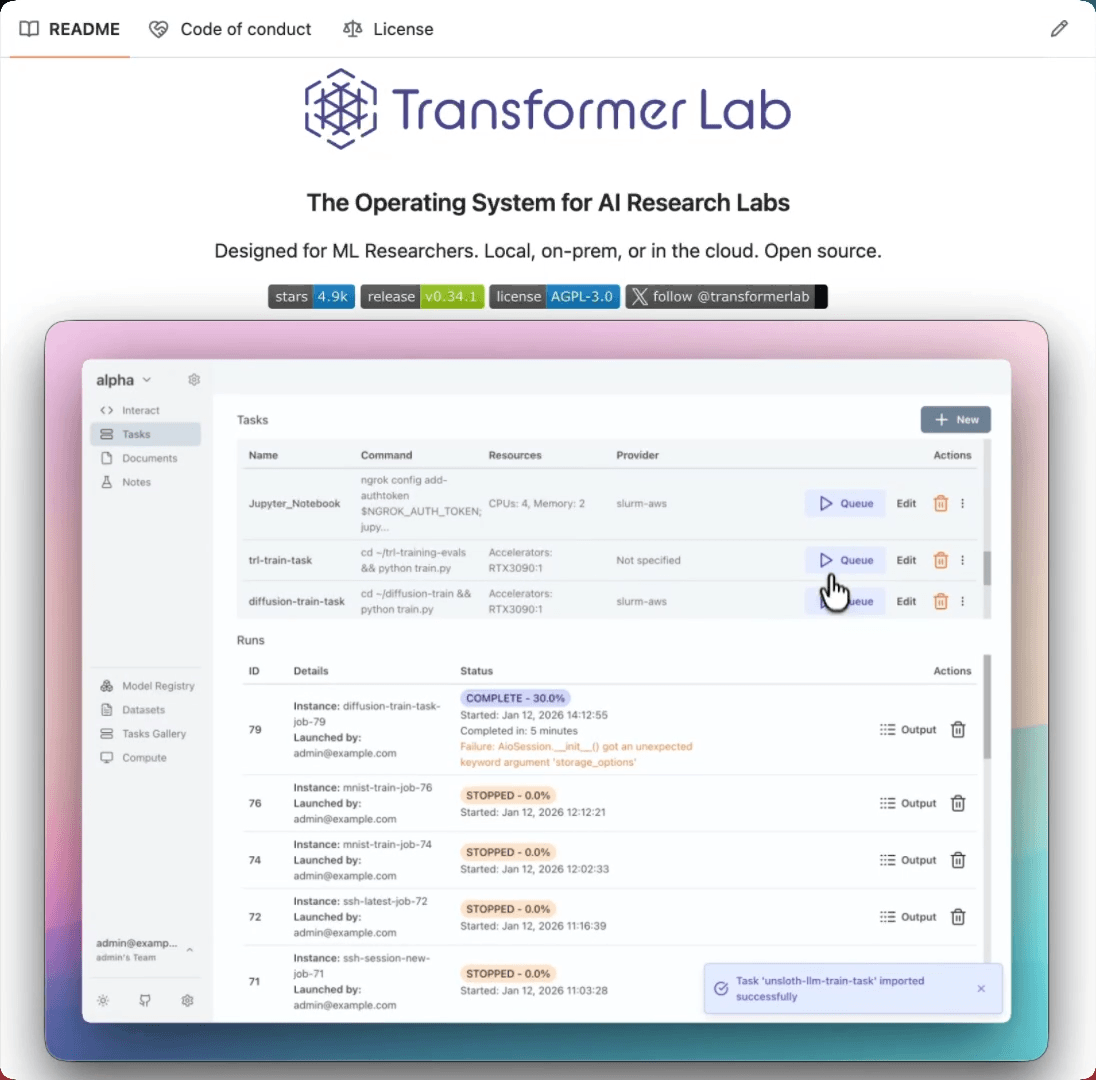
supports LoRA, QLoRA, DPO, ORPO, SIMPO
use it from a GUI, CLI, or agent skill.
works with MLX, vLLM, Ollama, and HF Transformers
one-click convert between HF, GGUF, and MLX
diffusion training and inference built in
LLM-as-a-judge evals plus the EleutherAI harness
submits jobs to Slurm and SkyPilot from the same UI
runs on Apple Silicon, NVIDIA, and AMD
The same interface a solo researcher uses on a MacBook also drives a 64-GPU cluster. Nothing else does that today.
