
Your RAG System Has a Hidden UX Problem
...and an open-source solution to fix this.


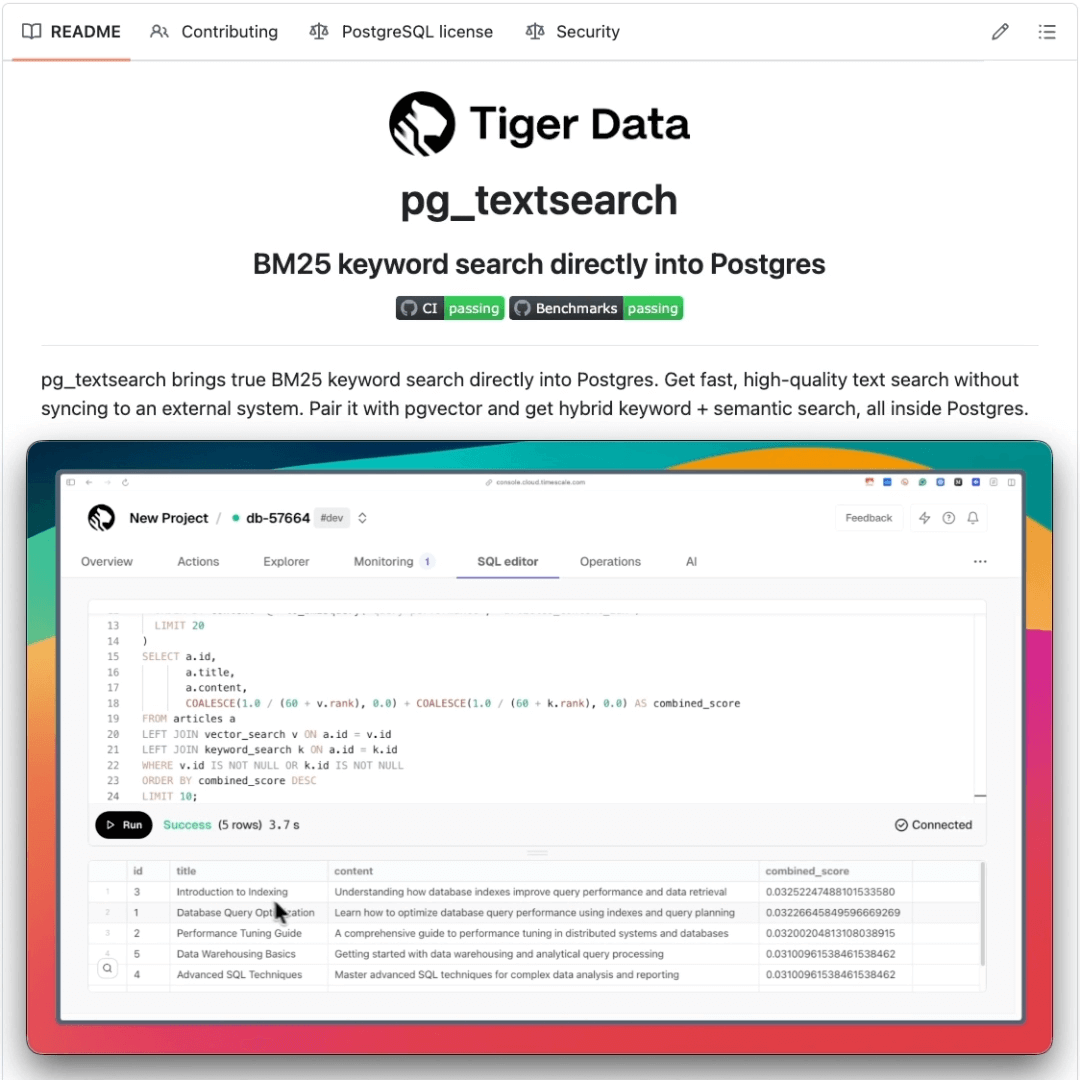
Get BM25 keyword search directly into Postgres!
Search has always been Postgres’s awkward tradeoff.
If you need real relevance ranking, you need to spin up Elasticsearch and maintain sync pipelines forever.
Tiger Data open-sourced pg_textsearch, a Postgres extension that brings true BM25 ranking directly into your database.
