


Why Sklearn's Linear Regression Has No Hyperparameters?
Did Sklearn miss something or did we miss something?


All ML models we work with have some hyperparameters, such as:
Learning rate
Regularization
Layer size (for neural network), etc.
But as shown in the image above, why don’t we see one in Sklearn’s Linear Regression implementation?
To understand the reason, we first need to realize that the Linear Regression algorithm can model data in two different ways:
Gradient Descent (which we use with almost all other ML algorithms):
It is a stochastic algorithm, i.e., involves some randomness.
It finds an approximate solution using optimization.
It has hyperparameters.
Ordinary Least Square (OLS):
It is a deterministic algorithm. If run multiple times, it will always converge to the same weights.
It always finds the optimal solution.
It has no hyperparameters.
Instead of gradient descent, Sklearn’s Linear Regression class implements the OLS method.
That is why it has no hyperparameters.
How does OLS work?
With OLS, the idea is to find the set of parameters (Θ) such that:
where,
X: input data with dimensions(n,m).Θ: parameters with dimensions(m,1).y: output data with dimensions(n,1).n: number of samples.m: number of features.
The parameter matrix Θ can be directly determined by multiplying both sides of the equation with the inverse of X, as shown below:
But because X might be a non-square matrix, its inverse may not be defined.
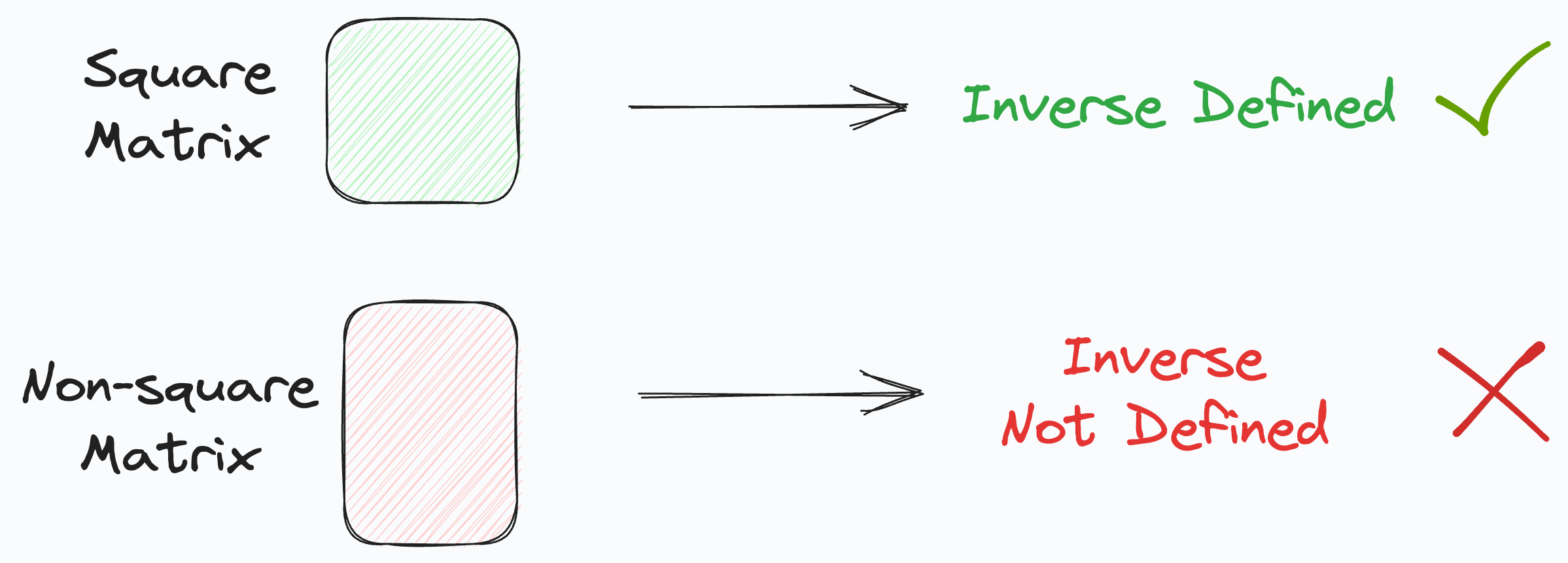
To resolve this, first, we multiply with the transpose of X on both sides, as shown below:
This makes the product of X with its transpose a square matrix.

The obtained matrix, being square, can be inverted (provided it is non-singular).
Next, we take the collective inverse of the product to get the following:
It’s clear that the above equation has:
No hyperparameters.
No randomness. Thus, it will always return the same solution, which is also optimal.
This is precisely what the Linear Regression class of Sklearn implements. Instead of gradient descent, it uses the OLS method.
That is why it has no hyperparameters.
Of course, there are tradeoffs involved too. You trade run-time for finding an optimal solution without hyperparameter tuning.
I would highly recommend reading one of my previous posts about this: Most Sklearn Users Don’t Know This About Its LinearRegression Implementation.
👉 Over to you: How would you prove that the solution returned by OLS is optimal? Would love to read your answers :)
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.