Find the GitHub repo here → (don’t forget to star it ⭐️)
Why agent crashes are nothing like database crashes
When a database crashes and restarts, it replays the write-ahead log and reconstructs the exact same state, down to every transaction, row, and index entry.
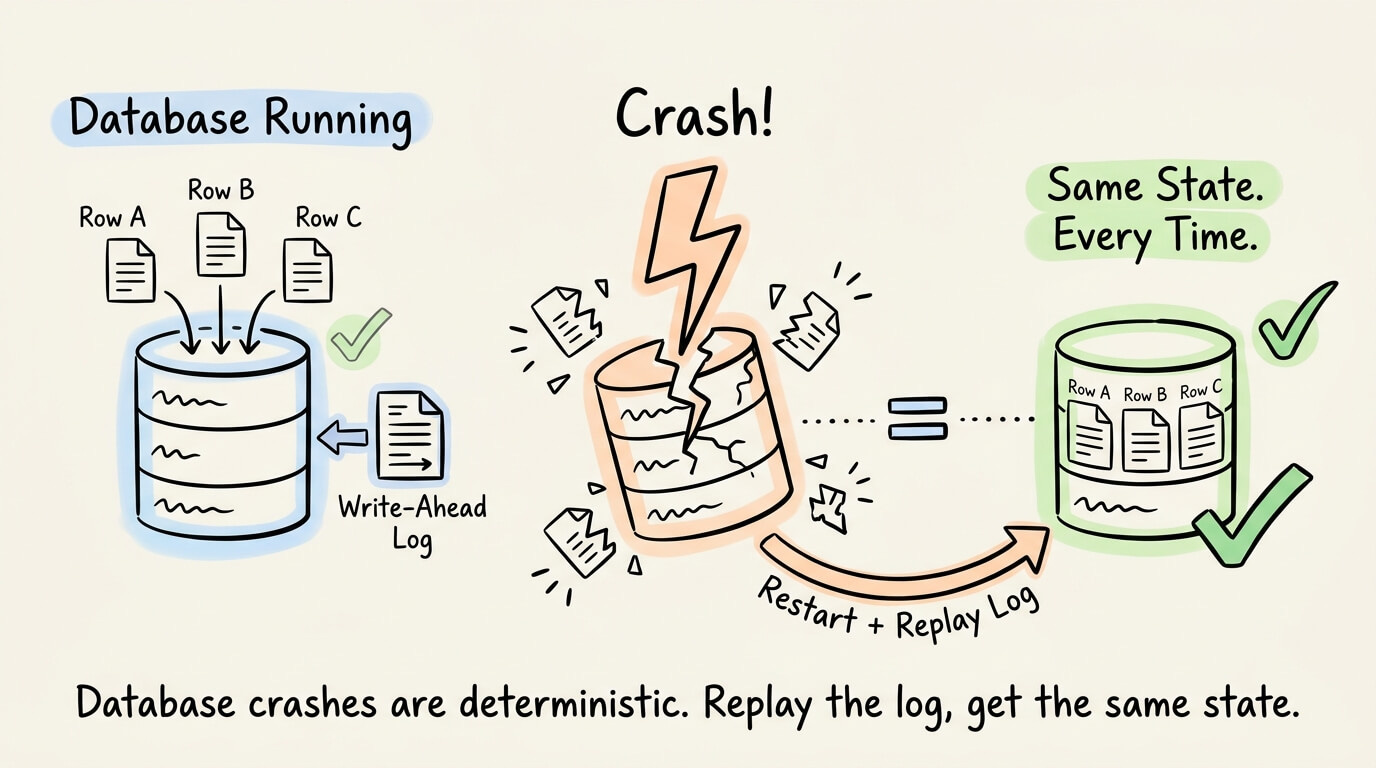
This deterministic recovery is a solved problem in databases and has been for decades.
