
Why Similarity Isn’t Enough for Memory
...and an open-source solution to fix this!

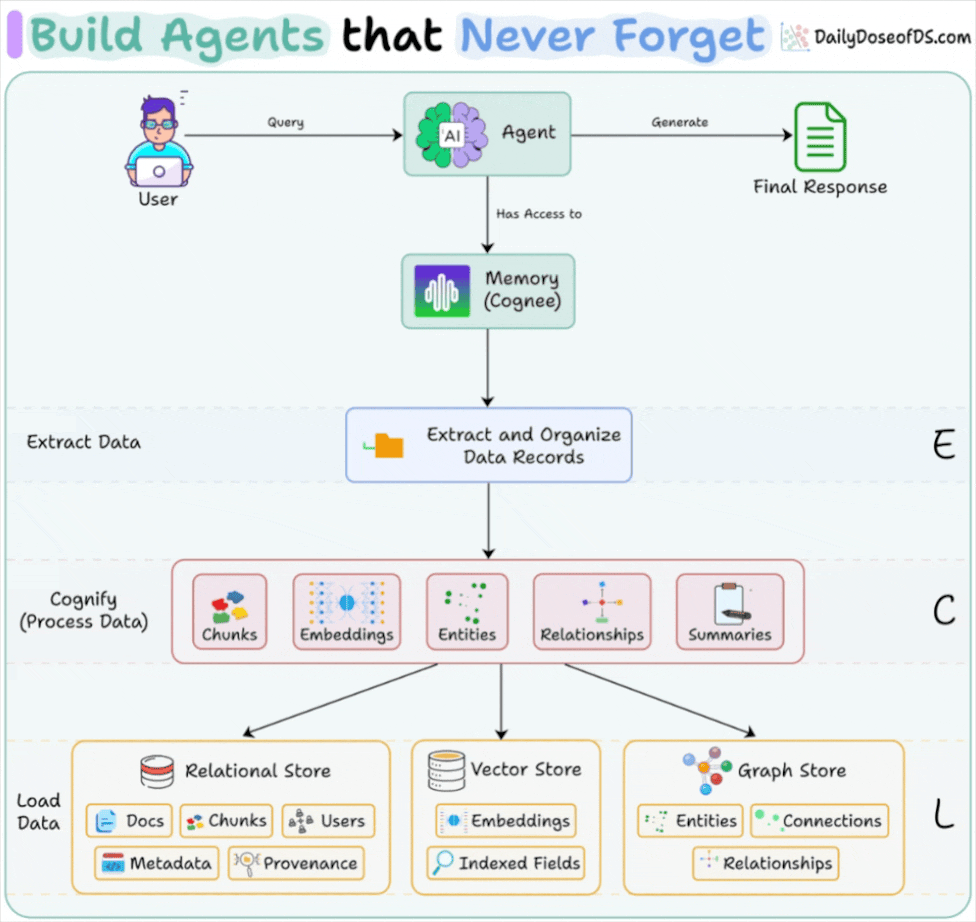