
Why Sigmoid in Logistic Regression?
The origin of sigmoid from a probabilistic perspective.


Logistic regression returns the probability of a binary outcome (0 or 1).
We all know logistic regression does this using the sigmoid function.
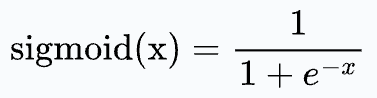
But why?
In other words, have you ever wondered why we use Sigmoid in logistic regression?
The most common reason we get to hear is that Sigmoid maps all real values to the range [0,1].

But there are infinitely many functions that can do that.
What is so special about Sigmoid?
What’s more, how can we be sure that the output of Sigmoid is indeed a probability?
See, as discussed above, logistic regression output is interpreted as a probability.
But this raises an essential question: “Can we confidently treat the output of sigmoid as a genuine probability?”
It is important to consider that not every numerical value lying within the interval of [0,1] guarantees that it is a legitimate probability.
In other words, just outputting a number between [0,1] isn’t sufficient for us to start interpreting it as a probability.
Instead, the interpretation must stem from the formulation of logistic regression and its assumptions.
So where did the Sigmoid come from?
If you have never understood this, then…
This is precisely what we are discussing in this today’s article, which is available for free for everyone.

We are covering:
The common misinterpretations that explain the origin of Sigmoid.
Why are these interpretations wrong?
What an ideal output of logistic regression should look like.
How to formulate the origin of Sigmoid using a generative approach under certain assumptions.
What if the assumptions don’t hold true.
How the generative approach can be translated into the discriminative approach?
Best practices while using generative and discriminative approaches.
Hope you will get to learn something new :)
The article is available for free to everyone.
👉 Interested folks can read it here: Why Do We Use Sigmoid in Logistic Regression?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Whenever you’re ready, here are a couple of more ways I can help you:
Get the full experience of the Daily Dose of Data Science. Every week, receive two curiosity-driven deep dives that:
Make you fundamentally strong at data science and statistics.
Help you approach data science problems with intuition.
Teach you concepts that are highly overlooked or misinterpreted.

Promote to over 28,000 subscribers by sponsoring this newsletter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Wow! I always learn new and solid stuff from your post. Thanks for this great article Avi!
In the screenshot you mentioned "on simplifying further". From where and what did you simplify? What function did you assume in the beginning and why did you substitute x+2/2 and x-3/2?