BM25 is the algorithm behind Elasticsearch and Lucene, and now it runs natively in Postgres with simple SQL syntax: ORDER BY content <@> 'search terms'.
The bigger story: pg_textsearch pairs naturally with pgvector for hybrid retrieval. Keyword search + vector similarity in one database, which is exactly what RAG apps need.
Fully open-source under the PostgreSQL license.
Thanks to Tiger Data for partnering today!
Your RAG System Has a Hidden UX Problem
Most RAG systems solve retrieval beautifully but break the user experience in a subtle way.
Here’s the disconnect:
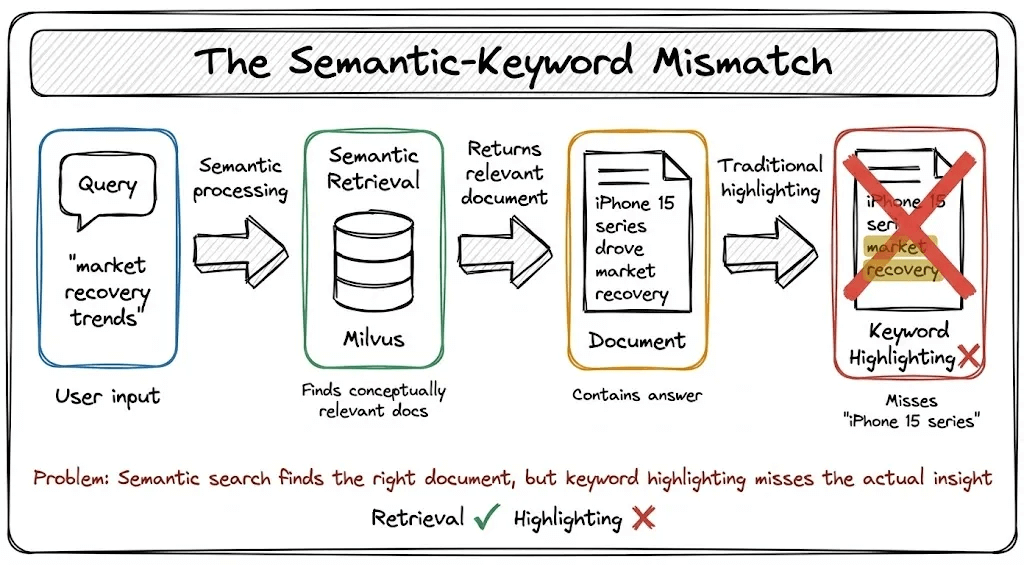
When you search in a modern RAG system, retrieval happens using semantic similarity. The system converts your query and documents into vectors, then finds documents whose meaning is close to what you asked. This works beautifully.
But then comes the user experience problem: once you retrieve a document, how do you show the user which parts are relevant?
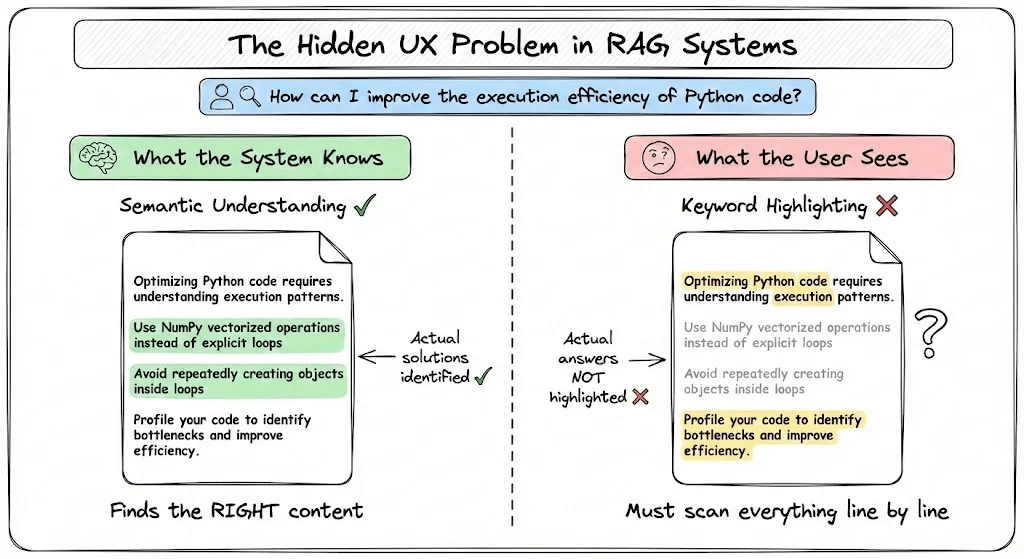
Most systems fall back to keyword highlighting. They simply highlight words that match your query. And this creates a mismatch:
Retrieval: Semantic (meaning-based)
Highlighting: Keyword (exact match)
Your retrieval understands meaning, but your highlighting only understands exact matches.
