
Why Your Random Forest May Not Need an Explicit Validation Set for Evaluation
A guide to out-of-bag validation — what it is, its benefits and some considerations.

After training an ML model on a training set, we always keep a held-out validation/test set for evaluation.
I am sure you already know the purpose, so we won’t discuss that.
But do you know that random forests are an exception to that?
In other words, one can somewhat “evaluate” a random forest using the training set itself.
Let’s understand how.
To recap, a random forest is trained as follows:
First, we create different subsets of data with replacement (this process is called bootstrapping).
Next, we train one decision tree per subset.
Finally, we aggregate all predictions to get the final prediction.
This process is depicted below:

If we look closely above, every subset has some missing data points from the original training set.
We can use these observations to validate the model.
This is also called out-of-bag validation.
Calculating the out-of-bag score for the whole random forest is simple too.
But one thing to remember is that we CAN NOT evaluate individual decision trees on their specific out-of-bag sample and generate some sort of “aggregated score” for the entire random forest model.
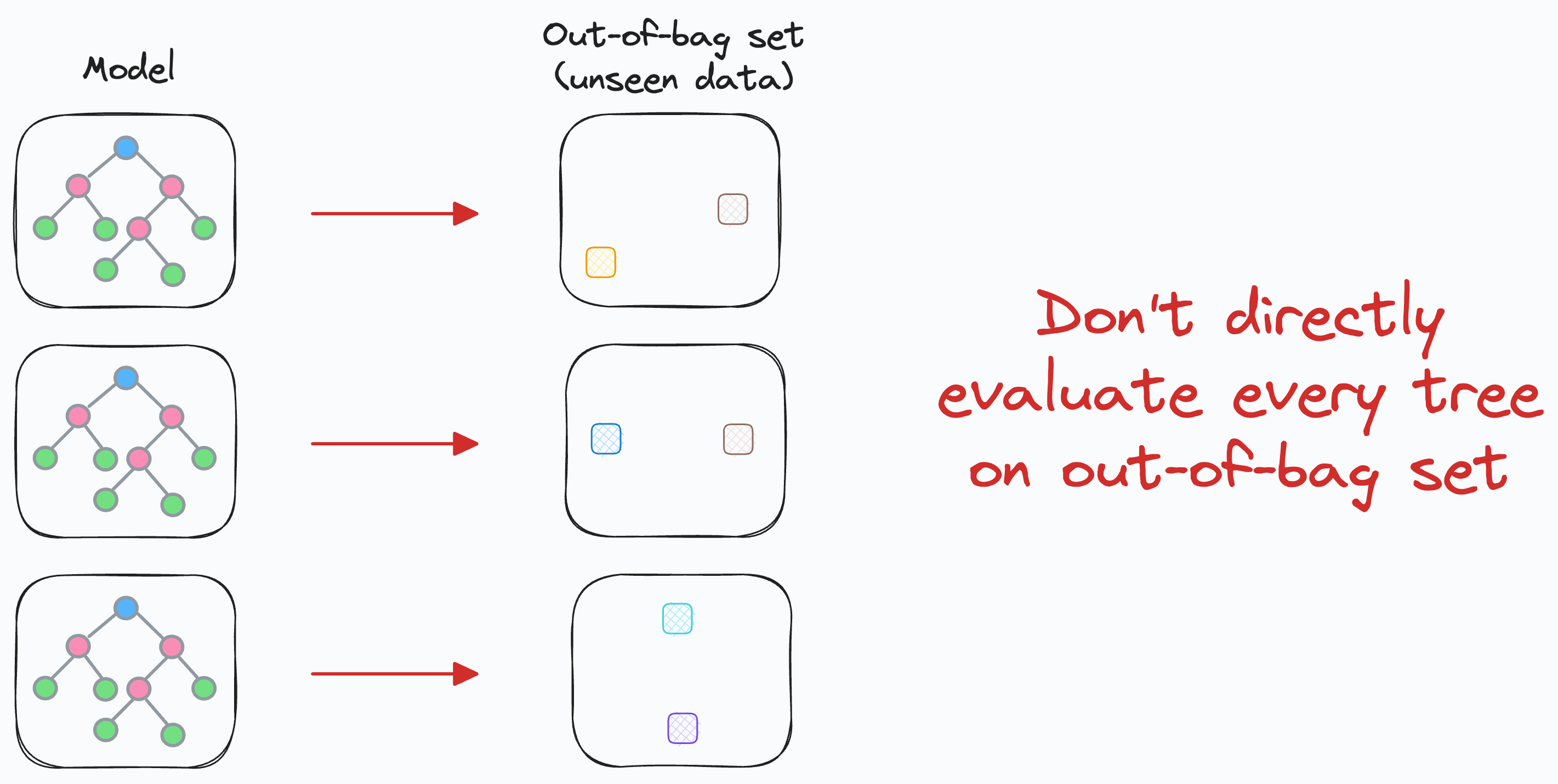
This is because a random forest is not about what a decision tree says individually.
Instead, it’s about what all decision trees say collectively.
So here’s how we can generate the out-of-bag score for the random forest model.
For every data point in the training set:
Gather predictions from all decision trees that did not use it as a training data point.
Aggregate predictions to get the final prediction.
For instance, consider a random forest model with 5 decision trees → (P, Q, R, S, T).
Say a specific data point X was used as a training observation in decision trees P and R.

So we shall gather the out-of-bag prediction for data point X from decision trees Q, S and T.
After obtaining out-of-bag predictions for all samples, we score them to get the out-of-bag score.
Done!
See…this technique allowed us to evaluate a random forest model on the training set.
Of course, I don’t want you to blindly adopt out-of-bag validation without understanding some of its advantages and considerations.
I have found out-of-bag validation to be particularly useful in the following situations:
In low-data situations, out-of-bag validation prevents data splitting whilst obtaining a good proxy for model validation.
In large-data situations, traditional cross-validation techniques are computationally expensive. Here, out-of-bag validation provides an efficient alternative. This is because, by its very nature, even cross-validation provides an out-of-fold metric. Out-of-bag validation is also based on a similar principle.
And, of course, an inherent advantage of out-of-bag validation is that it guarantees no data leakage.
Luckily, out-of-bag validation is also neatly tied in sklearn’s random forest implementation.

The most significant consideration about out-of-bag score is to use it with caution for model selection, model improvement, etc.
This is because if we do, we typically tend to overfit the out-of-bag score as the model is essentially being tuned to perform well on the data points that were left out during its training.
And if we consistently improve the model based on the out-of-bag score, we obtain an overly optimistic evaluation of its generalization performance.
If I were to share just one lesson here based on my experience, it would be that if we don’t have a true (and entirely different) held-out set for validation, we will overfit to some extent.
The decisions made may be too specific to the out-of-bag sample and may not generalize well to new data.
👉 Over to you: What other considerations would you like to add here about out-of-bag validation?
👉 Read this deep dive next to learn why Bagging is so effective at variance reduction: Why Bagging is So Ridiculously Effective At Variance Reduction?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed:
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Daily Dose is a daily habit for me, keep em coming!