
Why Your Graph Database Is Slow
...and how linear algebra fixes it (explained with code)!

UDFs, FLEX, and Graph Database 2025 Recap

If you’re building RAG systems, GraphRAG is proving to be a serious upgrade over pure vector search. Knowledge graphs preserve entity relationships that embeddings simply can’t capture, leading to fewer hallucinations and better contextual reasoning for AI agents.
FalkorDB is built for this use case: it’s the first queryable Property Graph database to leverage sparse matrices and linear algebra for querying GitHub, delivering the low latency needed for real-time AI apps.
The FalkorDB team is hosting a free live session on building User-Defined Functions (UDFs) and using FLEX to extend your graph database capabilities.
What you’ll learn:
Creating your first UDF
Leveraging FLEX in projects
Graph database 2025 recap
Why your graph database is slow (and how linear algebra fixes it)
Google.
Microsoft.
AWS.
Everyone’s trying to solve the same problem for AI Agents:
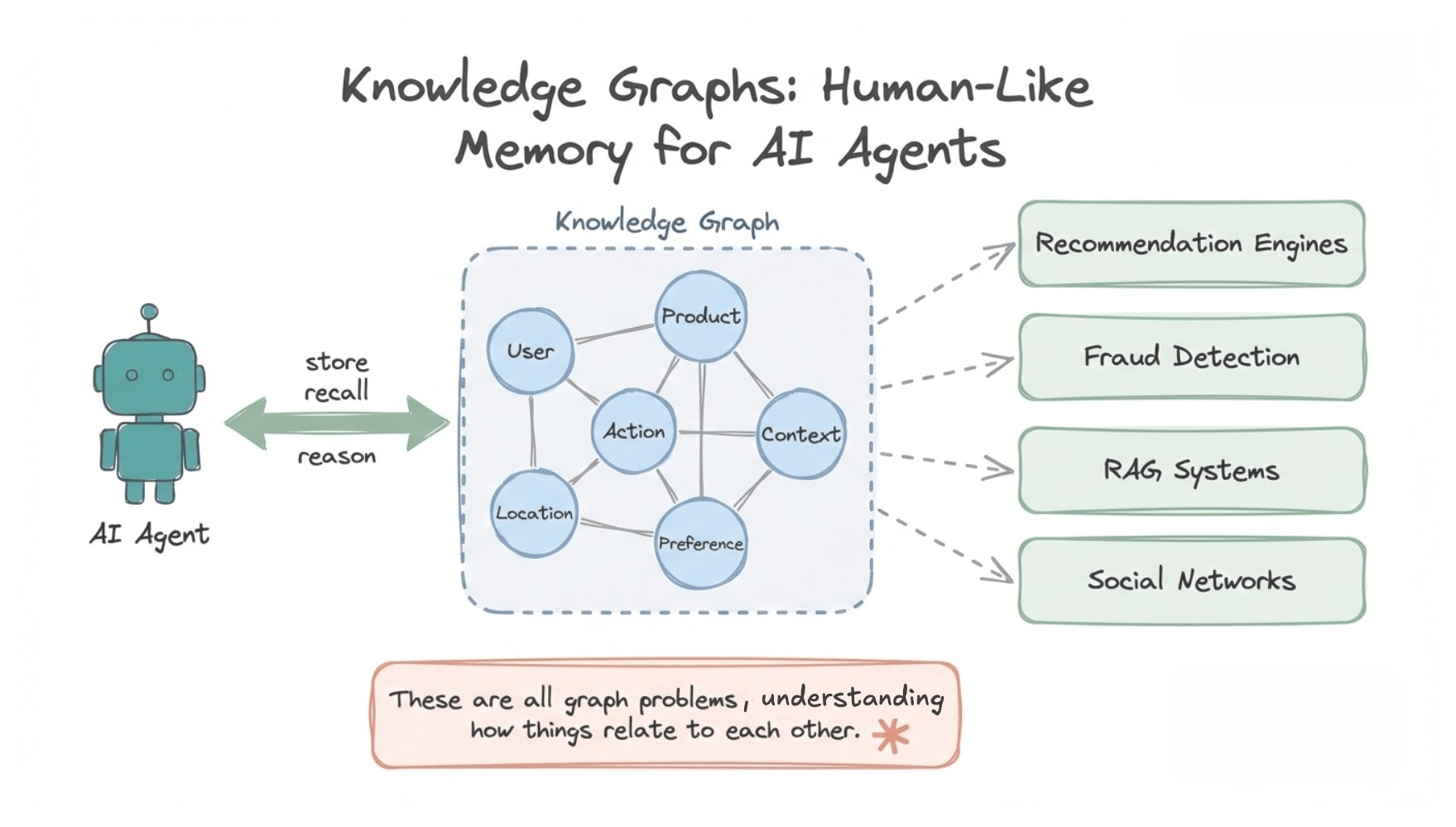
How to build knowledge graphs that are fast enough for real-time LLM applications?
Instead of treating every conversation as a blank slate, agents can store relationships, recall context, and reason across connected information in real time. This makes knowledge graphs popular among agent builders.
And it’s not just agents. Knowledge graphs power some of the most demanding systems in production today:
recommendation engines
fraud detection
RAG systems
social networks
These are all graph problems where you need to understand how things are related to each other.
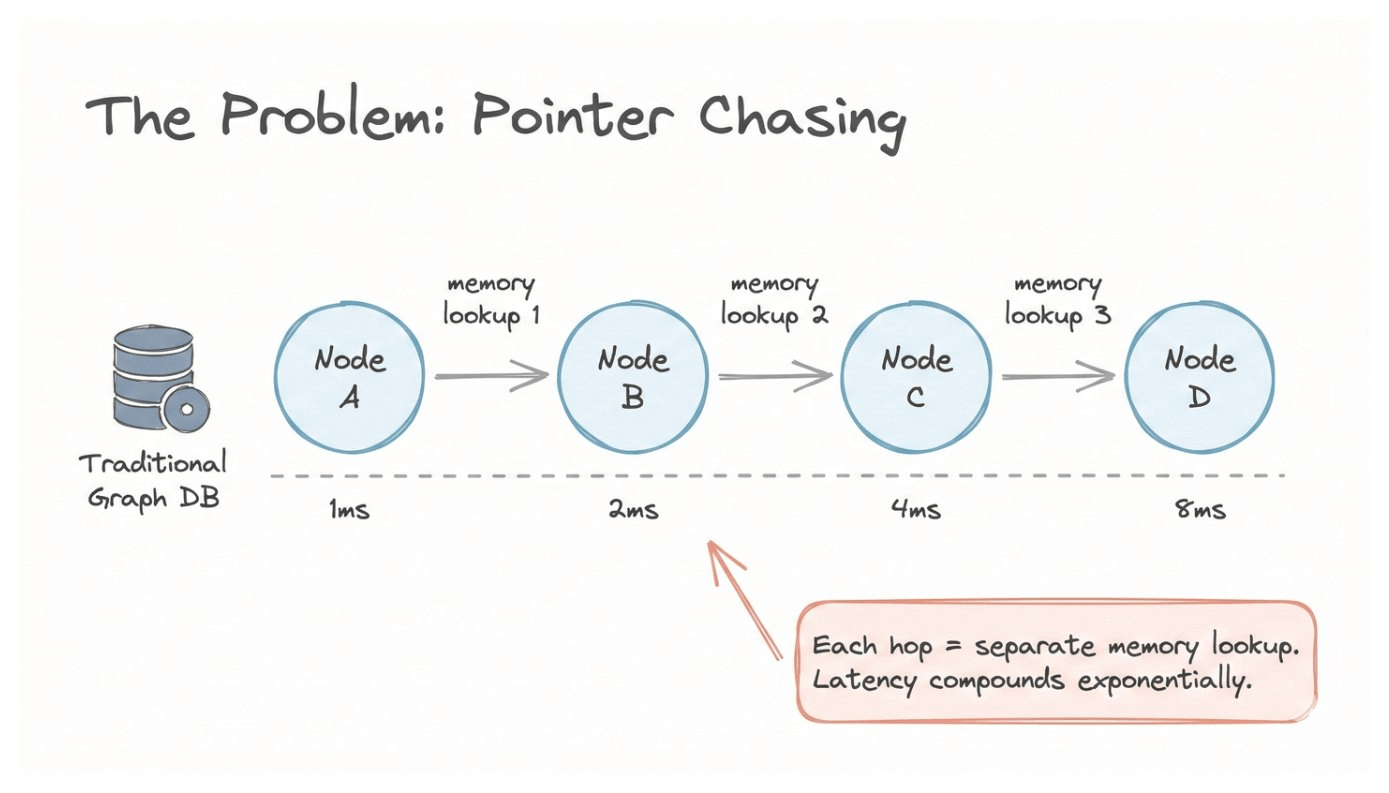
The problem with traditional graph databases
Traditional graph databases store relationships as pointers. To traverse them, you chase one pointer at a time:
start at node A
follow a connection to node B
read B’s connections
jump to node C
repeat
Each hop requires a separate memory lookup. The more connections you explore, the slower it gets.