Later in this article, I’ll show you an open-source model that fixes this.
A Concrete Example
You search for “iPhone performance” in your company’s knowledge base.
The system retrieves a document discussing the A15 Bionic chip, benchmark scores, and zero lag. Perfect. Exactly what you need.
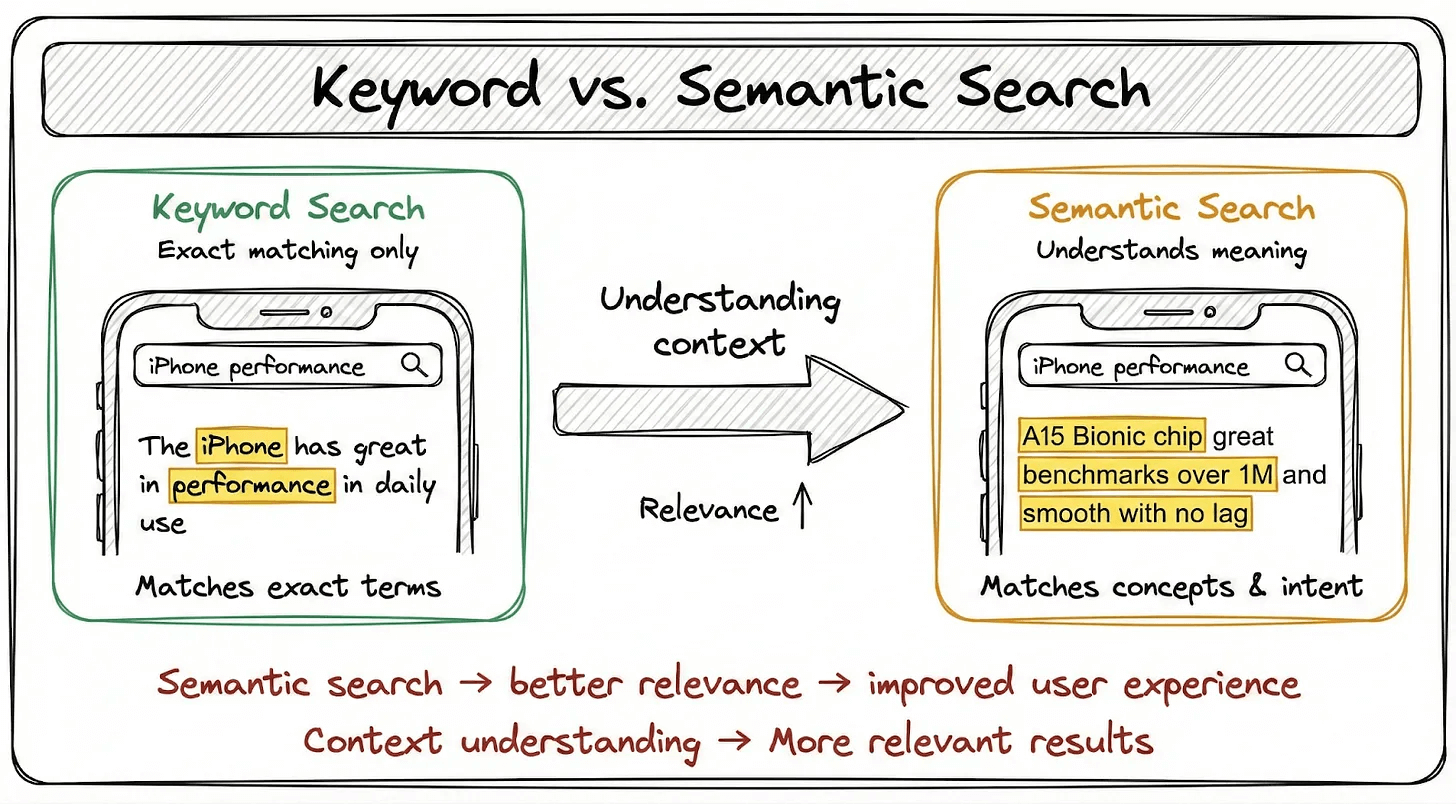
But here’s the problem: none of those words get highlighted.