Agent crashes don’t work this way, and just restarting it is not the ideal option.
Let’s dive in to understand the problem and also see how Google Cloud’s new Agent Platform has engineered the infra to solve it.
The decision drift problem
Consider an agent that processed financial records over five days.
On day 1, it ingested 4,000 records and normalized formats. One record has an ambiguous date field (“
03/04/2026”). The agent interprets it as March 4th. Every downstream decision, the cross-referencing on day 2, the anomaly detection on day 3, builds on that interpretation.On day 3, the agent crashes.
A stateless restart would involve re-ingesting all 4,000 records from scratch.
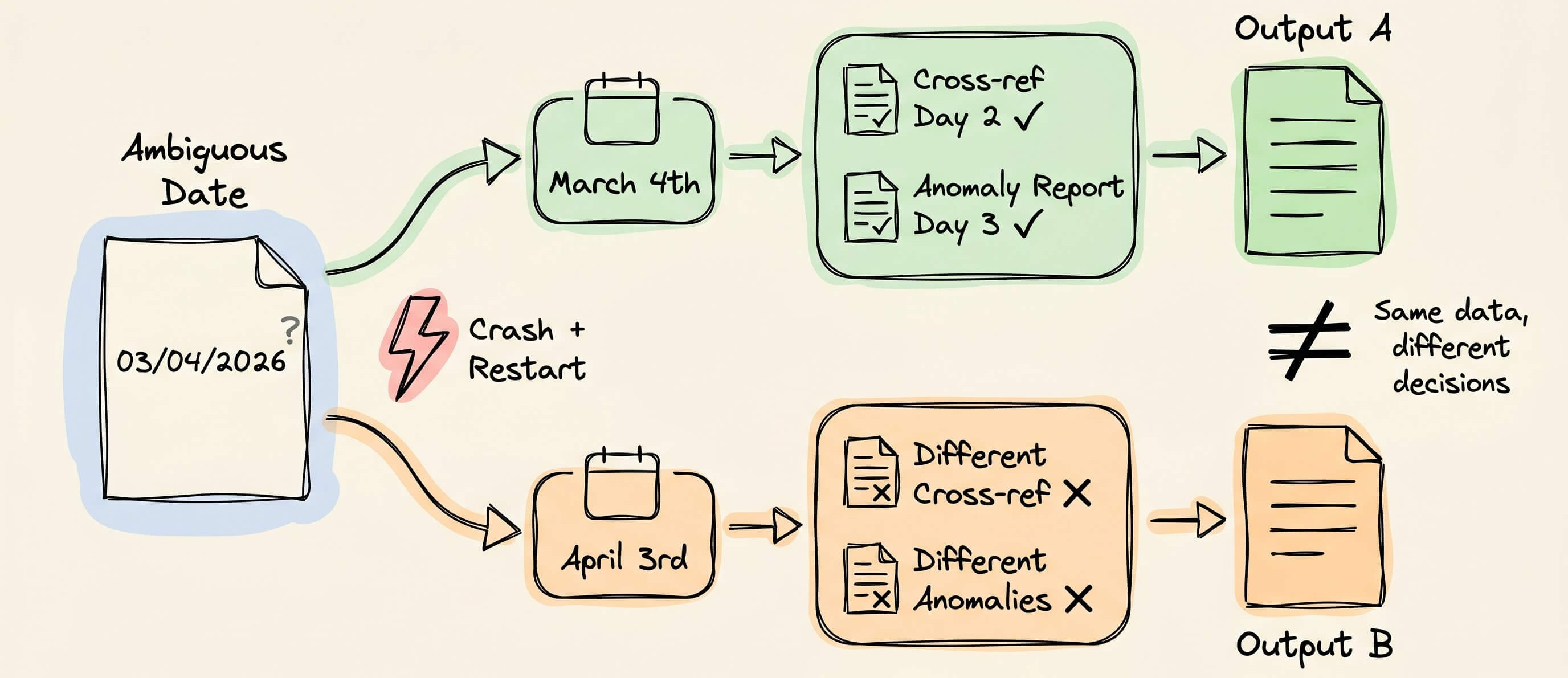
Now, the LLM may interpret that same ambiguous date as April 3rd.