For simple queries, this works fine. But when your agent needs to perform multi-hop reasoning across thousands of entities in real-time, every millisecond compounds.
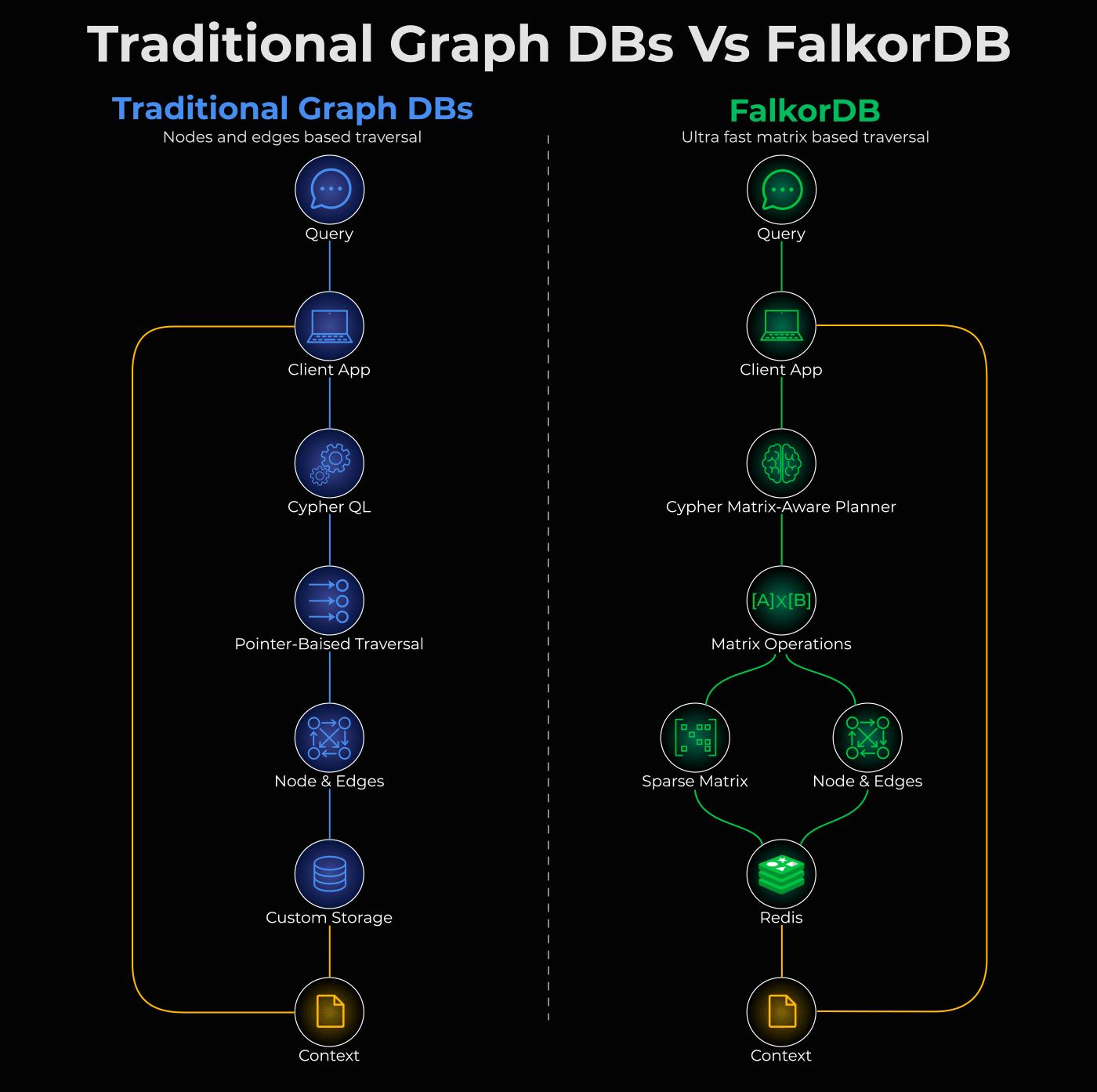