Why?
Because the document talks about “A15 Bionic chip” and “benchmark scores,” not the literal words “iPhone” or “performance.”
The retrieval understood that these concepts are semantically related. The highlighting didn’t.
The user now has to scan 3,000 words to figure out why this document even showed up.
Why This Matters
Highlighting solves a simple but critical need: helping users quickly see why a result is relevant.
Without it, even a perfectly retrieved document feels broken. The information is there, but the user can’t find it.
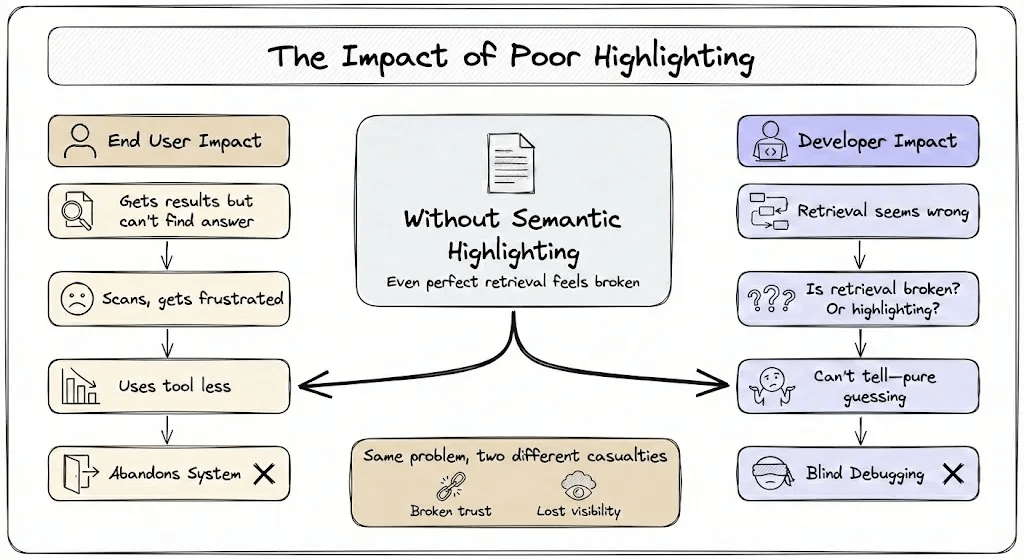
This hurts two groups:
End users lose trust in the system. They receive results but can’t discern their relevance, leading to frustration and eventual abandonment of the tool.
Developers lose visibility into their pipelines. When retrieval seems wrong, is it actually wrong or did highlighting simply fail to surface relevant content? Without semantic highlighting, debugging becomes guesswork.
Why This Gets Worse with AI Agents
The problem compounds when you add AI agents into the mix.
When a user asks an agent: “Analyze recent market trends”
The agent doesn’t search those exact words. It reasons and generates a derived query:
> “Retrieve Q4 2024 consumer electronics sales data, year-over-year growth rates, supply chain cost fluctuations.”