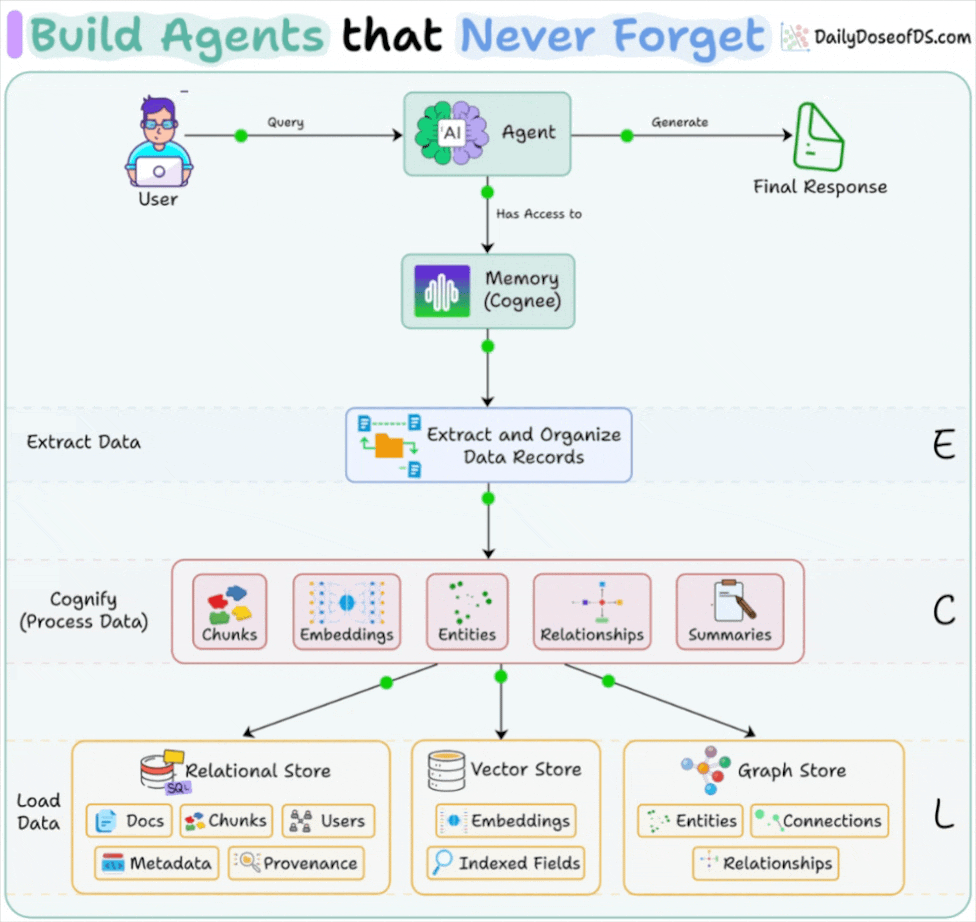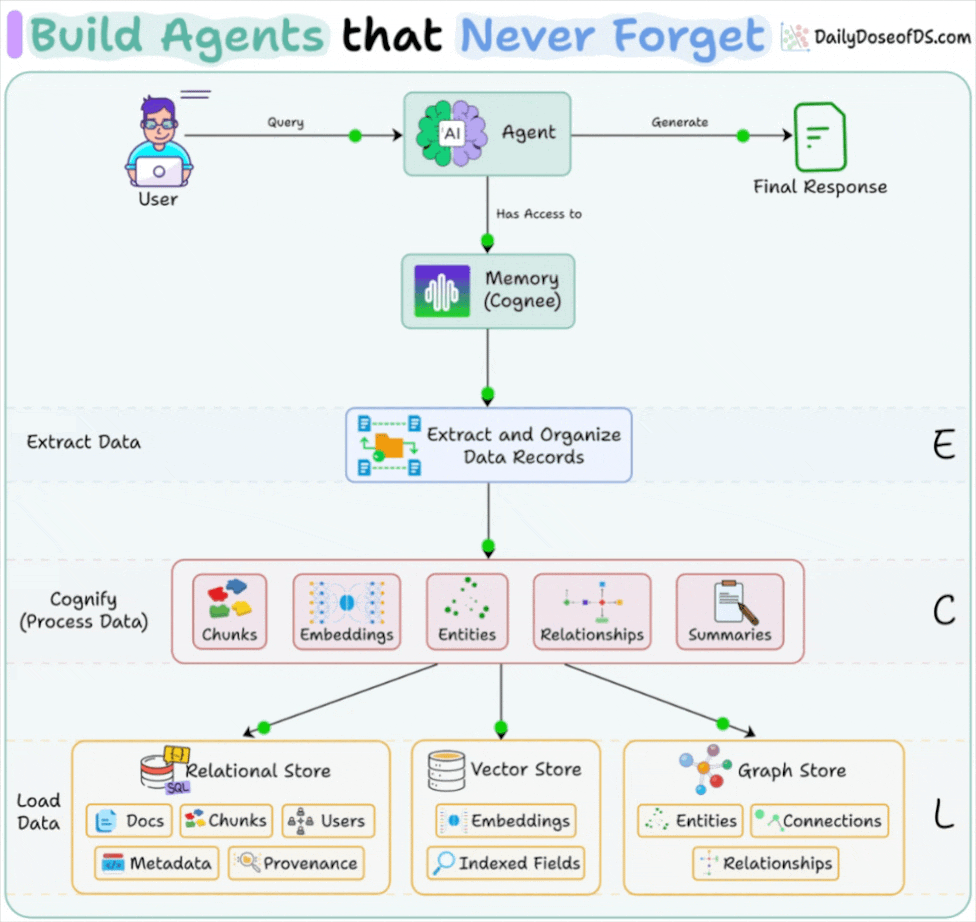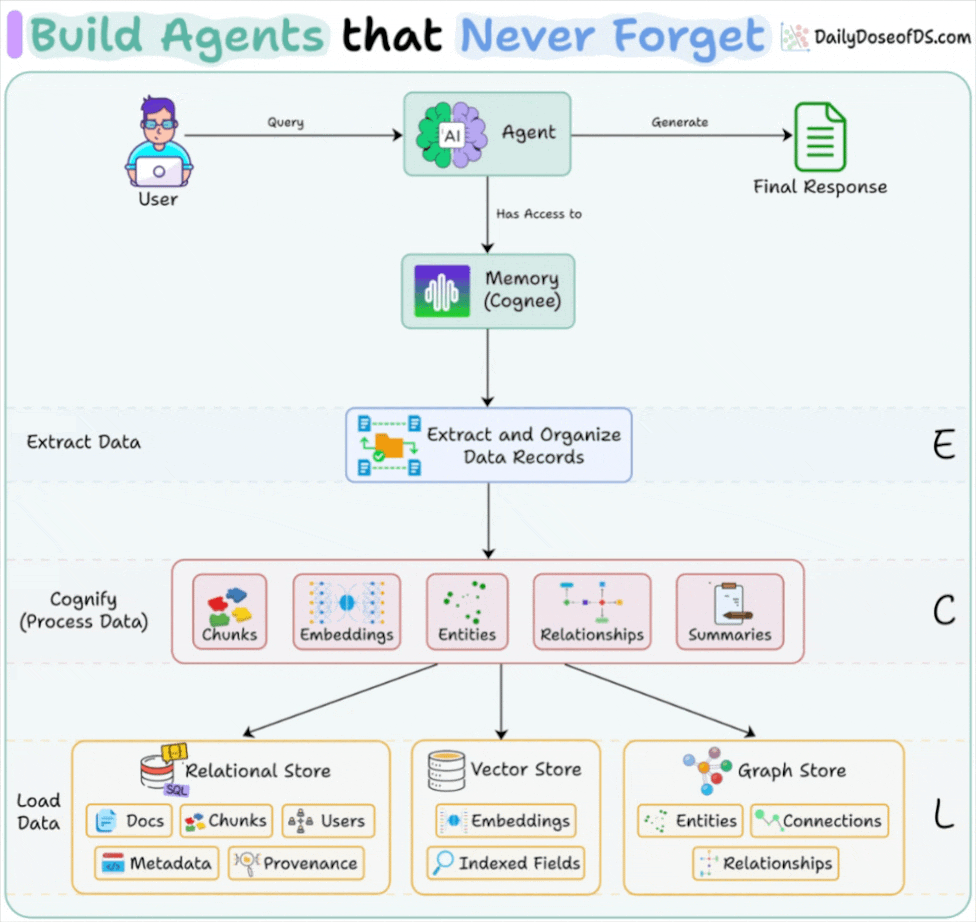
Agents are stateless by default. Every returning user is a stranger.
The common fix is adding a vector database. But here’s the problem: similarity isn’t memory.
