
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
What are we missing here?

The most common way of learning the weights (θ) of a logistic regression model, as taught in most lectures/blogs/tutorials, is using gradient descent:

As depicted above, we specify a learning rate (α) before training the model and run it for a specified number of iterations (epochs).
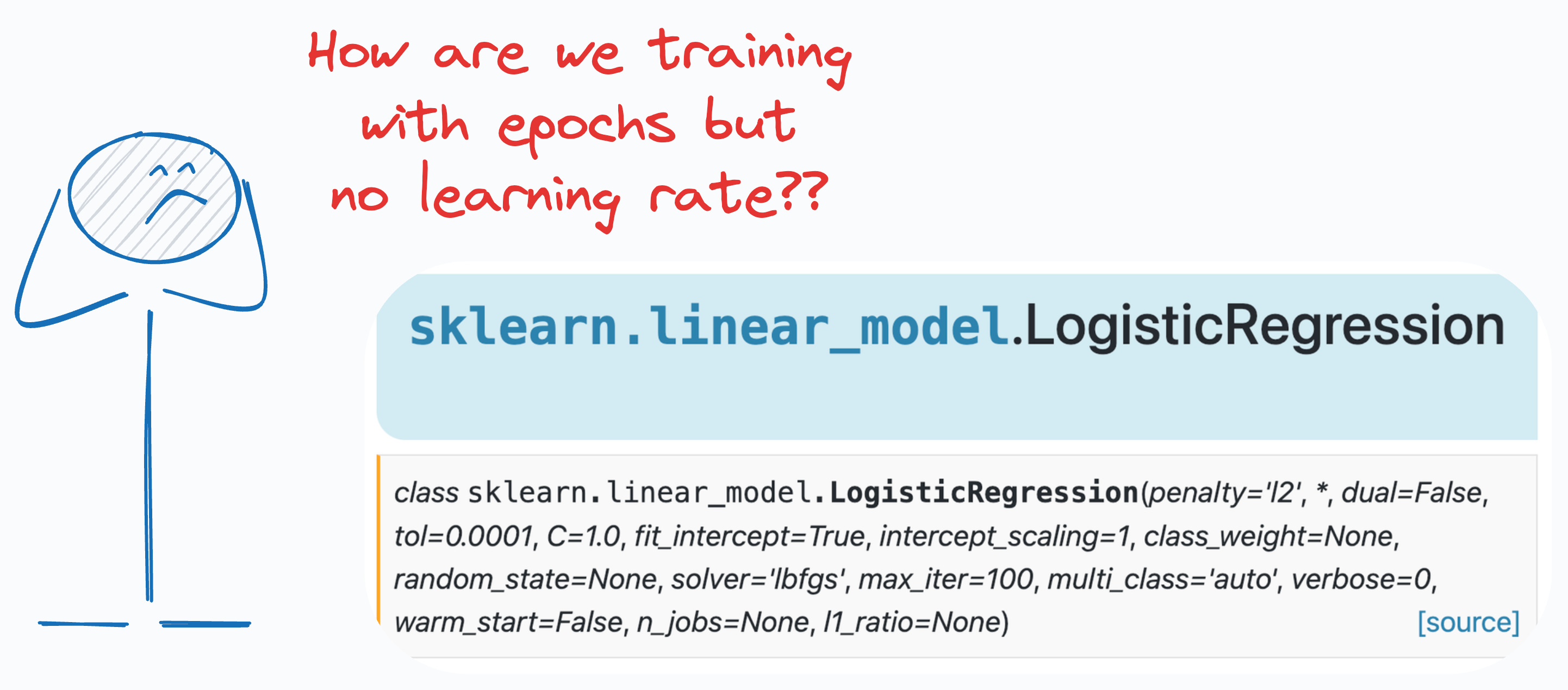
However, if that is how we train logistic regression, then why don’t we see a learning rate hyperparameter (α) in its sklearn implementation:

Interesting, isn’t it?
Moreover, the parameter list has the ‘max_iter’ parameter that intuitively looks analogous to the epochs.

But how does that make sense?
We have epochs but no learning rate (α), so how do we even update the model parameters using SGD?
Are we missing something here?
It turns out, we are indeed missing something here.
More specifically, it is important to note that SGD, although popular, is NOT the only way to train a logistic regression model.
There are more optimal ways, but most of us never consider them.
However, the importance of these alternate mechanisms is entirely reflected by the fact that even sklearn, one of the most popular libraries of data science and machine learning, DOES NOT use SGD in its logistic regression implementation.
What are these mechanisms, and why do we prefer them over SGD?
If you are curious about them, then this is what we are discussing in the latest deep dive: Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?

Today’s article is a purely mathematical deep dive that uncovers ways to train a logistic regression model without learning rate.
We get into their entire mathematical formulation and discuss the advantages and tradeoffs of using these alternate methods.
Read it here: Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
Honestly, I have wanted to write this article for a while. This is because, in my experience, everyone is a big fan of sklearn implementations.
It literally takes just two (max three) lines of code to run any ML algorithm with sklearn.
Yet, due to this simplicity, most users often overlook the underlying implementations of their algorithms and later complain about bad results.
Also, most courses/books/tutorials that cover logistic regression demonstrate its training using the gradient descent method.
But the most popular implementations are not even using it. Isn’t that ironic and amusing?
That is why it is important to be aware of more optimal mechanisms (if any) to train classical ML models.
I am sure you will learn something new today.
Check it out here: Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
👉 Over to you: What other algorithms do most people have a misconception about?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Implementations of sklearn.linear_model.SGDClassifier has learning rate argument. Becuase using SGDClassifier we can implement most of the algorithm by passing the loss using GD method.
The implementation of sklearn.linear_model.LogisticsRegressio is more like a LinearRegression by finding optimal weitghts. I cant explain much but This is my understanding.