That single different decision influences every subsequent step. This is what makes agent state fundamentally different from database state.
Checkpoint-and-resume strategy for Agents
The fix is conceptually simple.
The agent should periodically save its intermediate state, including progress, accumulated decisions, and the reasoning chain that led to them. If it crashes, it reloads the last checkpoint and continues with every prior decision intact.
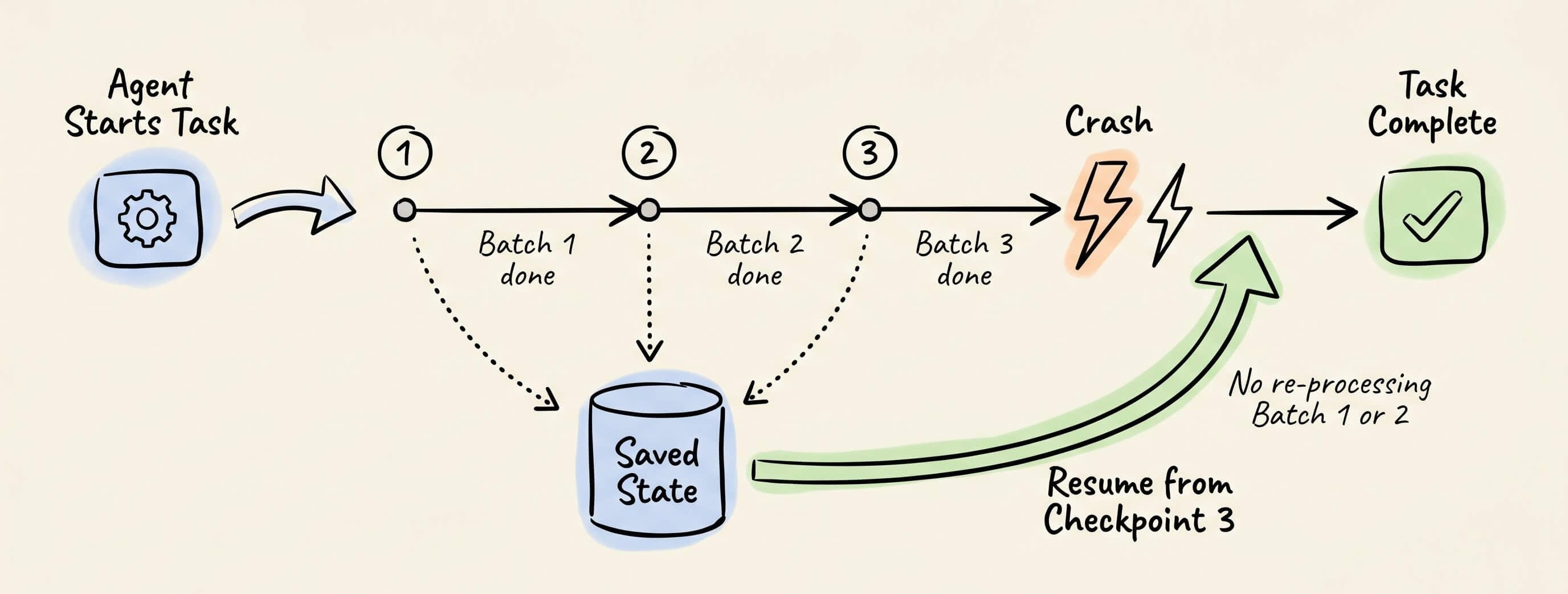
Technically, here’s what you’d need to do:
Implement persistent state serialization across sessions
Manage storage and retrieval
Reconstruct the agent’s full context window exactly as it was before the crash
Handle edge cases like human-in-the-loop approvals where the agent needs to pause indefinitely without consuming compute.
