
Will Long-Context LLMs Make RAG Obsolete?
Insights from latest trends and research.

In today's newsletter:
Declarative Data Infrastructure for Multimodal AI
[Hands-on] Package AI/ML Projects with KitOps MCP Server.
Will long-context LLMs make RAG obsolete?
Declarative Data Infrastructure for Multimodal AI
Pixeltable is the only open-source Python library that lets you define your entire multimodal workflow (from storage to transformation to inference) as computed columns on a table.
It automates the data plumbing, versioning, and incremental updates, letting you focus on logic instead of complex pipelines.

What this means for you:
Incremental computation: Only processes changes, saving time and cost.
Automatic versioning: Full lineage tracking for reproducibility.
Unified system: Handles data, transformations, and AI models in one place.
Focus on your application logic, not the infrastructure.
Fully open-source.
GitHub repo → (don’t forget to star)
Package AI/ML Projects with KitOps MCP Server
ML projects aren’t just code.
They are code + datasets + model weights + parameters + config, and whatnot!
Docker isn’t well-suited to package them since you cannot selectively pull what you need.
And GitHub enforces size limits.
To solve this, we recently built an MCP server that all AI/ML Engineers will love.
The video below gives a detailed walk-through.
We created ModelKits (powered by open-source KitOps) to package an AI/ML project (models, datasets, code, and config) into a single, shareable unit.
Think of it as Docker for AI, but smarter.
While Docker containers package applications, ModelKits are purpose-built for AI/ML workflows.
Key advantages that we observed:
Lets you selectively unpack kits and skip pulling what you don’t need.
Acts as your private model registry
Gives you one-command deployment
Works with your existing container registry
Lets you create RAG pipelines as well
Has built-in LLM fine-tuning support.
Supports Kubernetes/KServe config generation
We have wrapped up KitOps CLI and their Python SDK in an MCP server, and the video above gives a detailed walkthrough of how you can use it.
Here are the relevant links:
Will long-context LLMs make RAG obsolete?
Consider this:
GPT-3.5-turbo had a context window of 4,096 tokens.
Later, GPT-4 took that to 8,192 tokens.
Claude 2 reached 100,000 tokens.
Llama 3.1 → 128,000 tokens.
Gemini → 1M+ tokens.
