
Why Bagging is So Ridiculously Effective at Variance Reduction?
Diving into the mathematical motivation for using bagging.

Yesterday’s post on improving the performance of random forest models was appreciated by many of you.
More specifically, we looked at a clever trick to:
Increase the accuracy of a random forest model
Decrease its size.
Drastically decrease its prediction run-time.
….without having to ever retrain the model.

Today, let’s continue our discussion on random forest models.
We know that decision trees are always prone to overfitting (high variance).
This happens because a standard decision tree algorithm greedily selects the best split at each node.
This makes its nodes more and more pure as we traverse down the tree.
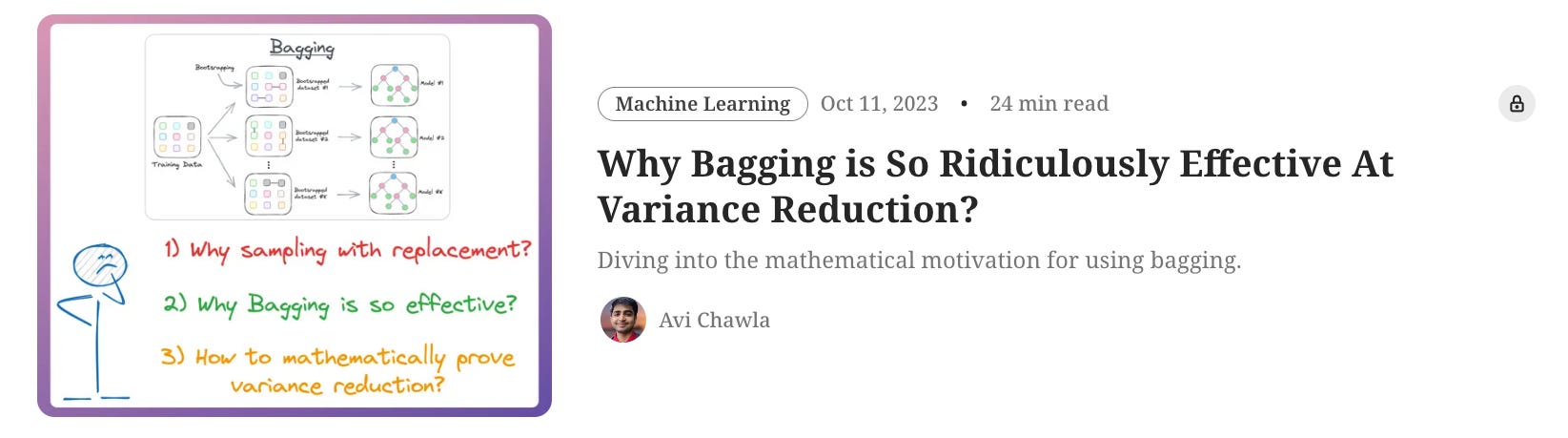
A Random forest solves this overfitting problem with the help of Bagging:

The idea is to:
create different subsets of data with replacement (this is called bootstrapping)
train one model per subset
aggregate all predictions to get the final prediction
As a result, it drastically reduces the variance of a single decision tree model, as shown below:

Decision tree model entirely overfits the data → high variance.
Random forest model performs better → low variance.
The entire credit goes to Bagging.
While we can indeed verify its effectiveness experimentally (shown above), most folks struggle to intuitively understand:
Why Bagging is so effective.
Why do we sample rows from the training dataset with replacement.
How to mathematically formulate the idea of Bagging and prove variance reduction.
Have you truly understood this simple yet overlooked topic?
If not, then this is the topic of this week’s machine learning deep dive: Why Bagging is So Ridiculously Effective At Variance Reduction?
It is important to note that when it comes to building its trees, there is a specific objective a random forest model is always trying to optimize for.
If this objective is not fulfilled, Bagging will be entirely ineffective.
But if you understand this objective, you can create your own variant of a Bagging algorithm.
In my experience, there are plenty of resources that neatly describe:
How Bagging algorithmically works in random forests.
Experimental demo on how Bagging reduces the overall variance (or overfitting).
However, these resources often struggle to provide an intuition on this critical topic.
Things like “Sample with replacement” are usually declared as a given, and the reader is expected to embrace these notions.

The article dives into the entire mathematical foundation of Bagging, which will help you truly understand why the random forest model is designed the way it is.
👉 Curious folks can read it here: Why Bagging is So Ridiculously Effective At Variance Reduction?
I am sure it will clear plenty of your confusion around this topic.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!