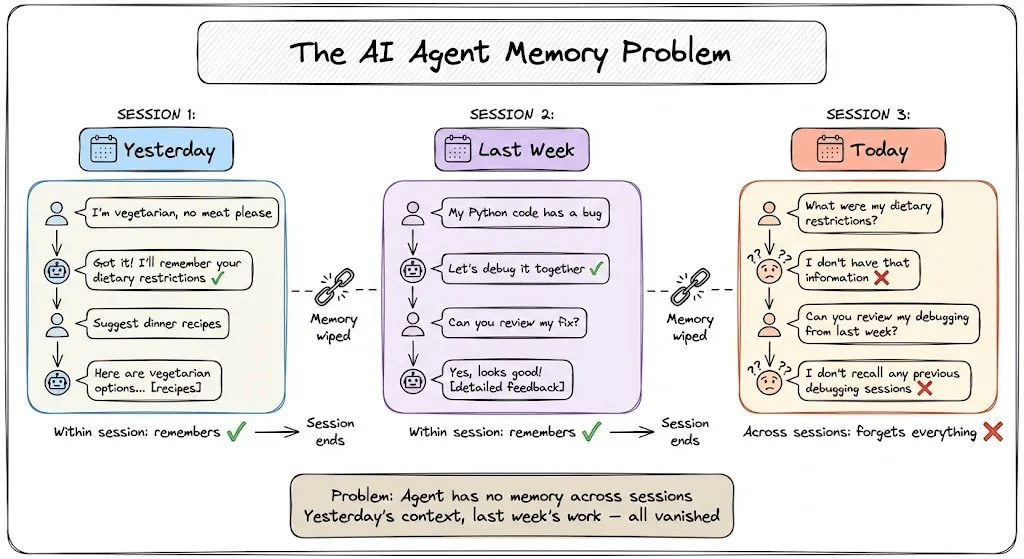
Let’s understand this in more detail today. Later in this article, we’ll show you an open-source framework to solve this problem!
Why similarity isn’t enough for memory
Consider this conversation:
Week 1: User says, “I just had a steak at Morton’s, and it was incredible.”
Week 2: User mentions, “I decided to go vegetarian.”
Week 3: User asks, “What restaurants should I try this weekend?”
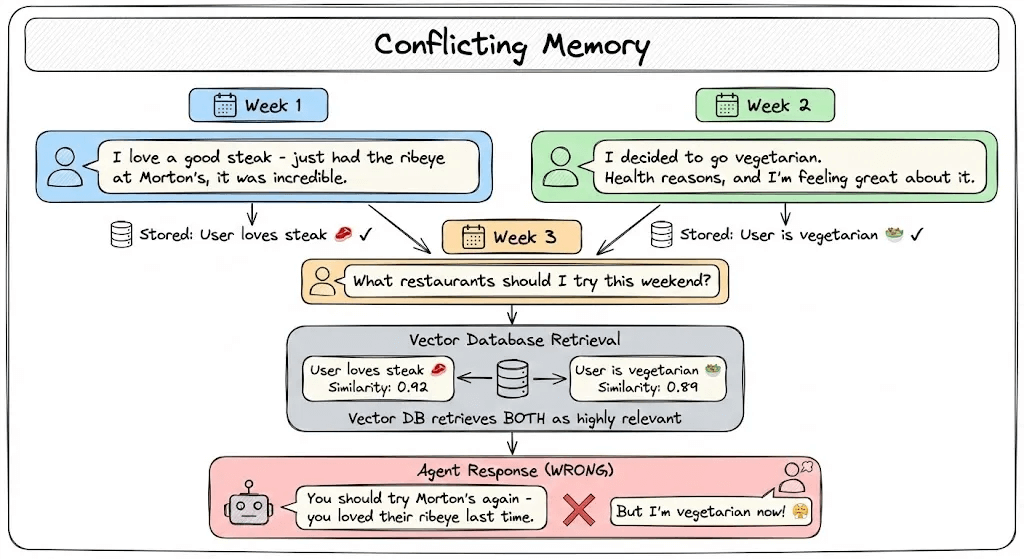
The vector DB will likely return both statements as highly relevant, and the Agent could recommend Morton’s steak.
The problem is that embeddings measure semantic closeness, not truth.
They don’t understand that “decided to go vegetarian” replaces “I love steak” so two food-related statements are treated equally.
What Agents actually need to remember
To fix this, we need to step back and understand what memory actually means for agents.