If you want to see it in practice, Google Cloud’s Agent Platform now actually ships this as a native platform capability through three mechanisms that work together.
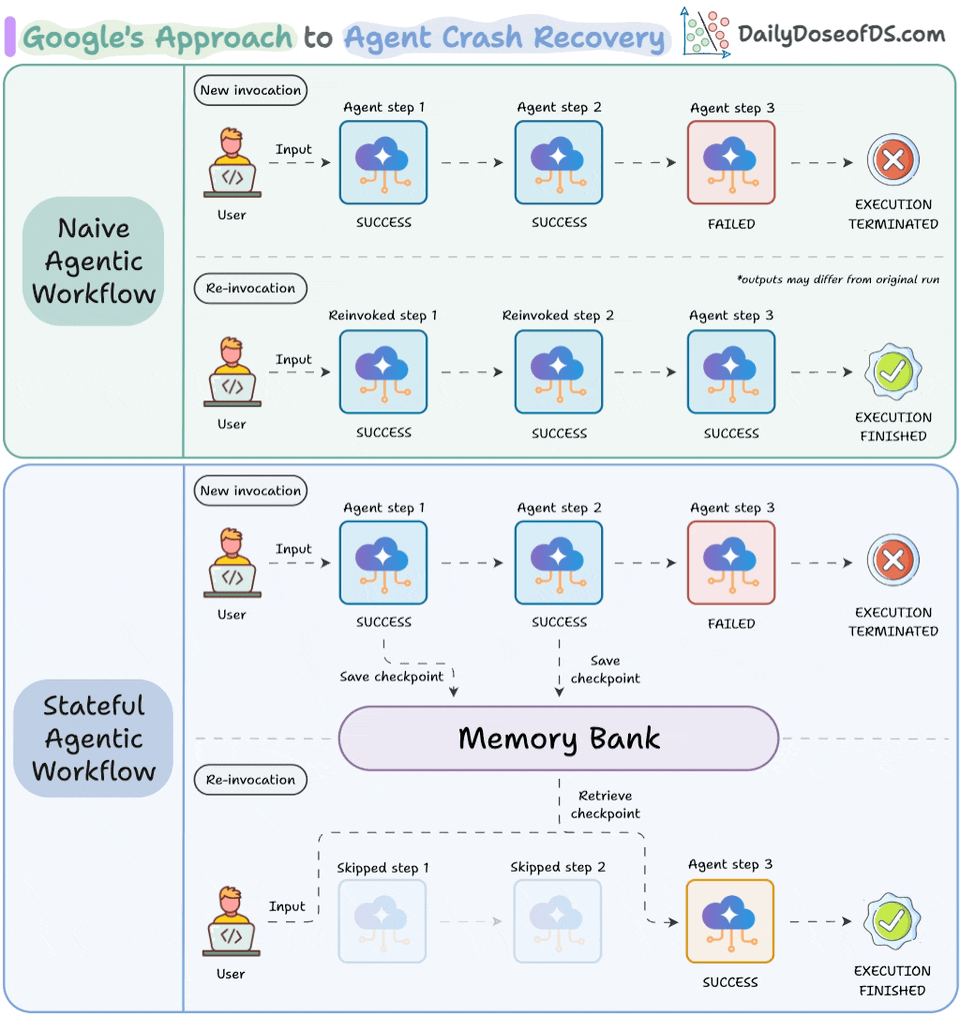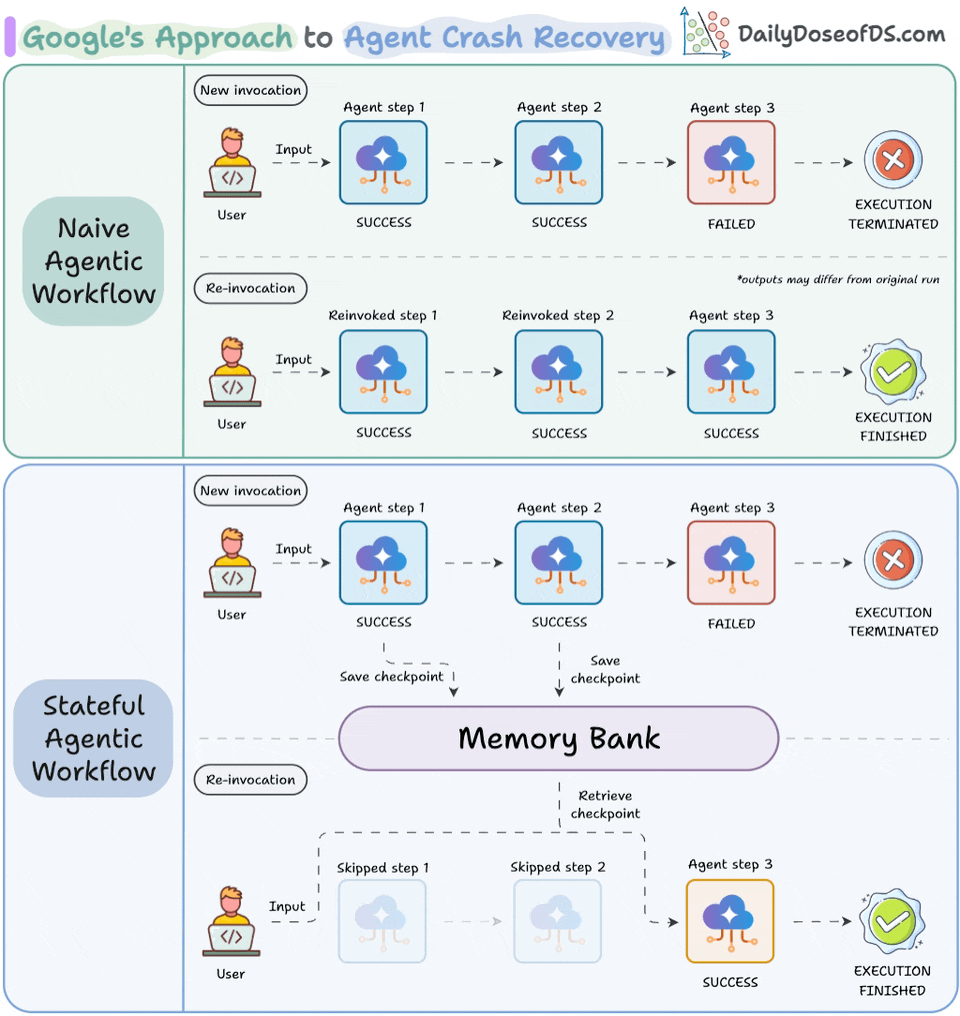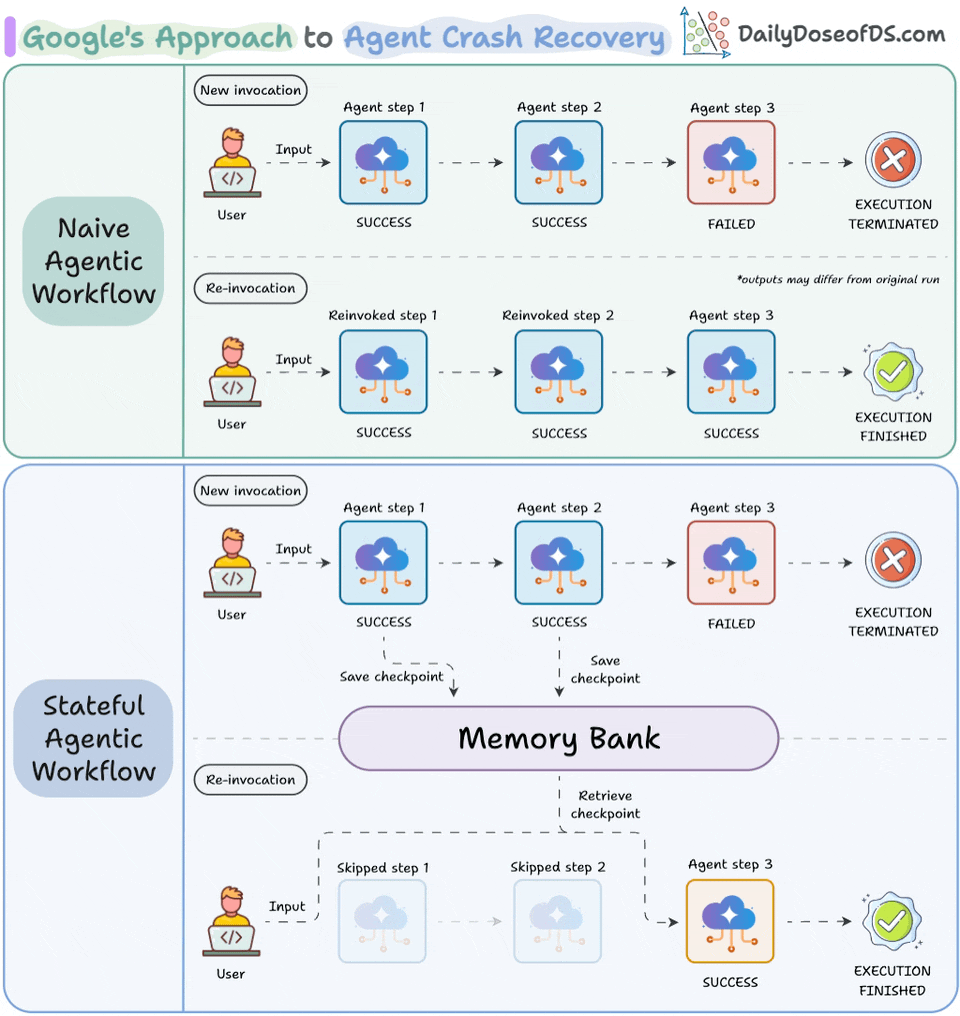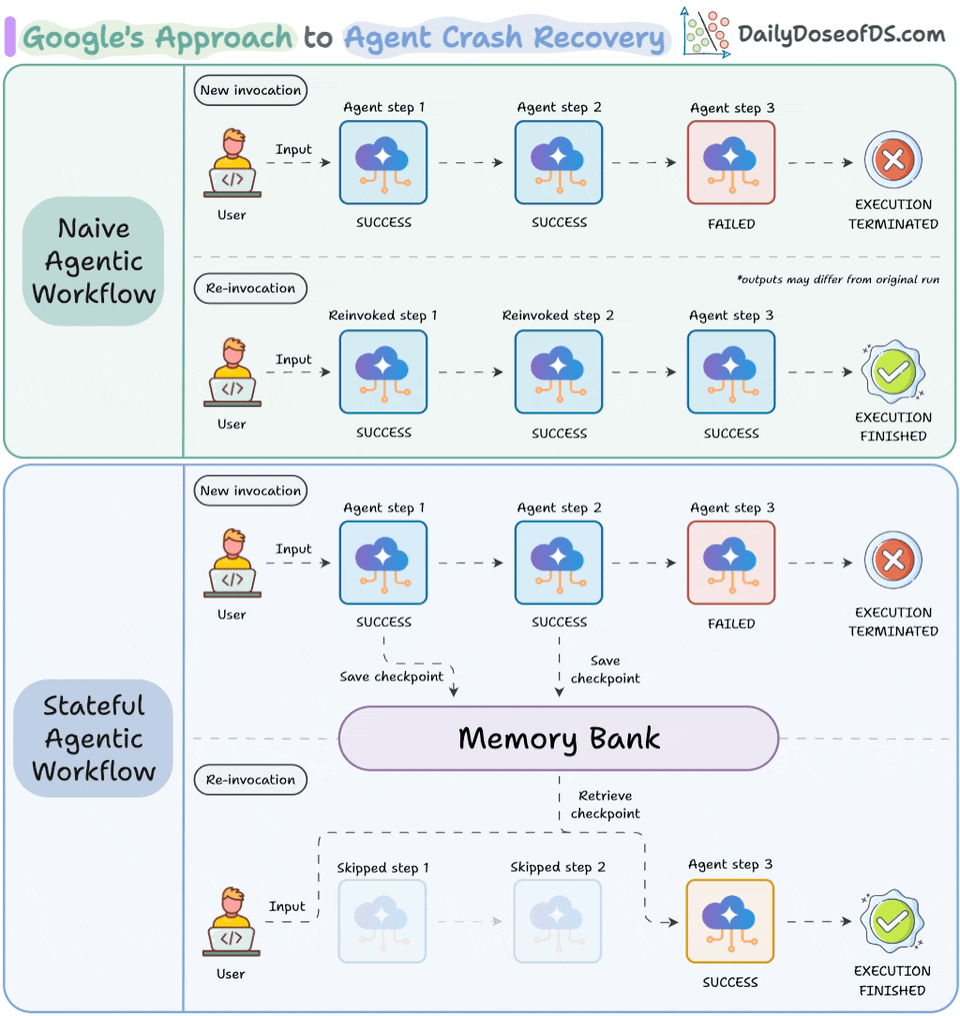
Memory Bank gives agents a persistent state that accumulates across sessions. So the agent on day 5 can read what it decided on day 1 without re-processing. Under the hood, it uses scoped memory extraction, converting conversation history and intermediate decisions into searchable memories that persist and consolidate automatically.
Resume Agents handle checkpoint-and-resume natively within the ADK. When an agent is interrupted (due to a crash, timeout, or