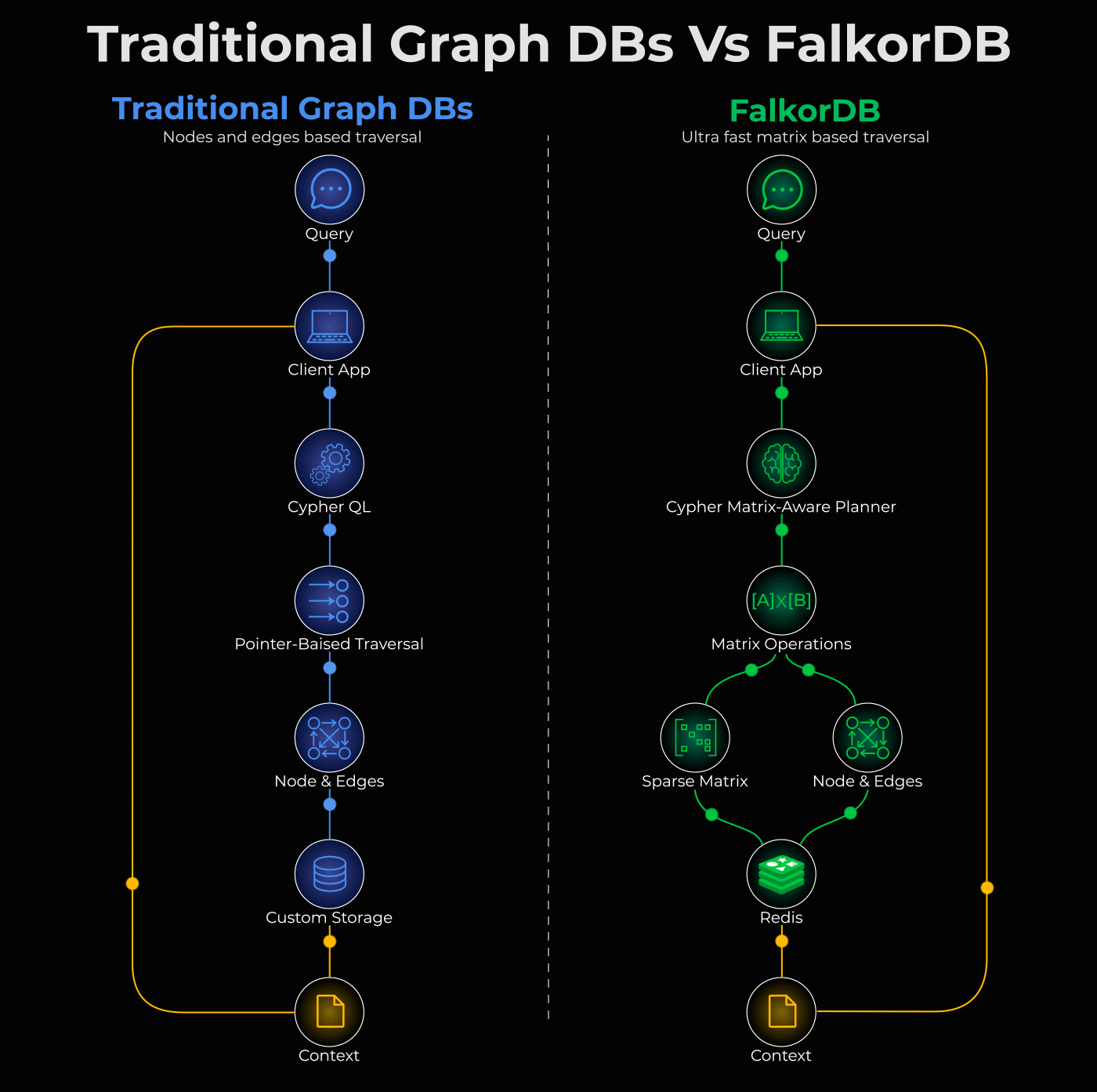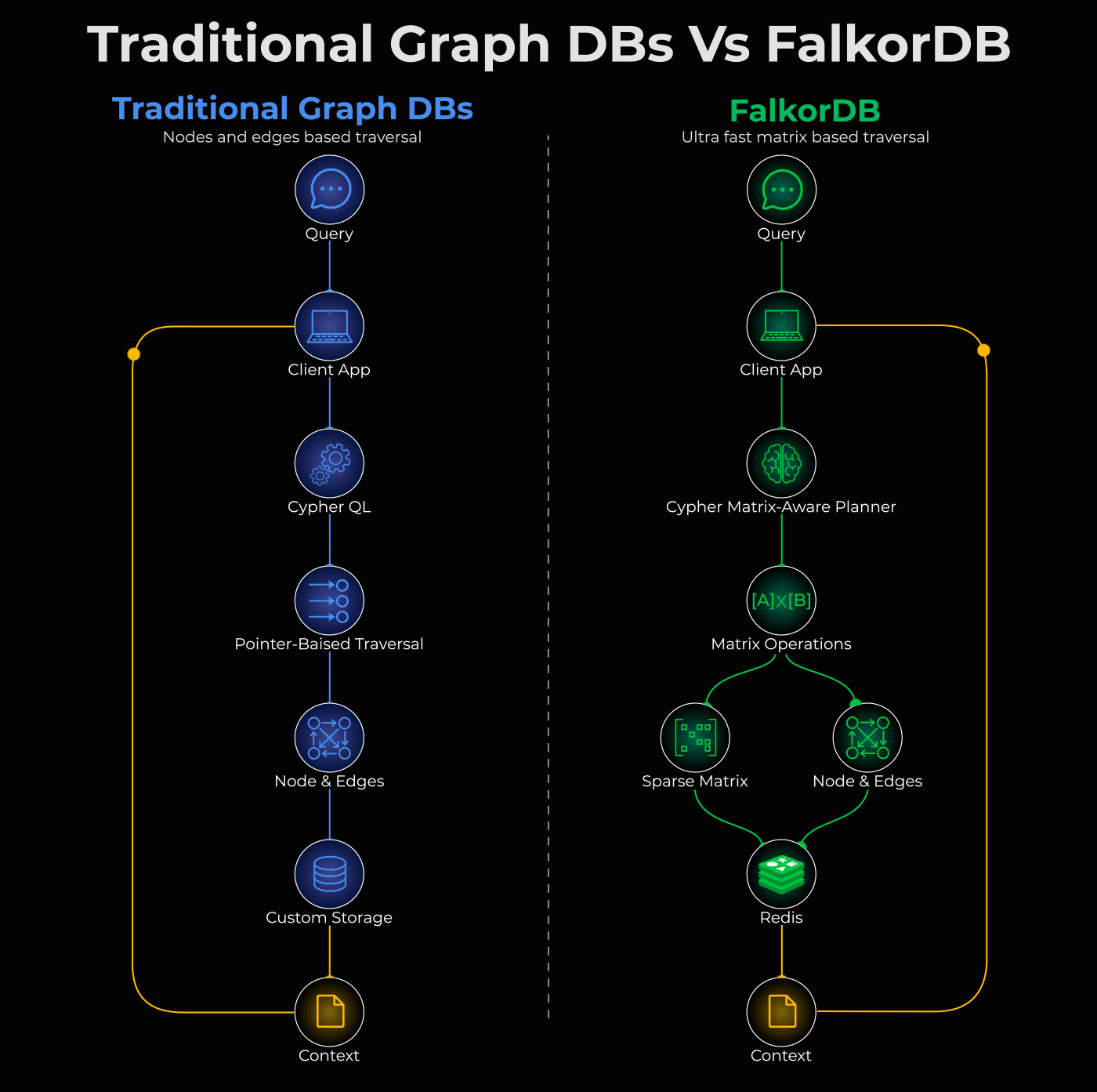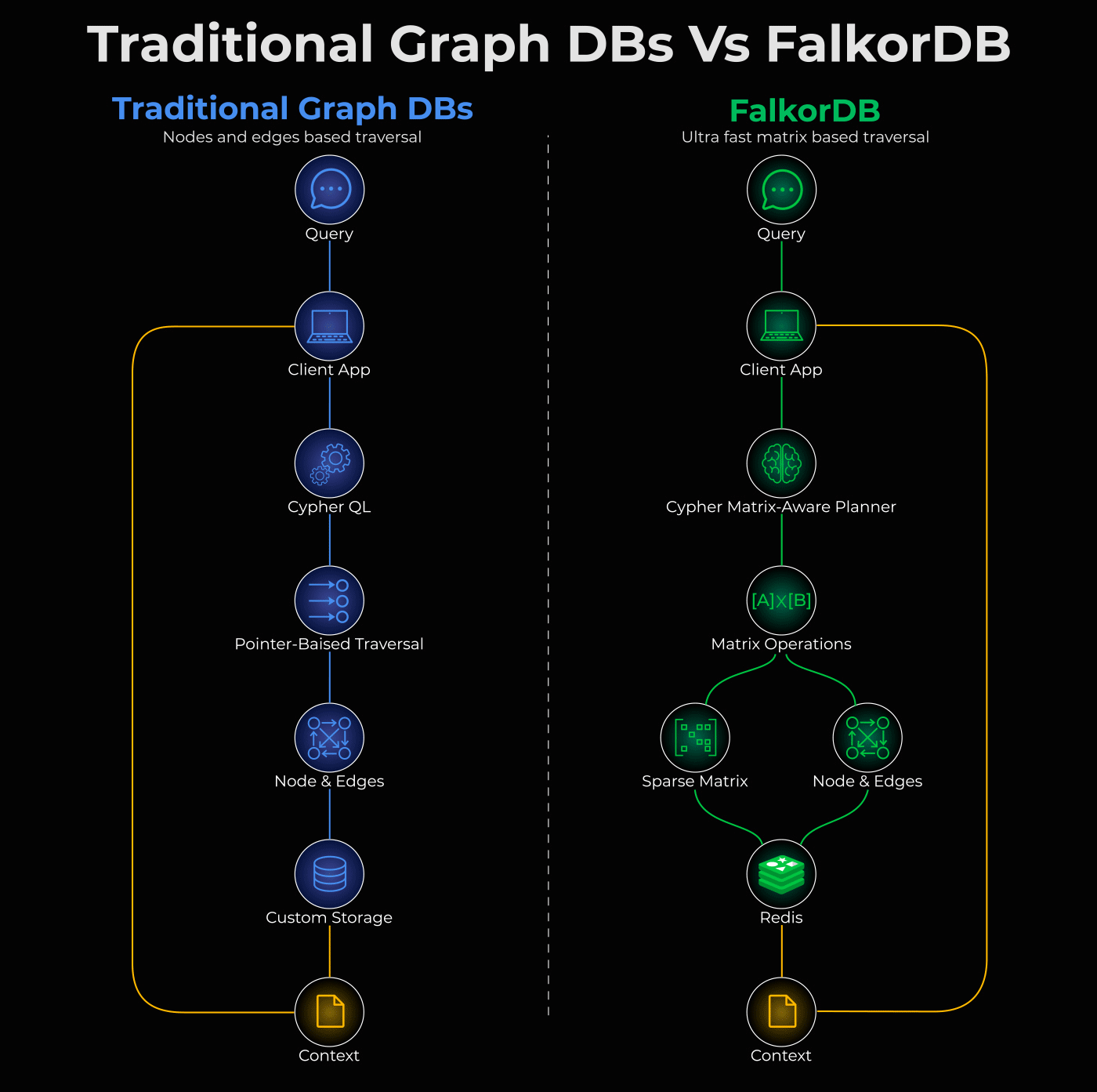
FalkorDB: a different architecture
FalkorDB is 496x faster than Neo4j.