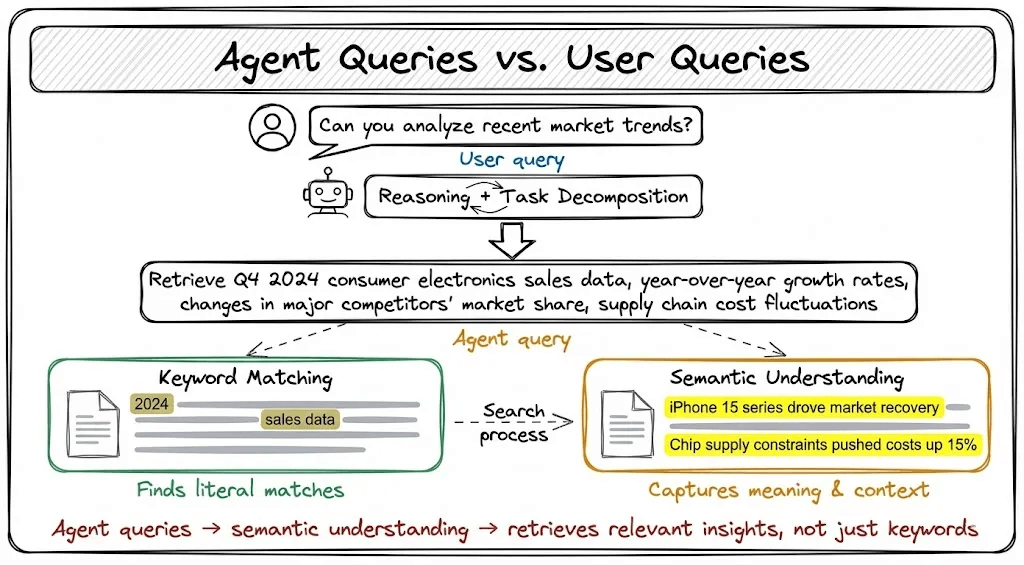
The system retrieves documents with genuinely valuable content:
“iPhone 15 series drove broader market recovery”
“Chip supply constraints pushed costs up 15%”
Traditional highlighting marks generic terms like “2024” and “sales data,” but the actually insightful sentences receive no highlighting at all due to zero keyword overlap.
The Solution: Semantic Highlighting
Semantic highlighting identifies text spans that are semantically aligned with the query, not just keyword matches.
Instead of highlighting “iPhone” and “performance,” it highlights “A15 Bionic chip,” “benchmark scores,” and “zero lag.”
Instead of marking “2024” and “sales data,” it highlights the sentences that actually answer what market trends look like.
The concept is simple, but the implementation presents significant technical challenges.
Why Not Just Use an LLM?
Obvious solution: have GPT-4 identify relevant spans.
The problem is latency and cost.

Highlighting happens on every query, across multiple documents. You need results in milliseconds. Running an LLM call for every highlight operation would destroy response times and explode your API costs.
What you need is a small, specialized model that:
Understands semantic relevance (not just keywords)
Runs fast enough for real-time use
Generalizes across different domains
Existing Solutions Fall Short
Several teams have tried building semantic highlighting models:
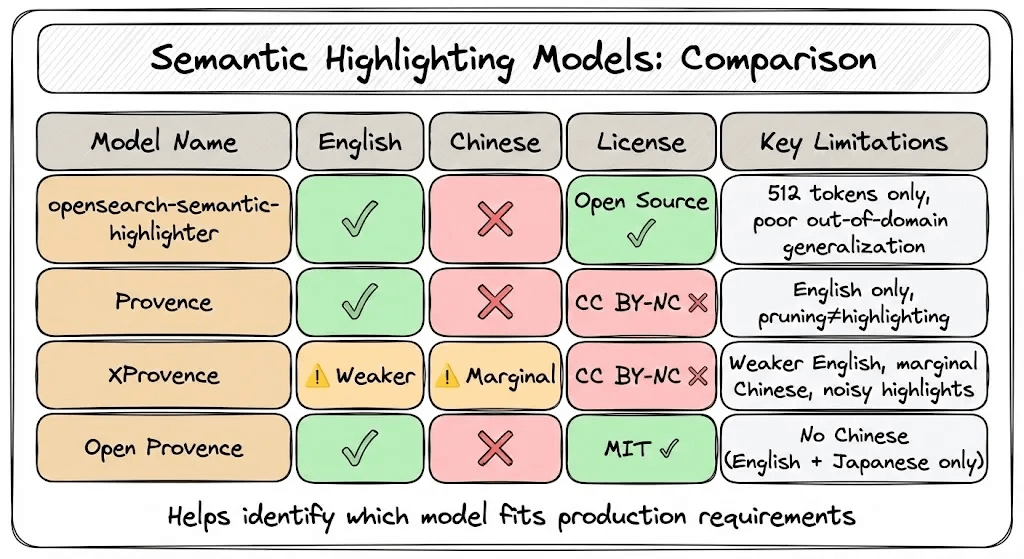
opensearch-semantic-highlighter: Limited to 512 tokens with out-of-domain F1 dropping from 0.72 to 0.46, and supports English only.