Production Agents need two layers of memory:
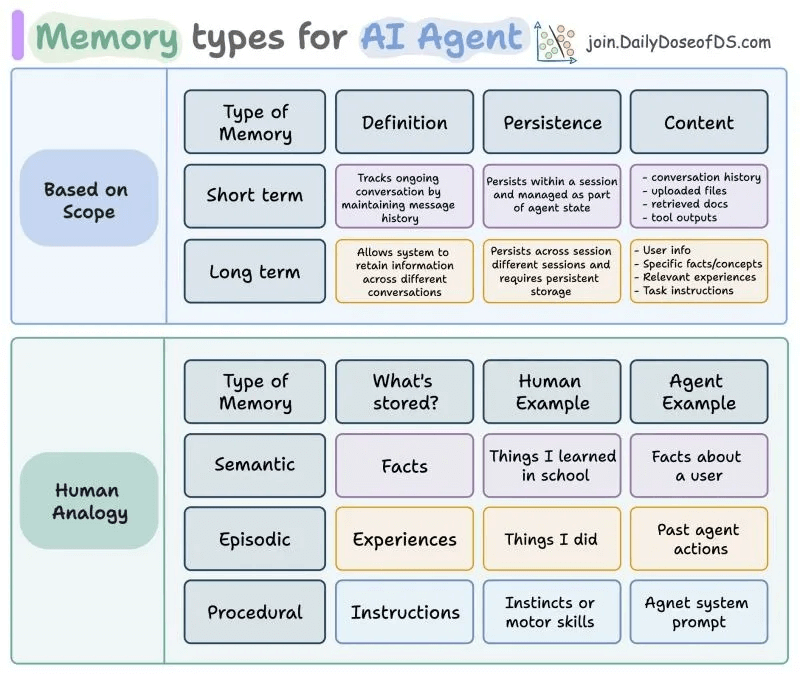
Short-term memory tracks ongoing conversations within a session, such as conversation history, uploaded files, retrieved documents, and tool outputs.
Long-term memory persists across sessions and stores user information, preferences, learned facts, and past experiences. This is what should survive after the conversation ends.
Within long-term memory, agents need three types of sub-memories:
Semantic memory stores facts and concepts, such as “User prefers Python,” “works in fintech,” and “went vegetarian.”
Episodic memory stores experiences and events such as past actions, previous solutions that worked, and the history of interactions.
Procedural memory stores instructions and processes, including system prompts, workflow instructions, and operational procedures.
Building memory systems
Supporting short-term context, long-term persistence, and evolving beliefs requires building a system, not a single component.
The first piece is short-term memory (the active context for a single session). It keeps the conversation coherent, but once you hit the token limit, older messages are dropped, and important context disappears.

To retain information across sessions, we add long-term memory by extracting facts from conversations, embedding them and storing them in a vector DB:

But memory is not static. Users change preferences and override earlier instructions. We need to model change over time by detecting conflicts and marking which information is current vs. historical:

That still doesn’t solve retrieval. When a new query comes in, the agent has to decide which version of a memory is current. One approach is to bias retrieval toward more recent memories, gradually reducing the influence of older ones:

At this point, the system has short-term memory, long-term storage, conflict resolution and temporally aware retrieval. Building this from scratch takes significant time, and many of the hardest problems only surface in production.
An open-source memory framework
Cognee is a 100% open-source framework that solves this by combining vector search with knowledge graphs.
Here’s what makes it different:
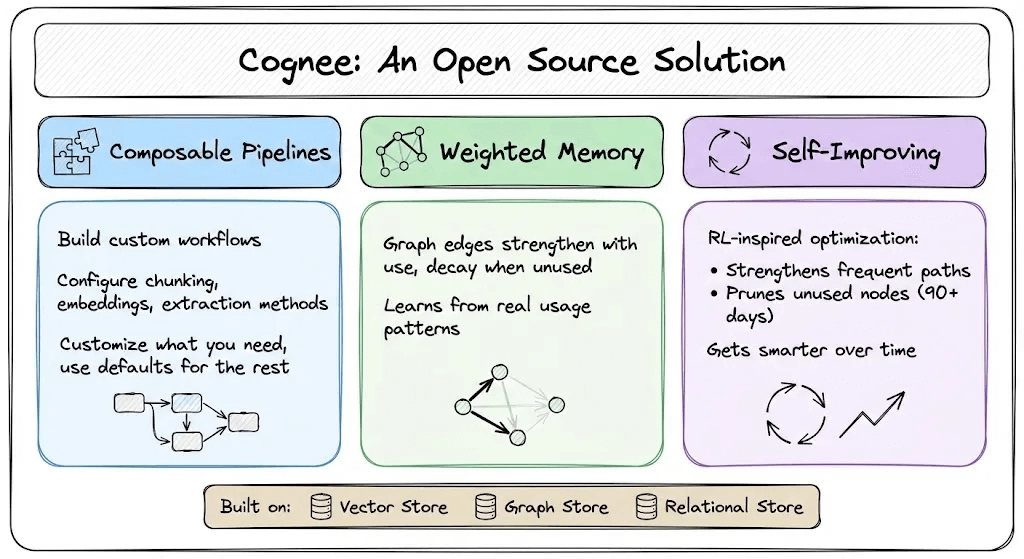
Composable pipelines: Instead of locking you into a fixed workflow, Cognee lets you customize chunking strategies, embedding models, and entity extraction methods within the same pipeline.