It’s an open-source graph database that represents your entire graph as a sparse matrix. Instead of chasing pointers, it translates traversals into matrix operations and does this in parallel.
Here’s what that means practically:
An example to understand this
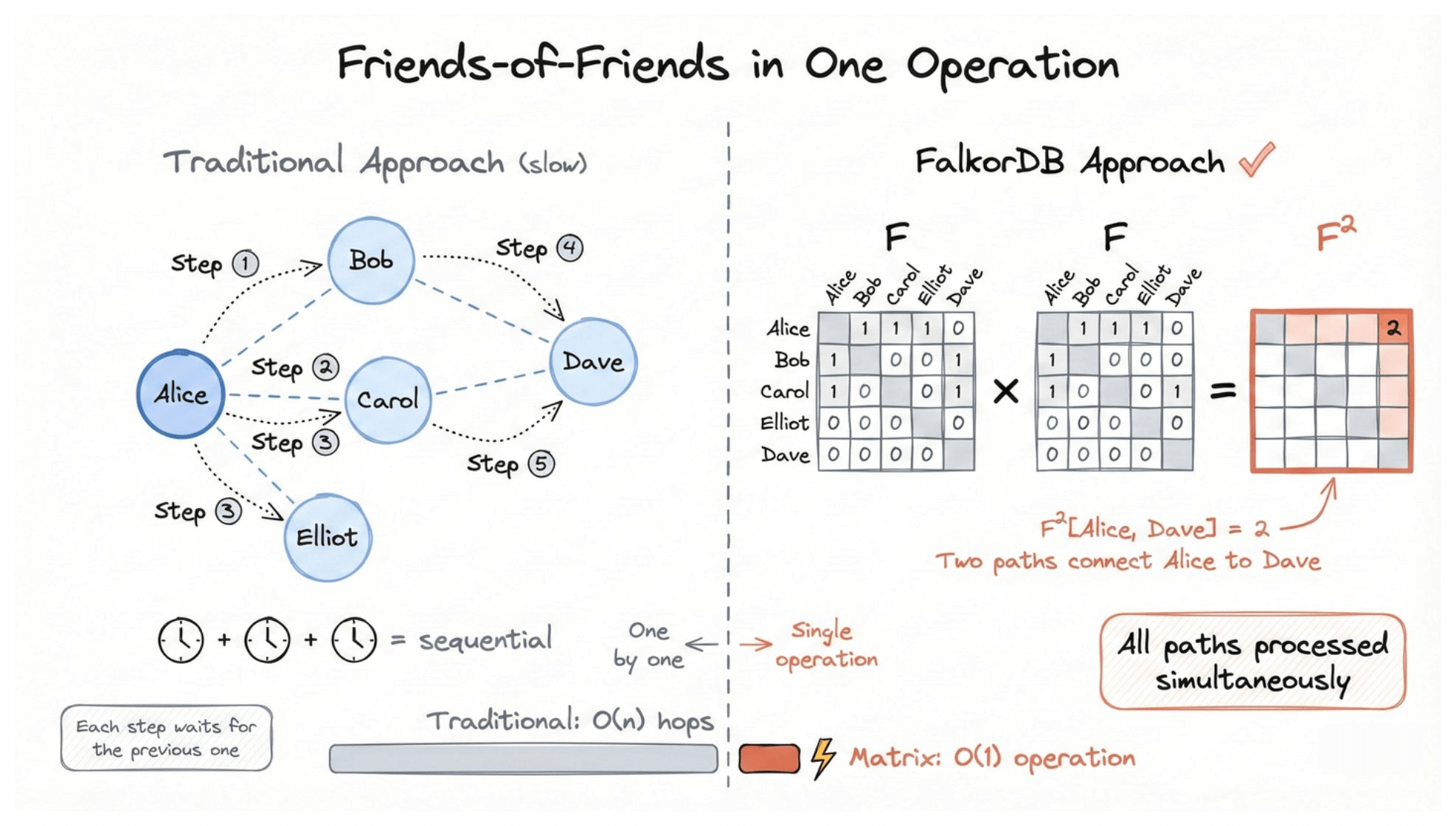
Say you want to find friends-of-friends in a social network. Who are Alice’s friends connected to?
Traditional approach: start at Alice. Find her friends (Bob, Carol, Elliot). For each friend, find their friends. Combine results. Each step is sequential.
FalkorDB approach: represent the social graph as a matrix F where position [i,j] = 1 if person i is friends with person j. Finding friends-of-friends becomes a single matrix multiplication:
F × F = F²
The result F²[Alice, Dave] = 2 tells you there are exactly two paths connecting Alice to Dave, even though they’re not directly connected.
Instead of following connections one by one, the CPU processes all paths simultaneously.