Provence/XProvence: Built for pruning rather than highlighting, which produces noisy results with weaker multilingual performance and a CC BY-NC license that prohibits commercial use.
Open Provence: Supports English and Japanese only, with no Chinese capability.
None of them meet production requirements for precision, latency, multilingual support, and licensing.
A New Approach from Zilliz
The team at Zilliz built a semantic highlighting model from scratch with production requirements in mind:
Key features:
8K context window to handle long documents
Bilingual support for English and Chinese
Strong generalization that works across domains
MIT licensed for commercial use
Fast inference with millisecond-level responses
How they trained it
The key challenge was building high-quality training data.
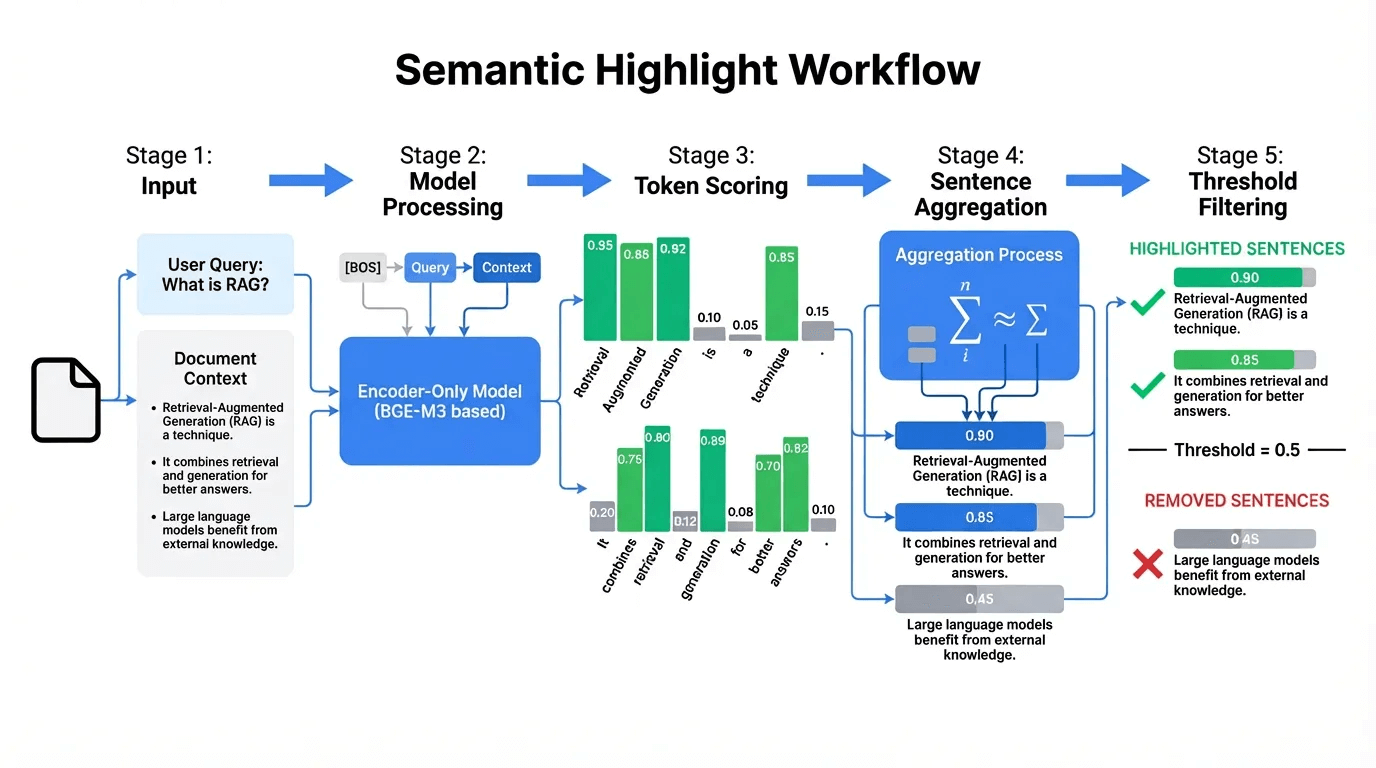
They prompted Qwen3 8B to generate highlight spans and explain its reasoning
This reasoning step acted as a built-in quality check, producing more consistent labels
After filtering low-quality samples, they distilled the knowledge into a smaller model (BGE-M3 Reranker, 0.6B parameters)
Training took about 5 hours on 8x A100 GPUs
The result: Over 1 million bilingual samples and a small model with LLM-level understanding that runs at production speed.