Weighted memory: Connections in the knowledge graph are weighted based on usage. When retrieved information contributes to a successful response, the corresponding relationships become stronger. Over time, the graph reflects what actually matters in practice.
Self-improving (memify): Memory is continuously refined through RL-inspired optimization, strengthening useful paths, pruning stale nodes, and auto-tuning based on real usage patterns.
Cognee uses three complementary storage systems: a vector store for semantic search, a graph store for relationships and temporal logic, and a relational store for tracking provenance and metadata.
All the complexity we showed earlier, like managing short-term context, evolving long-term facts, resolving conflicts, and retrieving the right information, reduces to six lines of code:
That’s it.
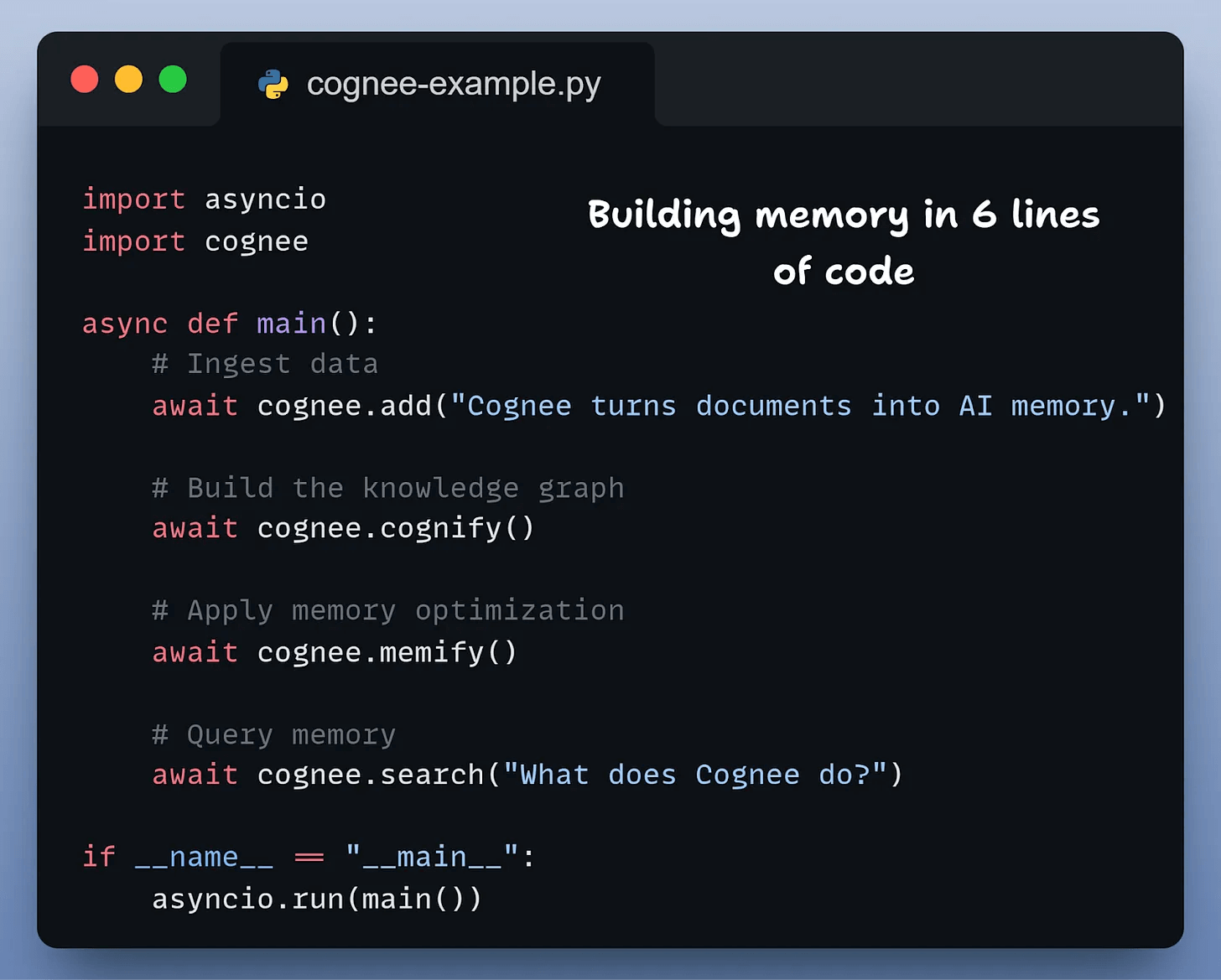
add()ingests your documents (text, PDFs, audio, images)cognify()builds the knowledge graph with entities and relationshipsmemify()optimizes memory based on usage patternssearch()retrieves with temporal awareness
How Cognee handles the vegetarian scenario
Let’s replay the same scenario with Cognee handling memory.