Check this out:
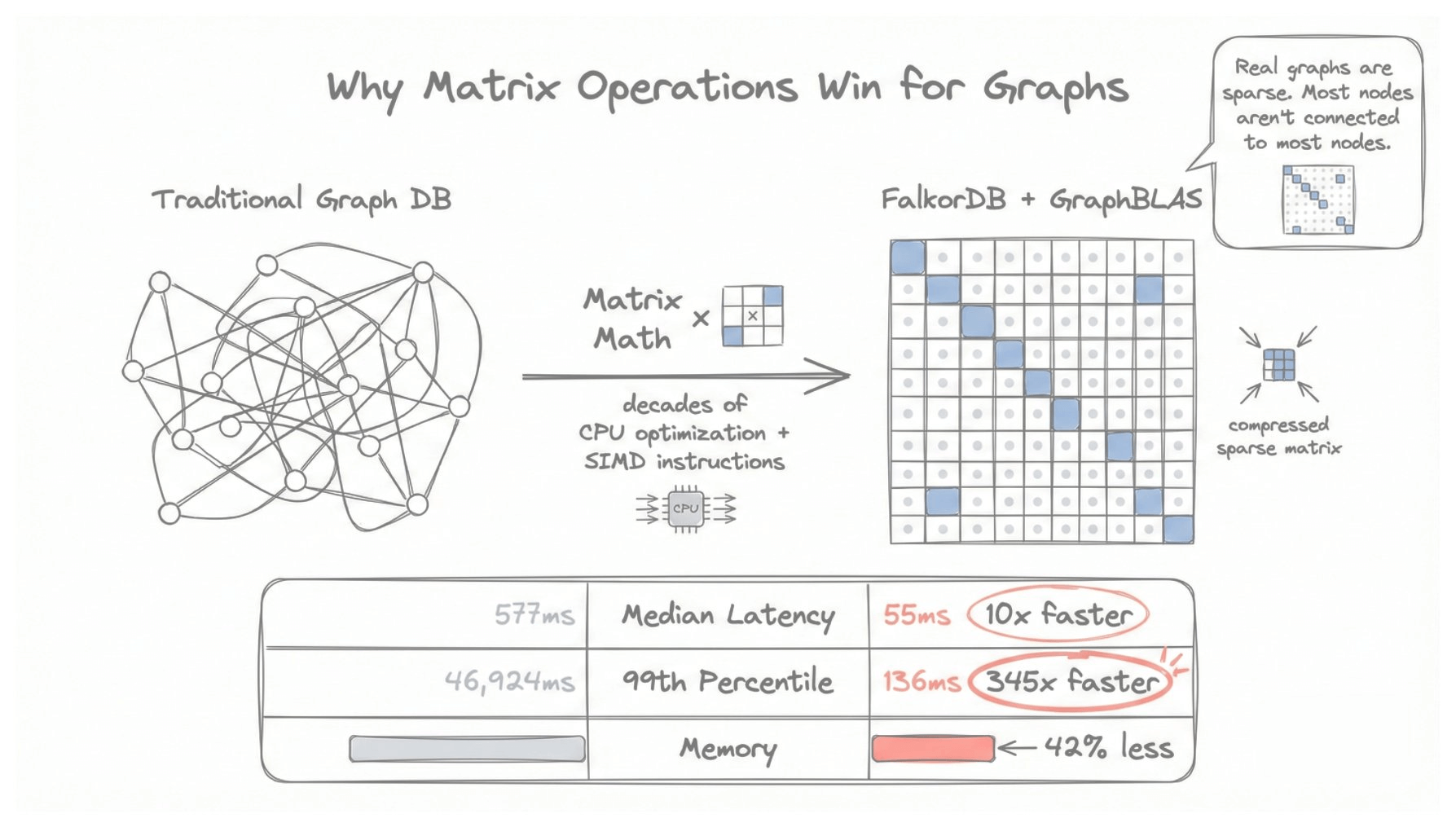
Why this is fast
Matrix operations have been optimized for decades. Modern CPUs have specialized SIMD instructions for exactly this.
FalkorDB uses GraphBLAS under the hood, the same math that powers high-performance scientific computing.
Plus, real-world graphs are sparse. Most people don’t follow most people. Most products aren’t related to most products. FalkorDB’s compressed sparse matrix format stores only what exists.
The performance difference is dramatic:
median latency: 55ms vs 577ms (10x faster)
99th percentile: 136ms vs 46,924ms (345x faster)
memory usage: 42% less
Even under extreme load, FalkorDB maintains sub-140ms response times.
Getting started
Spin up FalkorDB locally:

You get the database on port 6379 and a browser UI on localhost:3000.
Install the Python client:

Let’s create a graph for an e-commerce store:
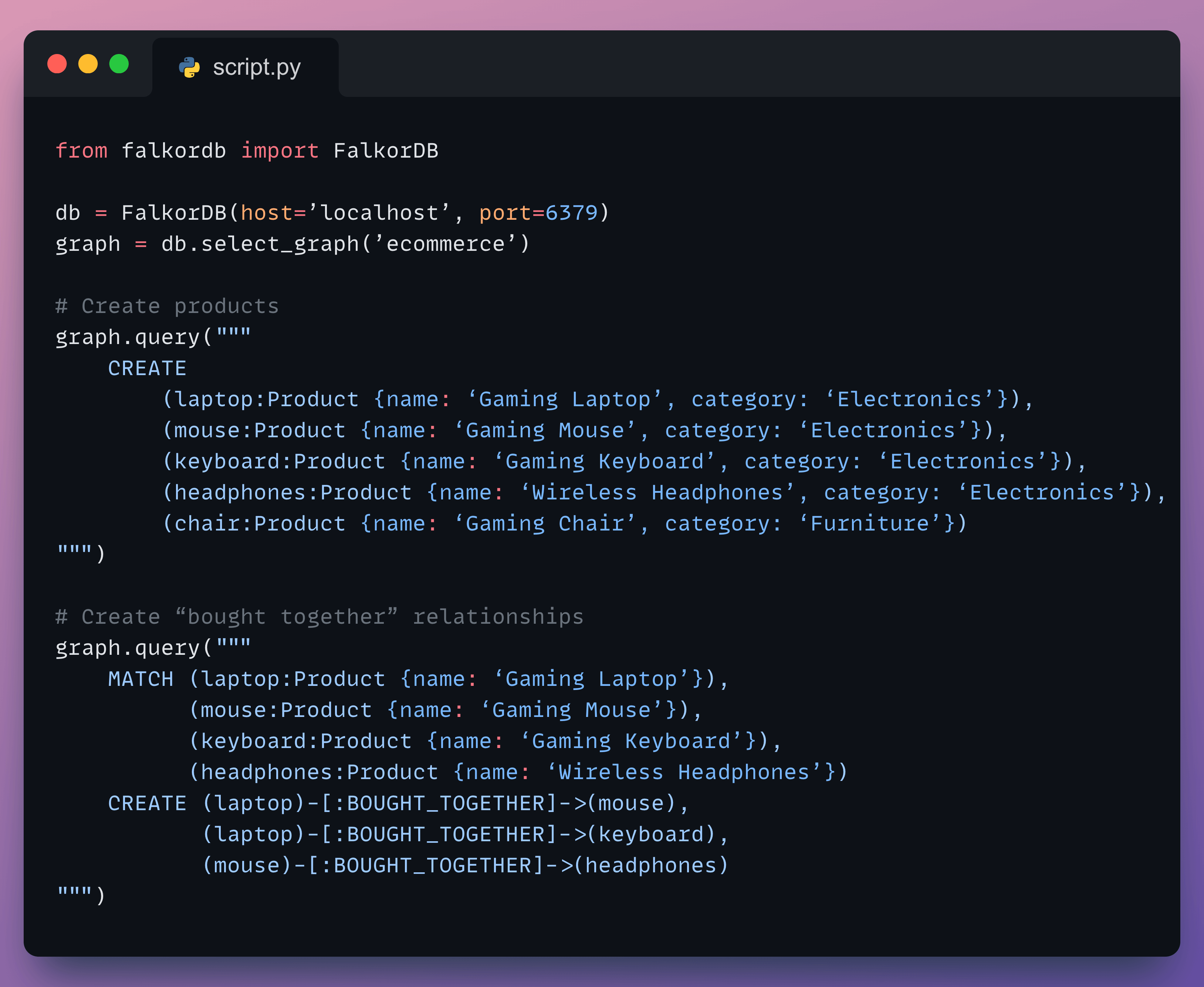
Our graph has been created successfully:
Now find products frequently bought with a gaming laptop:
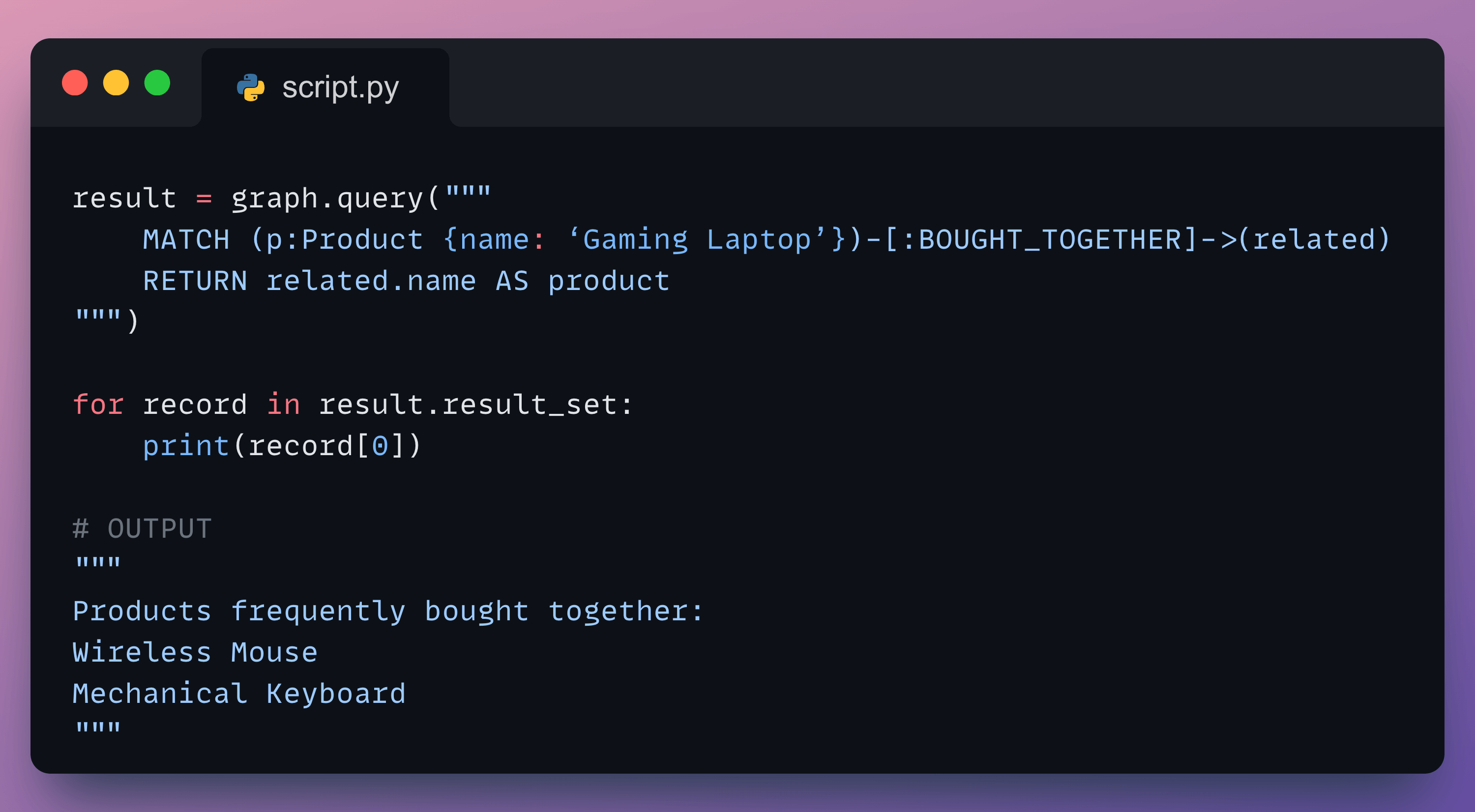
The query language is OpenCypher, it reads more intuitively than SQL for relationship queries.
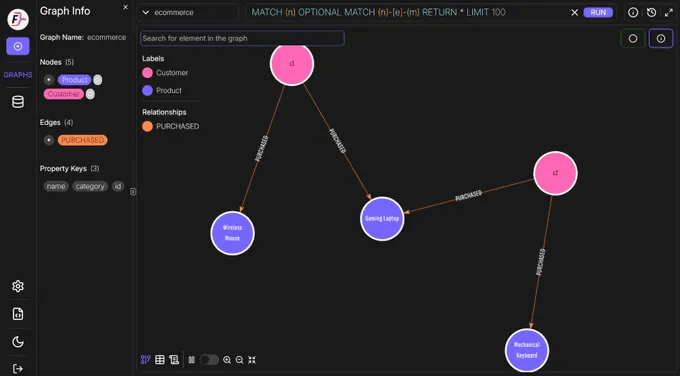
We can confirm the correctness of the result from our graph.
Check this out:
UDFs: extending FalkorDB with custom functions
OpenCypher covers the basics. But what about specialized logic?
Maybe you need custom similarity scoring for recommendations or fraud detection rules that reflect your company’s unique risk patterns.
User-defined functions (UDFs) let you write JavaScript functions with access to node neighbors, properties, and paths.
FalkorDB FLEX provides pre-built UDFs for common tasks.
Example: fuzzy matching for user search. Someone types “Alcie” instead of “Alice.”