human approval gate), Agent Runtime saves the full state. When it resumes, the context reloads exactly as it was. In the ADK, a basic resumable agent definition looks like this:
from google.adk import Agent
root_agent = Agent(
model="gemini-3.1-flash-lite-preview",
name="reconciliation_agent",
description="Reconciles financial records across systems.",
instruction="""Process records in batches. After each batch,
save progress to state. If resumed after interruption,
check state for last completed batch and continue from
there.""",
tools=[ingest_records, cross_reference, flag_anomalies],
)Ambient Agents make execution event-driven. Instead of waiting for a user prompt, the agent activates when new data arrives. For instance, an invoice processing agent can trigger on incoming records, not on a human typing a query.
Why care?
The deeper point here isn’t about Google’s specific implementation.
It’s that the industry has been treating agent memory as a retrieval problem (RAG, vector search, context windows) when the harder problem is actually a consistency problem.
An agent that processes data over days needs the same guarantees that databases have provided for decades, i.e., if it crashes, the recovered state must be identical to the pre-crash state.
LLM non-determinism makes that impossible without explicit checkpointing.
Agent Platform is the first infrastructure that treats this as a platform-level concern rather than leaving it to application developers to solve with custom Redis pipelines and state serialization code.
You can try the Agent Platform here →
👉 Over to you: what’s the longest-running agent workflow you’ve tried to build, and where did state management bite you?
Thanks for reading, and to Google Cloud for working with us on today’s issue!
An interesting perspective.
Though I increasingly suspect the problem may be even deeper than consistency.
Checkpointing can preserve decisions.
Memory can preserve state.
But neither necessarily preserves meaning.
A system can recover perfectly from interruption while still carrying forward assumptions, interpretations, or errors that have gradually drifted from the conditions that originally justified them.
The challenge may not simply be state continuity.
It may be maintaining meaningful correspondence between preserved state and the reality it is meant to represent.