The Results
The model was tested across four datasets to measure both in-domain and out-of-domain performance.
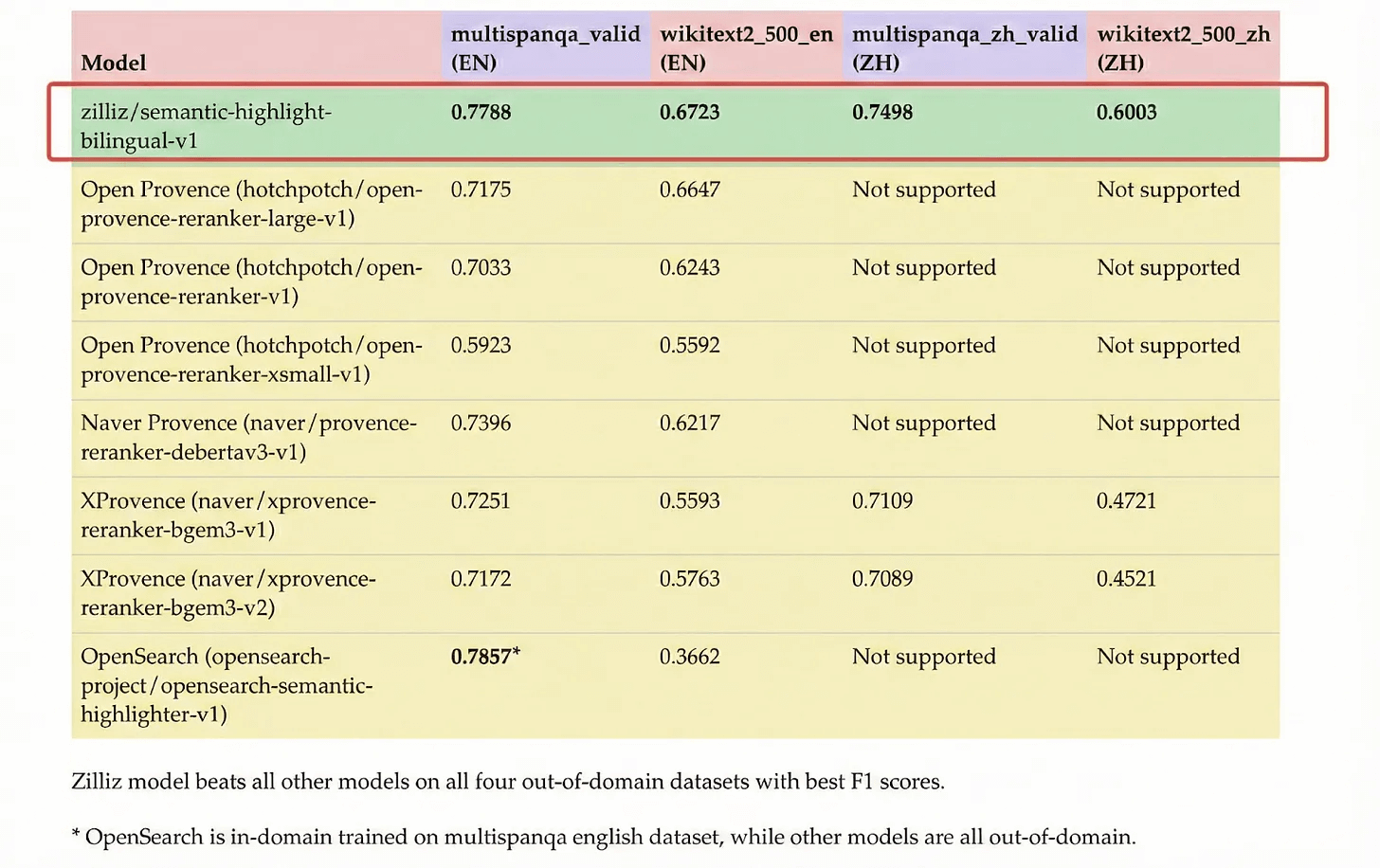
Key findings:
English: Strong performance on both MultiSpanQA (0.78) and WikiText-2 (0.67)
Chinese: Robust across MultiSpanQA-ZH (0.75) and WikiText-2-ZH (0.60)
Consistency: Unlike competitors, performs well on both in-domain and out-of-domain data
The model achieves state-of-the-art performance in both languages.