Without FLEX, you’ll have to write some custom matching logic:
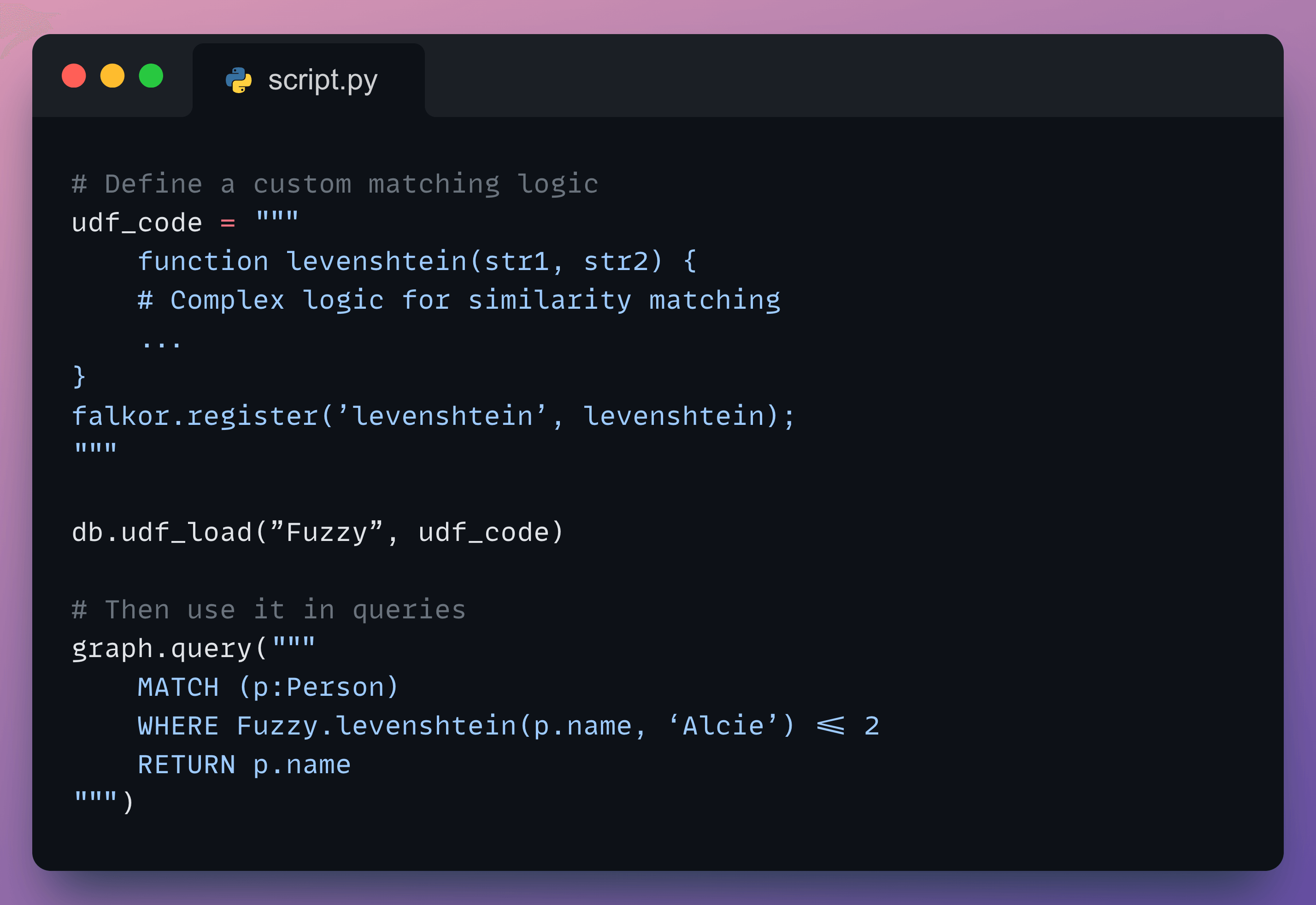
with FLEX:
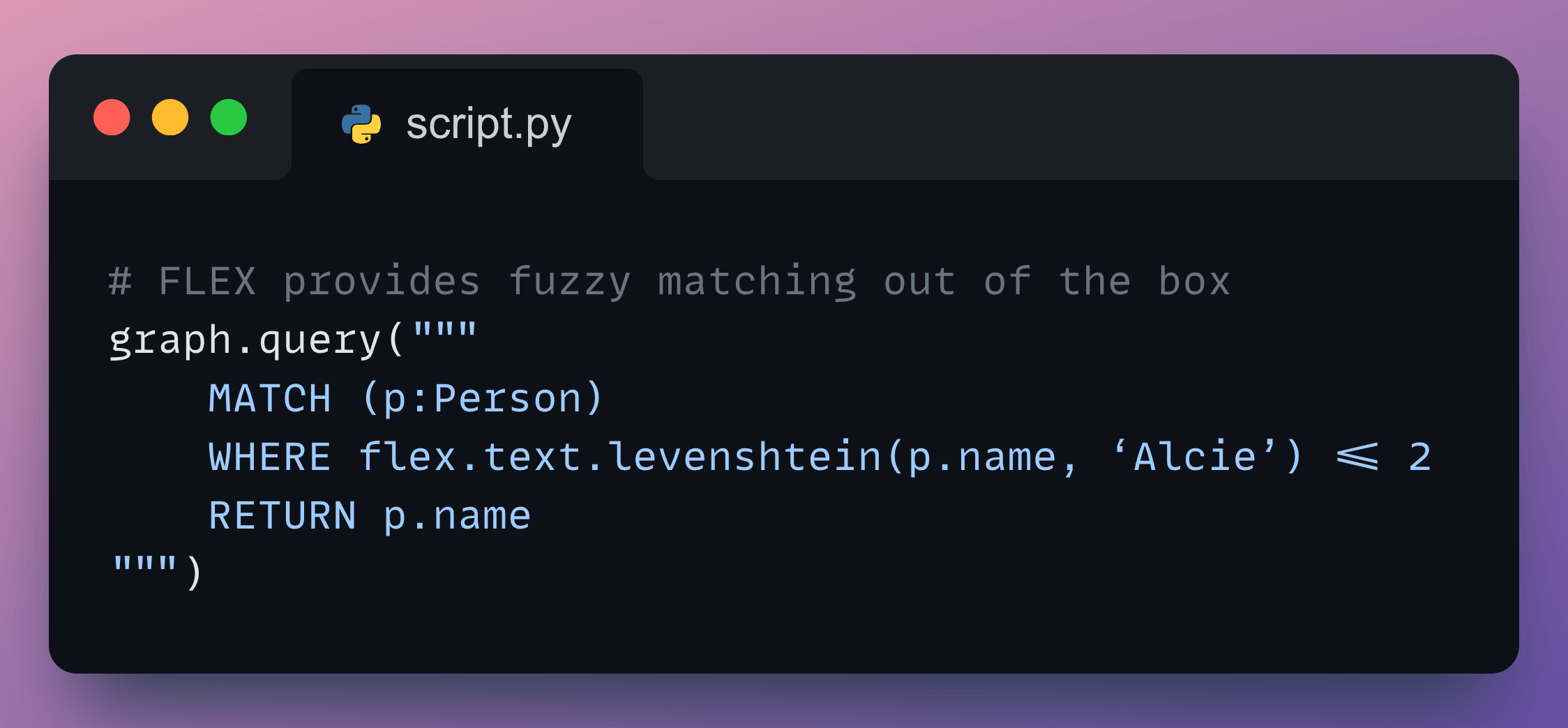
FLEX includes functions for:
string matching (fuzzy, phonetic, regex)
data cleaning and normalization
statistical operations
time series analysis
No custom code required.
Multi-tenancy for SaaS
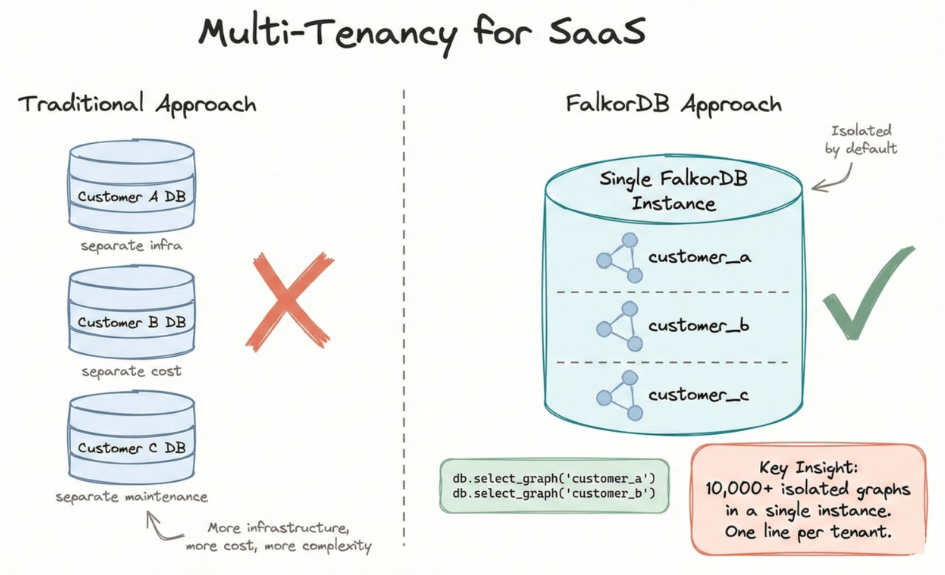
If you are building a SaaS product, each customer needs isolated data storage.