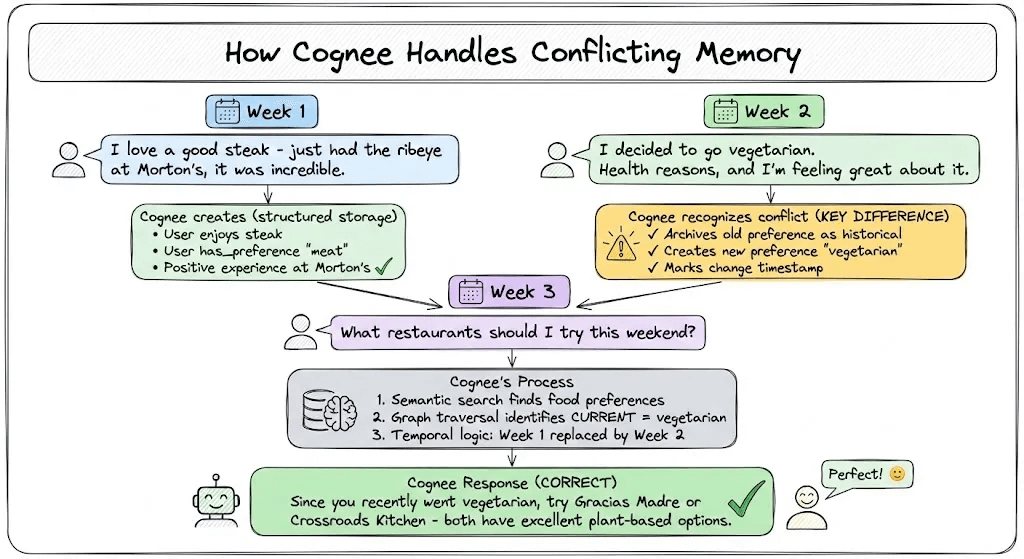
Week 1:
User says, “I just had a steak at Morton’s, and it was incredible.”
Cognee creates: User enjoys steak, User has_preference “meat”, positive experience at Morton’s.
Week 2:
User says: “I decided to go vegetarian. Health reasons, and I’m feeling great about it.”
Cognee recognizes the conflict. It archives previous meat preference as historical, creates a new preference “vegetarian”, marks the change timestamp.
Week 3: “What restaurants should I try this weekend?”
Cognee’s process:
Semantic search finds food preferences and restaurant content
Graph traversal identifies that the current dietary preference is vegetarian
Temporal logic recognizes that Week 1 preference was replaced by Week 2 decision
Returns: “Since you recently went vegetarian, try Gracias Madre or Crossroads Kitchen - both have excellent plant-based options.”
The memory layer understands that preferences change over time, archives outdated info as historical context, and uses current state for recommendations.
Conclusion
Vector search retrieves content based on similarity. But similarity doesn’t tell you which information is current, how facts relate to each other, or what’s been superseded by newer information.
For production agents, you need memory that tracks relationships between facts, understands that information changes over time, and improves based on actual usage.
Building this from scratch means coordinating vector stores, graph databases, and custom retrieval logic. That’s weeks of work and a lot of edge cases you won’t see until production.
Cognee provides these capabilities as a single open-source system, so you don’t have to assemble and maintain them yourself.
Thanks for reading!