
Why is OLS Called an Unbiased Estimator?
Along with a common misconception about unbiasedness.

Before I begin…
What are some popular open-source libraries for scaling, testing, serving, and logging LLMs?
Here’s a visual I published with AIport (a newsletter dedicated to AI developments I frequently contribute to, so do subscribe):

I published an article about these frameworks here (publicly accessible): Top Python Libraries to Accelerate LLM Building.
It will help you understand why LLM training differs widely from traditional deep learning and what tools/techniques make it possible.
Let’s get to today’s post now!
Why is OLS Called an Unbiased Estimator?
The OLS estimator for linear regression (shown below) is known as an unbiased estimator.

What do we mean by that?
Why is OLS called such?
Let’s understand this today!
Background
The goal of statistical modeling is to make conclusions about the whole population.
However, it is pretty obvious that observing the entire population is impractical.

In other words, given that we cannot observe (or collect data of) the entire population, we cannot obtain the true parameter (β) for the population:

Thus, we must obtain parameter estimates (B̂) on samples and infer the true parameter (β) for the population from those estimates:

And, of course, we want these sample estimates (B̂) to be reliable to determine the actual parameter (β).
The OLS estimator ensures that.
Let’s understand how!
True population model
When using a linear regression model, we assume that the response variable (Y) and features (X) for the entire population are related as follows:

β is the true parameter that we are not aware of.
ε is the error term.
Expected Value of OLS Estimates
The closed-form solution of OLS is given by:
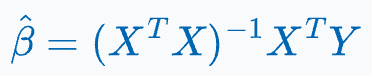
What’s more, as discussed above, using OLS on different samples will result in different parameter estimates:

Let’s find the expected value of OLS estimates E[B̂].
Simply put, the expected value is the average value of the parameters if we run OLS on many samples.
This is given by:
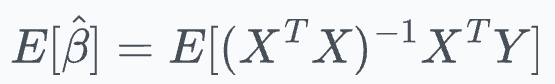
B̂ as the OLS solution Here, substitute Y = βX + ε:

If you are wondering how we can substitute Y = βX + ε when we don’t know what β is, then here’s the explanation:
See, we can do that substitution because even if we don’t know the parameter β for the whole population, we know that the sample was drawn from the population.
Thus, the equation in terms of the true parameters (Y = βX + ε) still holds for the sample.
Let me give you an example.
Say the population data was defined by y = sin(x) + ε. Of course, we wouldn’t know this, but just keep that aside for a second.
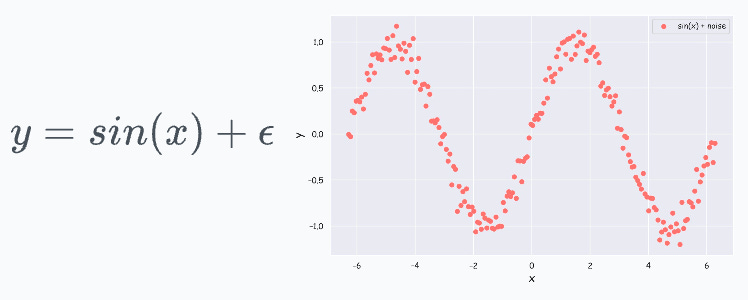
Now, even if we were to draw samples from this population data, the true equation y = sin(x) + ε would still be valid on the sampled data points, wouldn’t it?
The same idea has been extended for expected value.
Coming back to the following:

Let’s open the inner parenthesis:

Simplifying, we get:

And finally, what do we get?

The expected value of parameter estimates on the samples equals the true parameter value β.
And this is precisely what the definition of an unbiased estimator is.
More formally, an estimator is called unbiased if the expected value of the parameters is equal to the actual parameter value.
And that is why we call OLS an unbiased estimator.
An important takeaway
Many people misinterpret unbiasedness with the idea that the parameter estimates from a single run of OLS on a sample are equal to the true parameter values.
Don’t make that mistake.

Instead, unbiasedness implies that if we were to generate OLS estimates on many different samples (drawn from the same population), then the expected value of obtained estimates will be equal to the true population parameter.
And, of course, all this is based on the assumption that we have good representative samples and that the assumptions of linear regression are not violated.
What are these assumptions, and where did they originate from? We covered them in detail here.
👉 Over to you: What are some other properties of the OLS estimator?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 80,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.