We have been making great progress in extending the context window of LLMs.
This raises an obvious question about the relevance of RAG and researchers remain divided on whether long-context LLMs make RAG obsolete.
Today, let’s explore the debate, comparing RAG and long-context LLMs while analyzing academic research.
What is a long-context LLM and RAG?
RAG retrieves relevant information from external sources, while long-context LLMs process extensive input directly within their context windows.
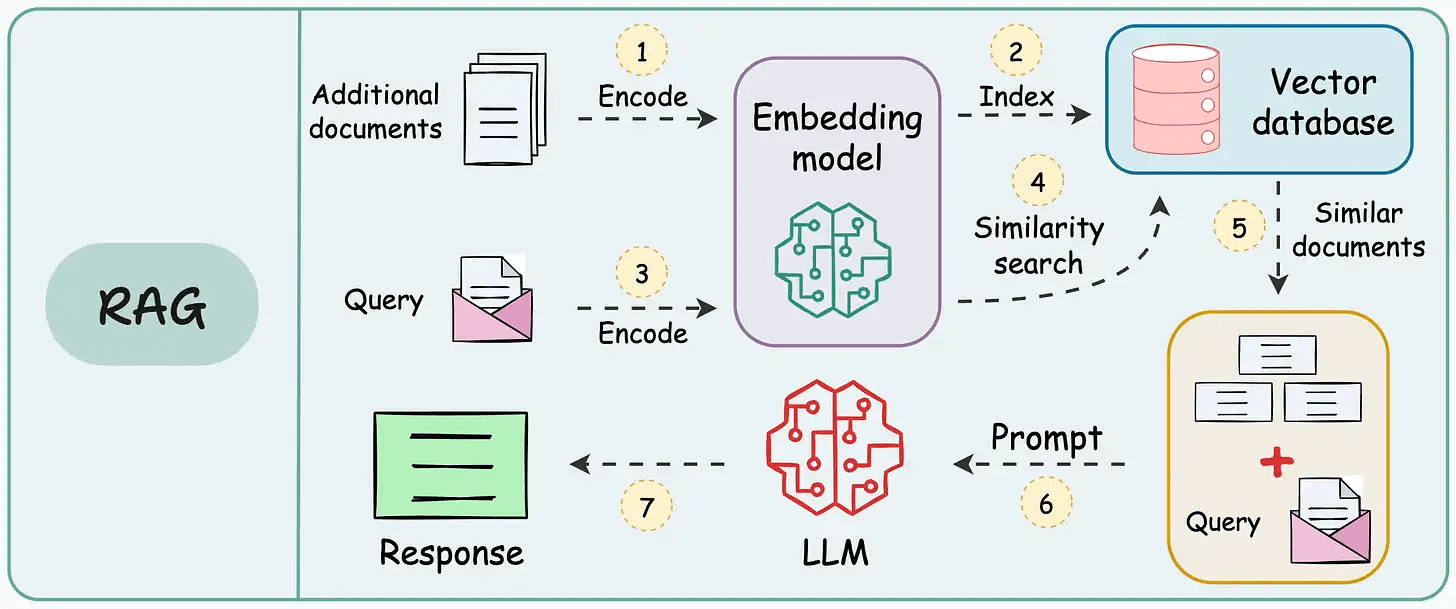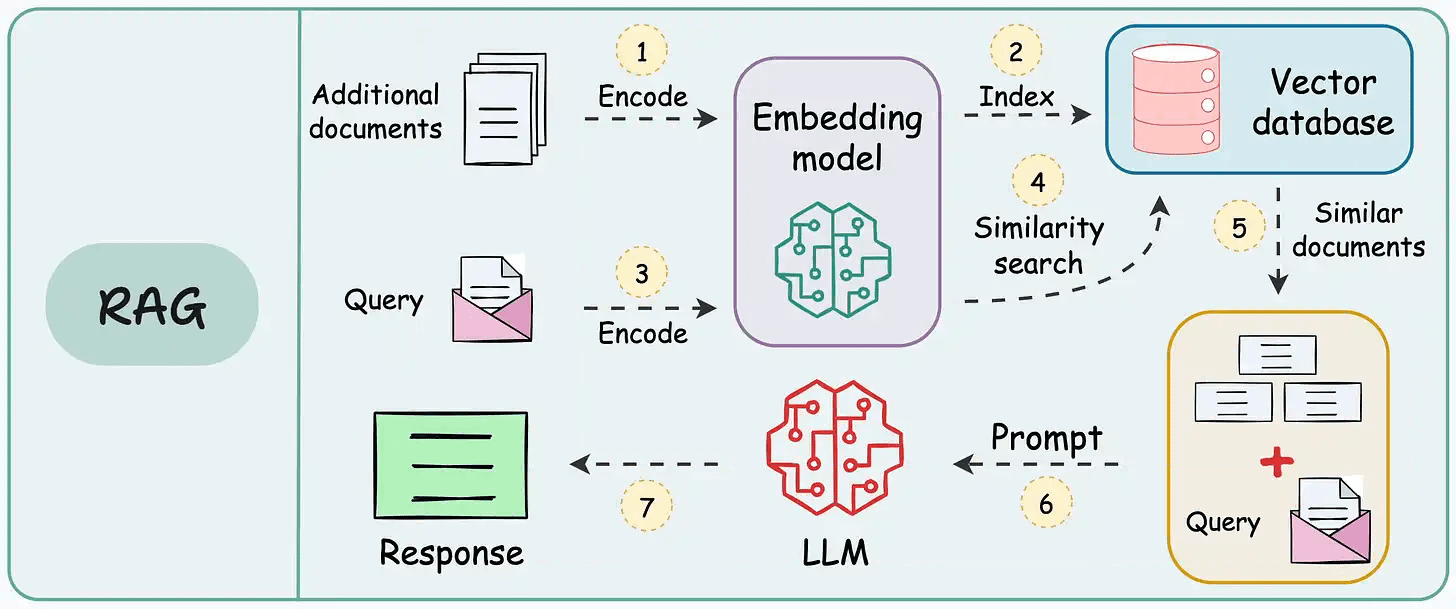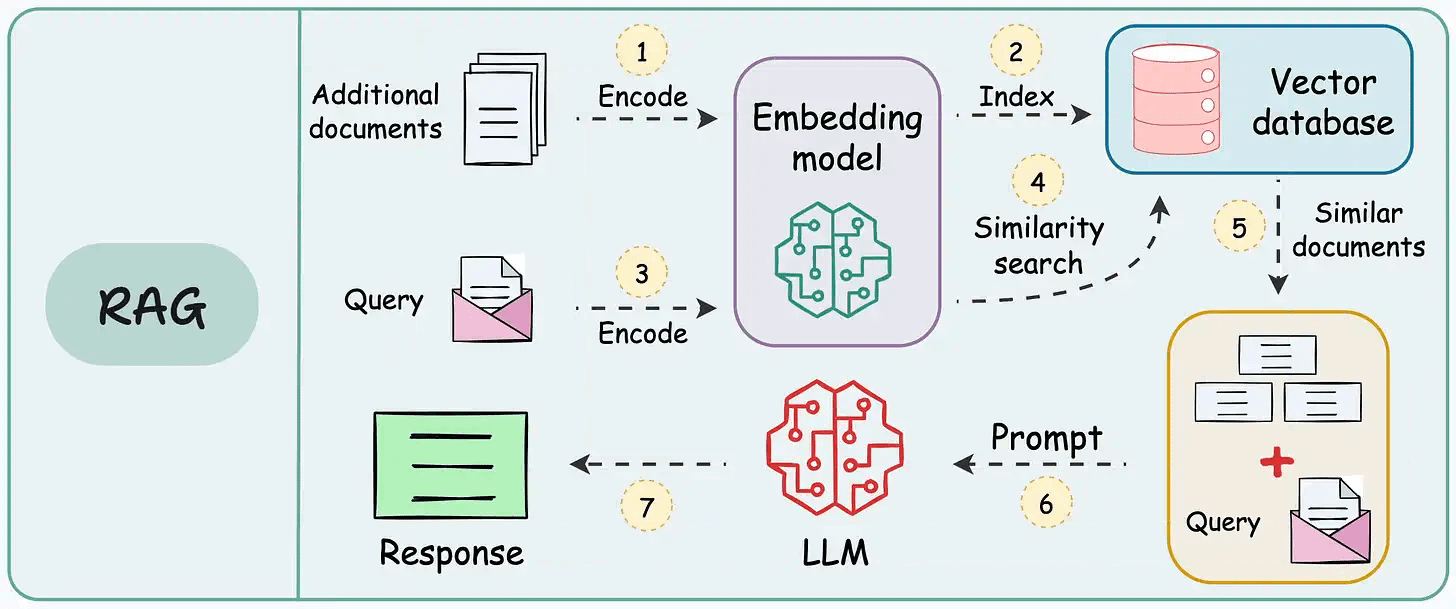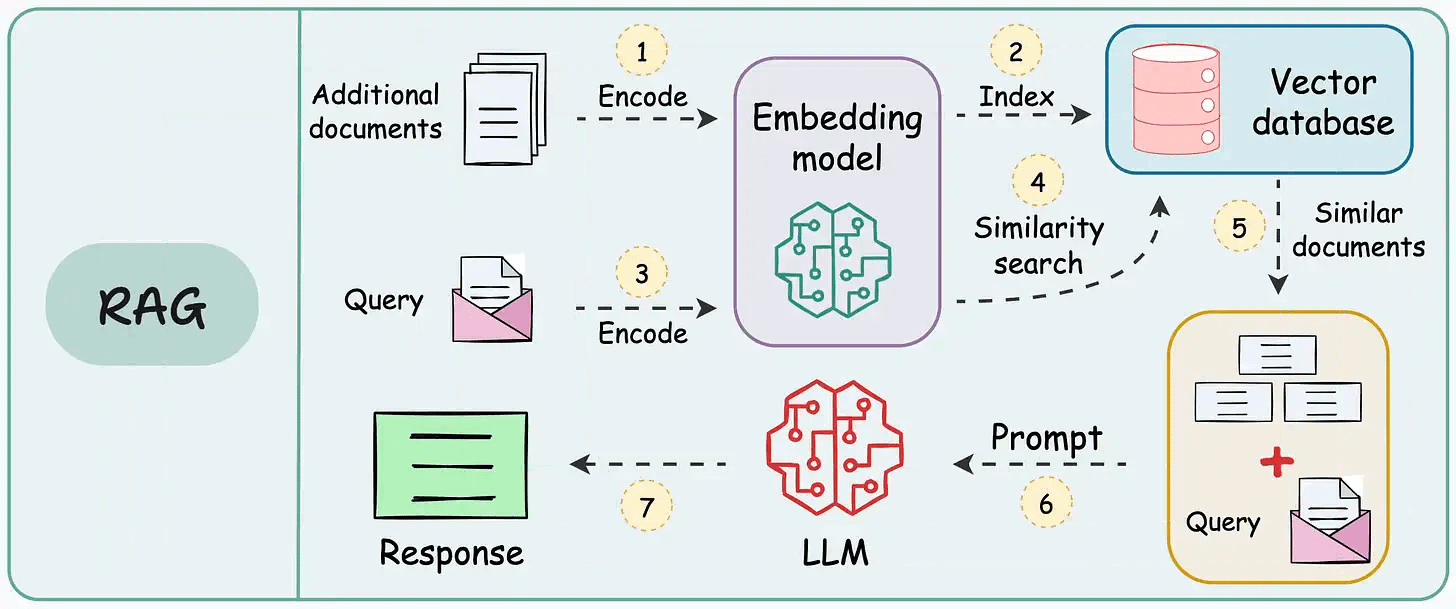
While LLMs can summarize entire documents and perform multi-hop reasoning across passages, RAG excels at handling large-scale, cost-efficient retrieval tasks.
Comparison based on academic research
Paper 1) Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
The LOFT benchmark evaluates retrieval and reasoning tasks requiring up to millions of tokens.
While Gemini 1.5 Pro outperforms the RAG pipeline on multi-hop datasets (e.g., HotpotQA, MusiQue), RAG retains an edge in scalability for larger corpus sizes (1M tokens).

