
Why Pandas DataFrame Iteration is Slow?
No, vectorization is not the answer!

When using Pandas, we are always advised to avoid iterating on a DataFrame. If we do, it results in a high run-time.
This is evident from the image below:

As depicted above, accessing a column with over 32 million elements is still over 20x faster than accessing a row with just 9 elements.
If you are a Pandas user, you must have heard about this plenty of times.
But have you ever wondered what is the reason behind this?
Why are we advised to avoid iterating a DataFrame?
Many say vectorization, but that’s not an entirely correct answer here.
See, vectorization results from optimizations that are applied:
when dealing with a batch of data together…
…and by avoiding native Python for-loops (which are slow).
If a column is a batch of data, so is a row, right?

If we can apply vectorization to a DataFrame’s column, why can’t we do it with its rows as well?
Let’s understand the core reason behind this.
To better understand the cause of this problem, we must understand the Pandas DataFrame data structure and how it is stored in memory.
A DataFrame is a column-major data structure.
This means that consecutive elements in a column are stored next to each other in memory, as depicted below:
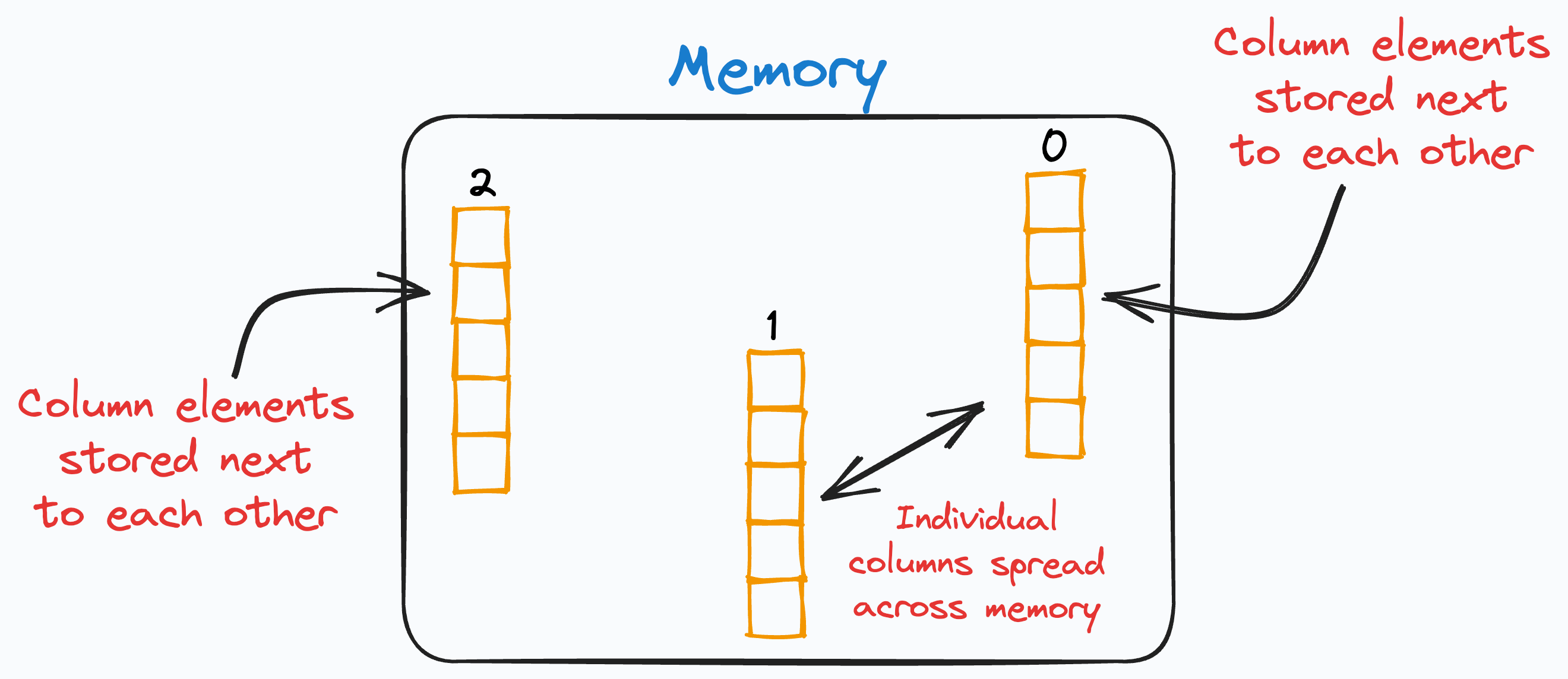
Of course, the individual columns may be spread across different locations in memory. However, the elements of each column are ALWAYS together.
As processors are much more efficient with contiguous blocks of memory, retrieving a column is much faster than fetching a row.

In other words, when iterating, each row is retrieved by accessing non-contiguous blocks of memory.
The processor must continually move from one memory location to another to grab all row elements.
As a result, the run-time increases drastically.
That is why we are always advised to avoid iterating over a DataFrame.
👉 Over to you: What are some things we should be careful of when using a Pandas DataFrame?
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML deep dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
Crystal clear explanation as always 🙌
Good one Avi... by the way, the diagrams in all of your posts are awesome. How are you creating them? I can use same tool for my presentationd