Traditional approach: spin up a separate database per customer. more infrastructure, more cost, more complexity.
FalkorDB supports 10,000+ isolated graphs in a single instance:
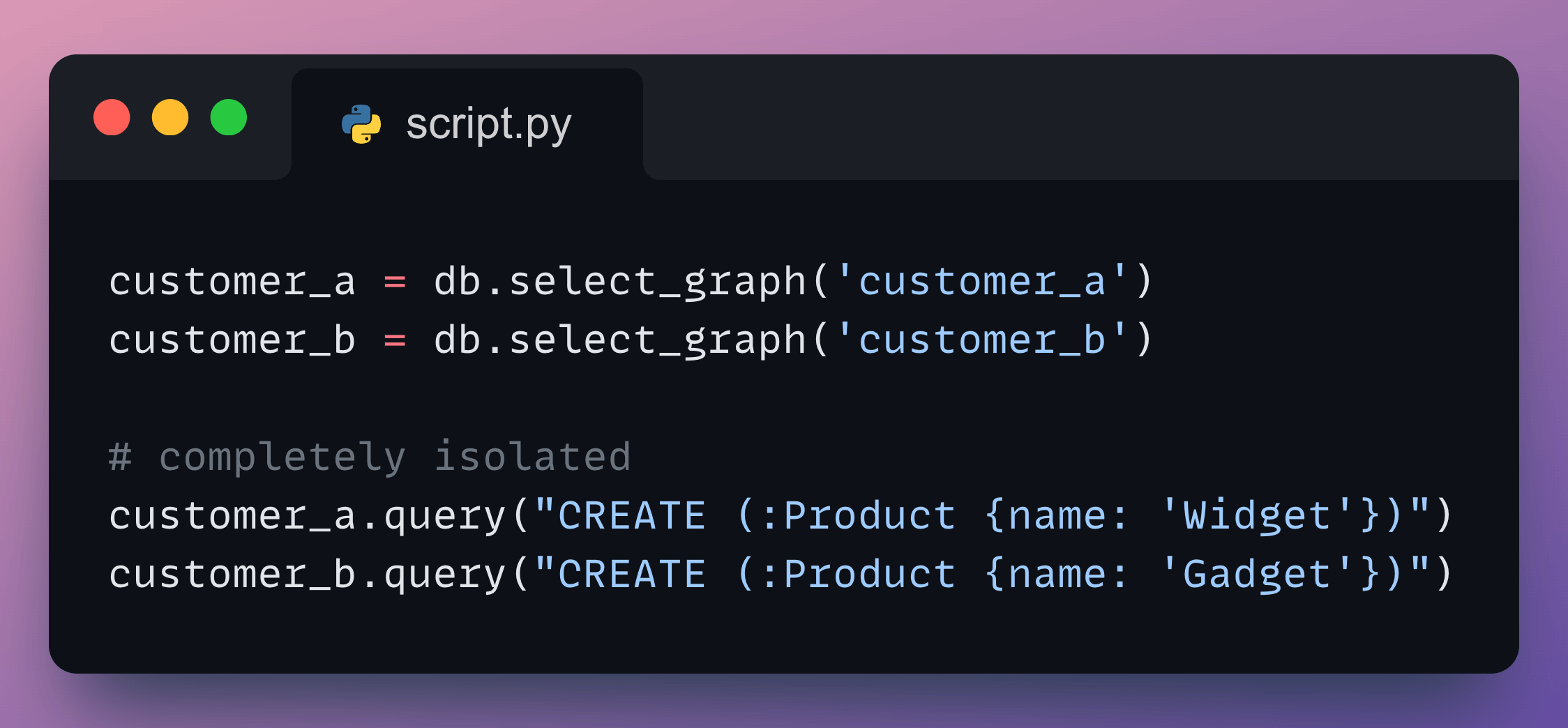
One line per tenant and isolated by default.
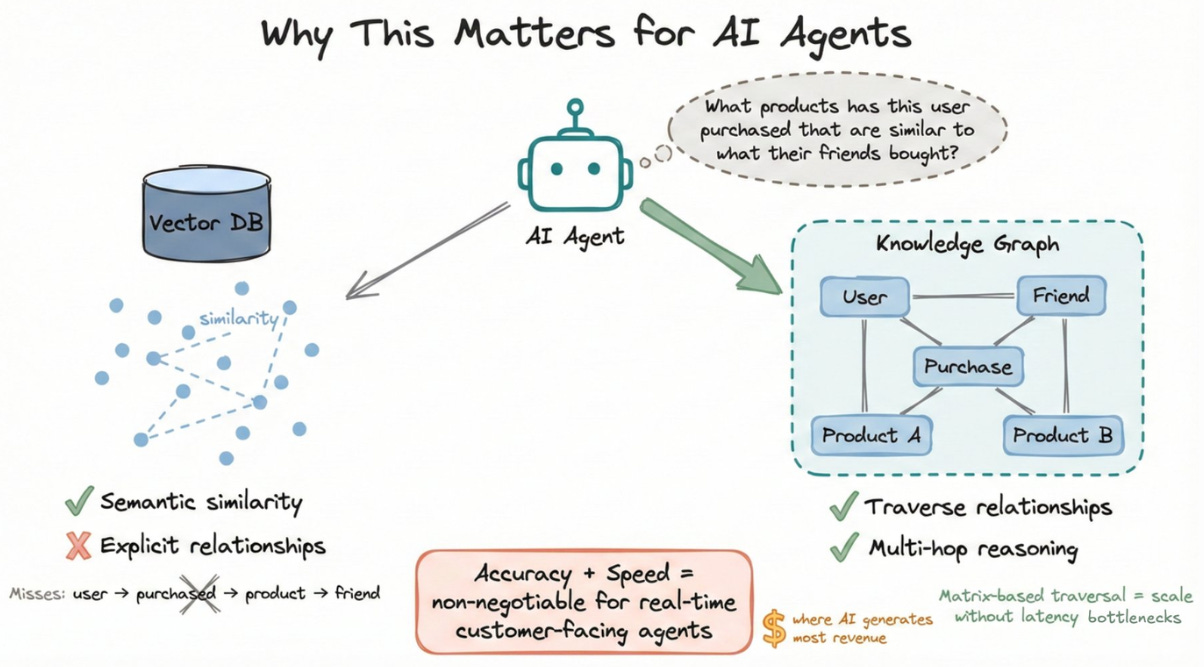
Why this matters for AI agents
Vector databases capture semantic similarity. But they miss explicit relationships.
When your agent asks “what products has this user purchased that are similar to what their friends bought?” that requires traversing relationships, not just embedding similarity.
Knowledge graphs fill that gap.
And when your agent needs multi-hop reasoning across thousands of connected entities, matrix-based traversal means you can scale without latency bottlenecks.
TL;DR
FalkorDB takes a fundamentally different approach on how to working with graphs:
matrix-based traversals that stay fast as your graph grows
sub-100ms response times at scale
built-in UDFs through FLEX
native multi-tenancy for SaaS
full OpenCypher compatibility
FalkorDB is 100% open-source.
You can find the GitHub repo here → (don’t forget to star 🌟)
If you want to go deeper, FalkorDB’s team is running a hands-on workshop on building with UDFs, FLEX, and graph databases.
Thanks for reading.