*Note: OpenSearch appears strong on MultiSpanQA (0.79) because it was trained specifically on that dataset, but performance collapses to 0.37 on out-of-domain data.
A Tricky Example
Here’s where keyword matching fails and semantic understanding shines.
Query: “Who wrote the film The Killing of a Sacred Deer?”
Document contains:
1. “...the screenplay written by Lanthimos and Efthymis Filippou.”
2. “The film stars Colin Farrell, Nicole Kidman...”
3. “The story is based on the ancient Greek play Iphigenia in Aulis by Euripides.”
The trap: Sentence 3 mentions Euripides “wrote” something. A keyword system sees “wrote” + a name and highlights it.
But Euripides wrote the source play, not the film.
How different models scored each sentence:
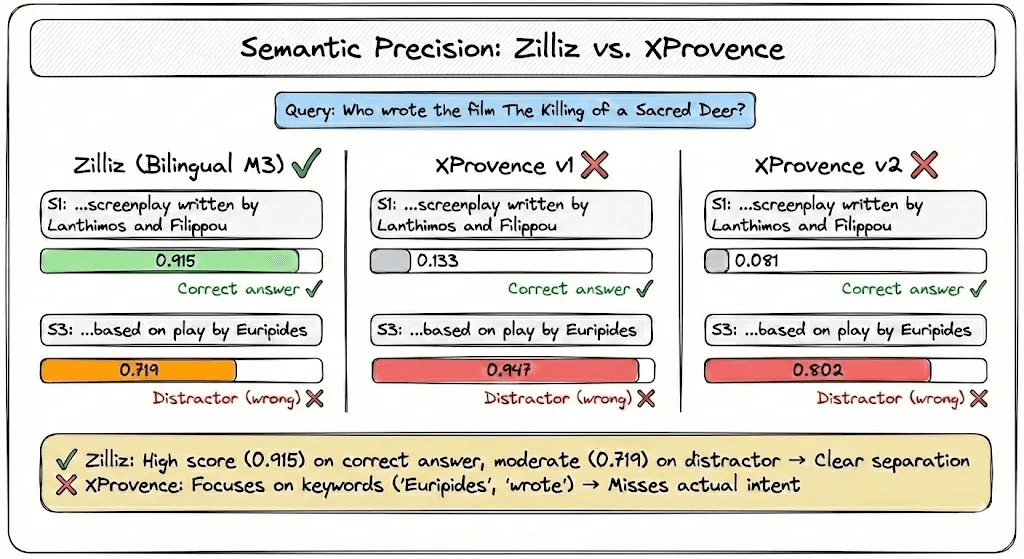
XProvence gets fooled by the keyword association. It gives the trap sentence a near-perfect score while almost ignoring the correct answer.
The Zilliz model understands the difference between “wrote the screenplay” and “wrote the source material.”
That 0.2-point gap is semantic understanding in action.
The Bottom Line
If your retrieval is semantic, your highlighting should be too.
This model bridges that gap. It’s small enough for real-time use and smart enough to understand meaning, not just match keywords.
The model is being integrated into Milvus as a native Semantic Highlighting API. When Milvus retrieves documents, it will automatically surface the most relevant sentences, making it clear where the answer is.
Try it yourself: The model is open-sourced on Hugging Face. →
What’s the most frustrating search experience you’ve had with RAG? Drop a comment. I’d love to hear what problems you’re running into.
Thanks for reading.