
Zero-inflated Regression
What it is and how it ruins ML modelling.

Before I begin…
Today, I finished writing the 2024 edition of the Daily Dose of Data Science archive.

I will release it tomorrow. This version will be much much better than the book we have right now for several reasons:
I have categorized posts based on topics to easily navigate the book.
I have put extra effort into connecting different posts and ensuring a genuine flow while reading the book.
The earlier version made me realize that not all chapters are relevant to everyone. A 2-minute self-assessment is available in the book, which will suggest the most relevant chapters for you.
The entire book is dedicated to no-fluff and core data science and machine learning technical topics, with code wherever possible. In this version, I have removed many basic posts which did not add much value, in my opinion.
You’ll love it :)
Let’s get to today’s post now!
Zero-inflated regression
The target variable of typical regression datasets is somewhat evenly distributed.
But, at times, the target variable may have plenty of zeros. Such datasets are called zero-inflated datasets.
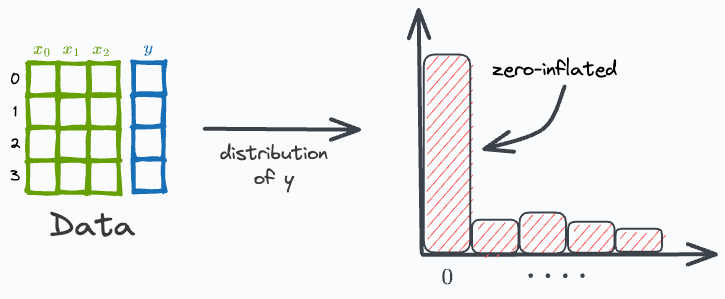
They may raise many problems during regression modeling. This is because a regression model can not always predict exact “zero” values when, ideally, it should.
For instance, consider simple linear regression. The regression line will output exactly “zero” only once (if it has a non-zero slope).

This issue persists:
Not only in higher dimensions...
But also in complex models like neural nets for regression.
One great way to solve this is by training a combination of a classification and a regression model.
This goes as follows:
Mark all non-zero targets as “1” and the rest as “0”.
Train a binary classifier on this dataset.

Next, train a regression model only on those data points with a non-zero true target.

During prediction:

If the classifier’s output is “0”, the final output is also zero.
If the classifier’s output is “1”, use the regression model to predict the final output.
Its effectiveness over the regular regression model is evident from the image below:
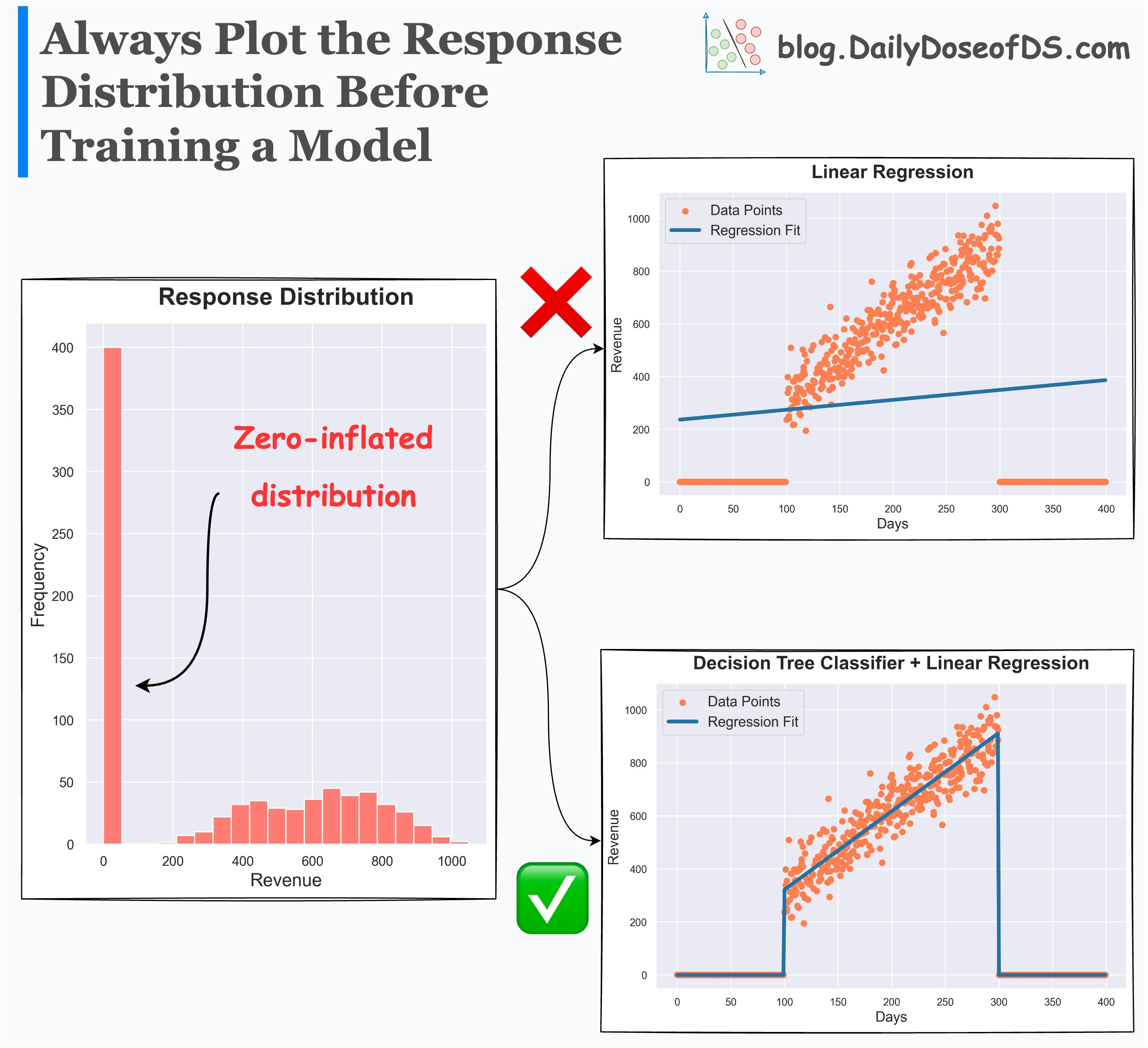
Linear regression alone underfits the data.
Linear regression with a classifier performs as expected.
We covered 8 more pitfalls in data science here: 8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
👉 Over to you: What are other ways to train a model on a zero-inflated dataset?
Thanks for reading!
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 82,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.