Paper 2) RAG vs. Long Context: Examining Frontier LLMs for Environmental Review
The NEPAQuAD1.0 benchmark evaluates RAG and long-context LLMs on environmental impact statements.

Results show that RAG-driven models outperform long-context LLMs in accuracy, particularly in domain-specific tasks.
Paper 3) A Comprehensive Study and Hybrid Approach
This paper benchmarks RAG and long-context LLMs, emphasizing their strengths. SELF-ROUTE, a hybrid method combining both, reduces costs while maintaining competitive performance.

The trade-off between token percentage and performance highlights RAG’s efficiency at smaller retrieval scales.
Paper 4) ChatQA 2: Bridging Open-Source and Proprietary LLMs
ChatQA 2, based on Llama3, evaluates long-context solutions.

Long-context LLMs perform marginally poor than RAG while also requiring more token context.
Here are some key insights:
Cost efficiency: Handling 200K-1M tokens per request with long-context LLMs can cost up to $20, making RAG a more affordable option for many applications.
Domain-specific knowledge: RAG outperforms in niche areas requiring precise, curated retrieval.
Complementary integration: Most RAG pipelines fail due to poor retrieval, which, in turn, happens due to poor chunking. Combining RAG with long-context LLMs can enhance retrieval and processing efficiency, potentially eliminating the need for chunking or chunk-level recall.
CAG vs. RAG
A recently released mechanism called CAG (cache-augmented generation) has been trending lately.
The core idea is to replace real-time document retrieval with preloaded knowledge in the extended context of LLMs. This approach ensures faster, more accurate, and consistent generation by avoiding retrieval errors and latency.

Key advantages:
Little latency: All data is preloaded, so there’s no waiting for retrieval.
Fewer mistakes: Precomputed values avoid ranking or document selection errors.
Simpler architecture: No separate retriever—just load the cache and go.
Faster inference: Once cached, responses come at lightning speed.
Higher accuracy: The model processes a unified, complete context upfront.
But it also has two major limitations:
Inflexibility to dynamic data
Constrained by the context length of an LLM.
Long-context LLMs offer flexibility but face limitations in cost and scalability. Meanwhile, RAG remains indispensable for large-scale retrieval tasks.
We feel that a hybrid approach that integrates RAG and long-context LLMs could redefine the information retrieval landscape, leveraging the strengths of both systems.
Retrieval will help reduce costs that long-context LLMs alone will incur.
A decent context window still allows the LLM to reason over retrieved chunks more effectively, reducing fragmentation and hallucination.
What is your opinion on this debate? Let us know :)
Thanks for reading!