
Why R-squared is a Flawed Regression Metric
...and how to avoid misleading conclusions from it.

Thank you :)
Before I begin today’s post, a big thanks to everyone who considered supporting Daily Dose of Data Science by becoming a premium member 😇.
I was overwhelmed to see plenty of readers converting to paid and showing their support.
For those who haven’t subscribed yet, join before the offer ends:
Offer:
Any pricing updates will NEVER affect your plan.
Pause and renew anytime at the same price.
Upcoming courses and bonus resources (practice notebooks, extensive study guides, etc.) included.
Only 30 hours remain before this ends.
Next member-only post releasing this Friday.
Thanks again :)
Let’s get to today’s post now.
R2 is quite popularly used all across data science and statistics to assess a model.
Yet, contrary to common belief, it is often interpreted as a performance metric for evaluating a model, when, in reality, it is not.
Let’s understand!
R2 tells the fraction of variability in the outcome variable captured by a model.
It is defined as follows:
In simple words, variability depicts the noise in the outcome variable (y).

Thus, the more variability captured, the higher the R2.
This means that solely optimizing for R2 as a performance measure:
promotes 100% overfitting.
leads us to engineer the model in a way that captures random noise instead of underlying patterns.
It is important to note that:
R2 is NOT a measure of predictive power.
Instead, R2 is a fitting measure.
Thus, you should NEVER use it to measure goodness of fit.
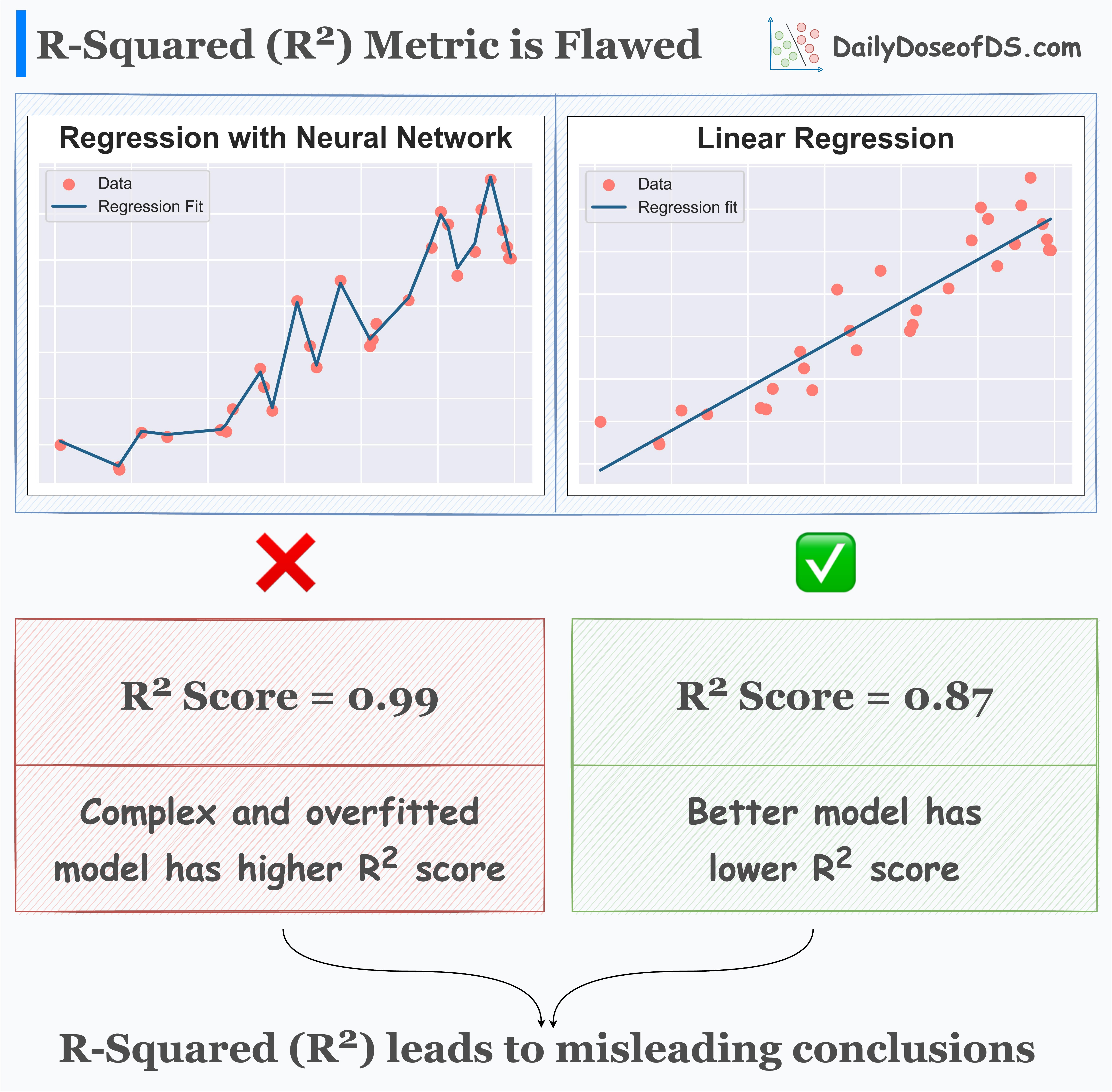
This is evident from the image below:
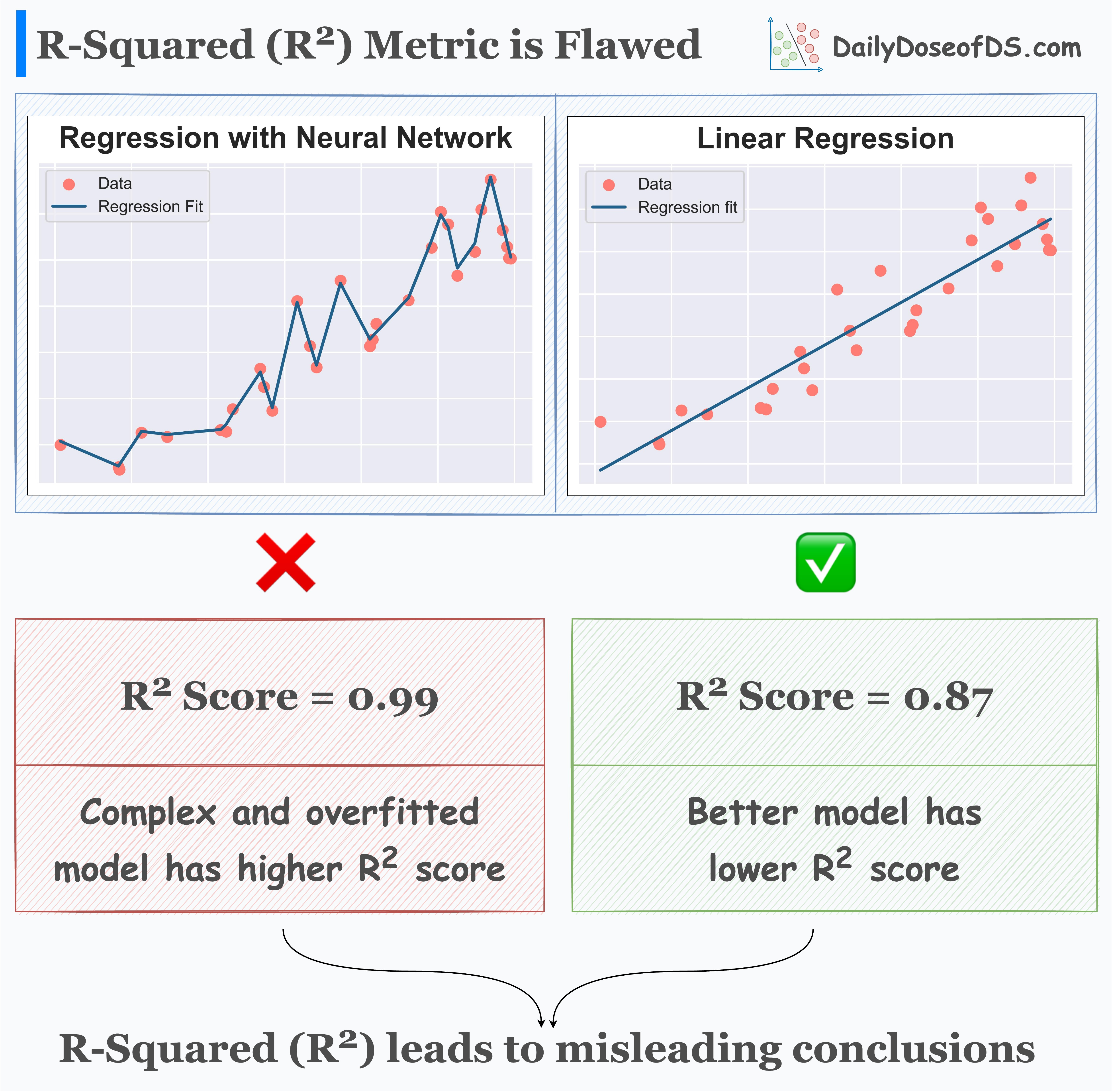
An overly complex and overfitted model almost gets a perfect R2 of 1.
A better and more generalized model gets a lower R2 score.
Some other flaws of R2 are:
R2 always increases as you add more features, even if they are random noise.
In some cases, one can determine R2 even before fitting a model, which is weird.
👉 Read my full blog on the A-Z of R2, what it is, its limitations, and much more here: Flaws of R2 Metric.
👉 Over to you: What are some other flaws in R2?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can connect with me on LinkedIn and Twitter.
This post is deeply misleading. The problem at hand is not the R-squared metric, it is model overfitting. The use of R-squared does not cause overfitting, it is the lack of model validation and/or regularization.
Would you be interested in collaborating? I write about AI Research, ML Engineering and DS as well. My main newsletter- AI Made Simple- is currently at 97K readers- https://artificialintelligencemadesimple.substack.com/