


Why ‘Variance’ Serves as the Prime Indicator for Dimensionality Reduction in PCA?
Here's why using variance makes sense in PCA.

We all know that during dimensionality reduction, PCA tries to retain the maximum variance of the original data.
We have already discussed it a few times before, so we won’t discuss it again.
Nonetheless, I still think many struggle to intuitively understand the motivation for using “variance” here.
In other words, have you ever wondered:
Why retaining maximum variance is an indicator for retaining maximum information?
Today, let me provide you an intuitive explanation of this.
Imagine someone gave us the following weight and height information about three individuals:
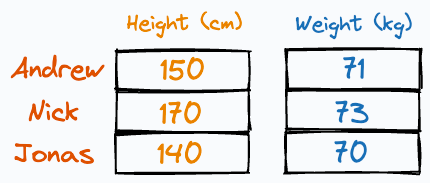
It is easy to guess that the height column has more variation than weight, isn’t it?

Thus, even if we discard the weight column, we can still identify these people solely based on their heights.

The one in the middle is Nick.
The leftmost person is Jonas.
The rightmost one is Andrew.
That was super simple.
But what if we discarded the height column instead?

Can you identify them now?
No, right?
Why?
This is because their heights have more variation than their weights.
And it’s clear from the above example that, typically, if a column has more variation, it holds more information.
That is the core idea PCA is built around, and that is why it tries to retain maximum data variance.
Simply put, PCA was devised on the premise that more variance means more information.

Thus, during dimensionality reduction, we can (somewhat) say that we are retaining maximum information if we retain maximum variance.
Of course, we also know that variance can be easily inflated by outliers.
That is why we say that PCA is influenced by outliers.
I hope that the above explanation helped :)
As a concluding note, always remember that when using PCA, we don’t just measure column-wise variance and drop the columns with the least variance.
Instead, we must first transform the data to create uncorrelated features. After that, we drop the new features based on their variance.
If you wish to get into more detail, we mathematically formulated the entire PCA algorithm from scratch here: Formulating the Principal Component Analysis (PCA) Algorithm From Scratch.

The article covers:
The intuition and the motivation behind dimensionality reduction.
What are vector projections and how do they alter the mean and variance of the data?
What is the optimization step of PCA?
What are Lagrange Multipliers?
How are Lagrange Multipliers used in PCA optimization?
What is the final solution obtained by PCA?
Proving that the new features are indeed uncorrelated.
How to determine the number of components in PCA?
What are the advantages and disadvantages of PCA?
Key takeaway.
👉 Interested folks can read it here: Formulating the Principal Component Analysis (PCA) Algorithm From Scratch.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
As always, thanks for reading :)
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!