
Zero-inflated Regression
What it is and how it ruins ML modelling?

Generate synthetic data at scale!

SDV is an open-source Python library that generates tabular synthetic data by using ML algorithms to learn and replicate patterns from your real data.
Here's how it works in 3 steps:
Train: Point SDV at your real table; it will capture the underlying distributions & relationships.
Generate: Run the trained SDV model to pop out as many look-alike rows as you need—no real data exposed.
Validate: Use SDV’s quality report to see how closely the generated data matches the real stuff; tweak and repeat if you want it tighter.
Some more key features:
Multiple models from GaussianCopula to CTGAN
Single, multi & sequential-table support
Built-in anonymization & logical constraints
Single call does it all `sdv.sample()`
Find it on GitHub here → (don’t forget to star it)
Thanks to SDV for partnering today!
Zero-inflated regression
At times, the target variable of a regression dataset may be inflated with zeros:
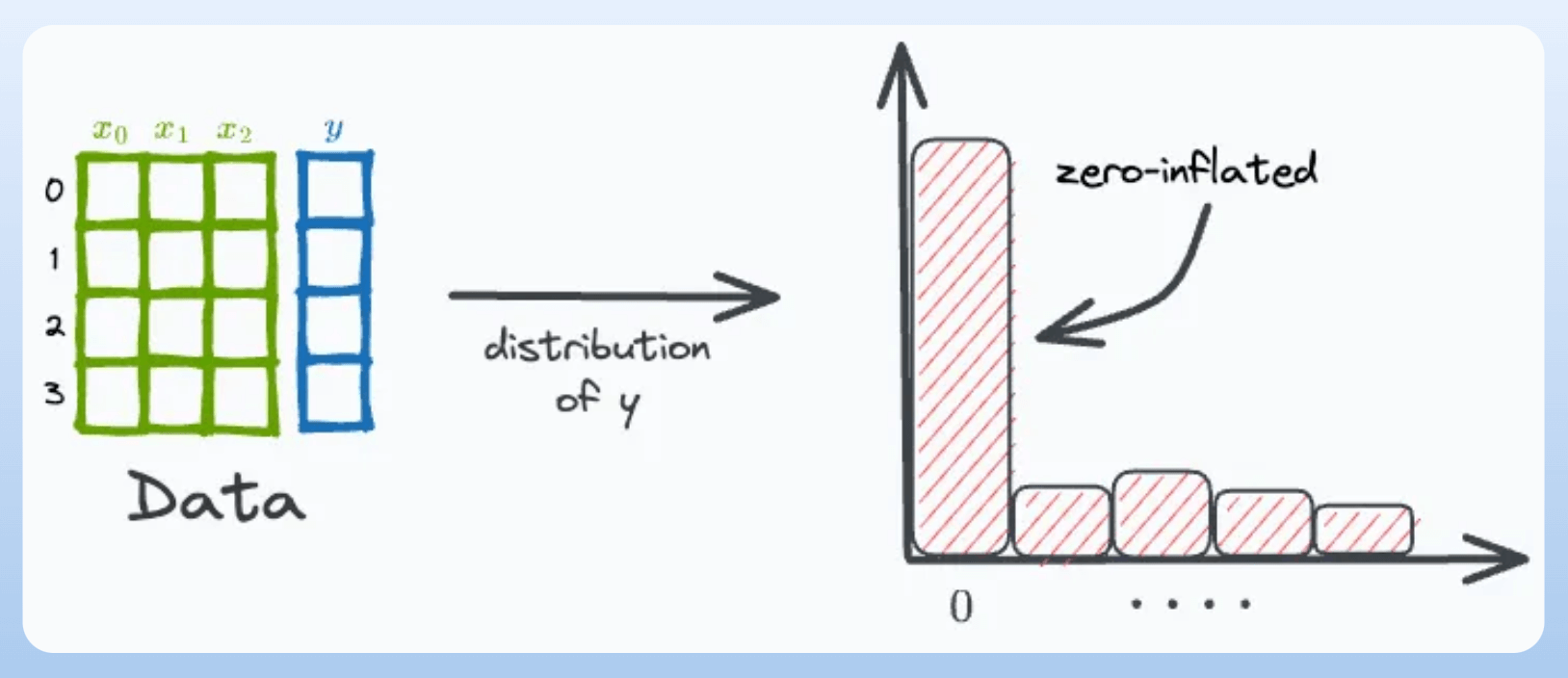
This raises problems during regression modeling because a regression model can not always predict exact “zero” values.
For instance, consider simple linear regression. The regression line will output exactly “zero” only once (if it has a non-zero slope).

One way to solve this is by training a combination of a classification and a regression model.
This goes as follows:
Mark all non-zero targets as “1” and the rest as “0”.
Train a binary classifier on this dataset.

Next, train a regression model only on those data points with a non-zero true target.

During prediction:

If the classifier’s output is “0”, the final output is also zero.
If the classifier’s output is “1”, use the regression model to predict the final output.
Its effectiveness over the regular regression model is evident from the image below:
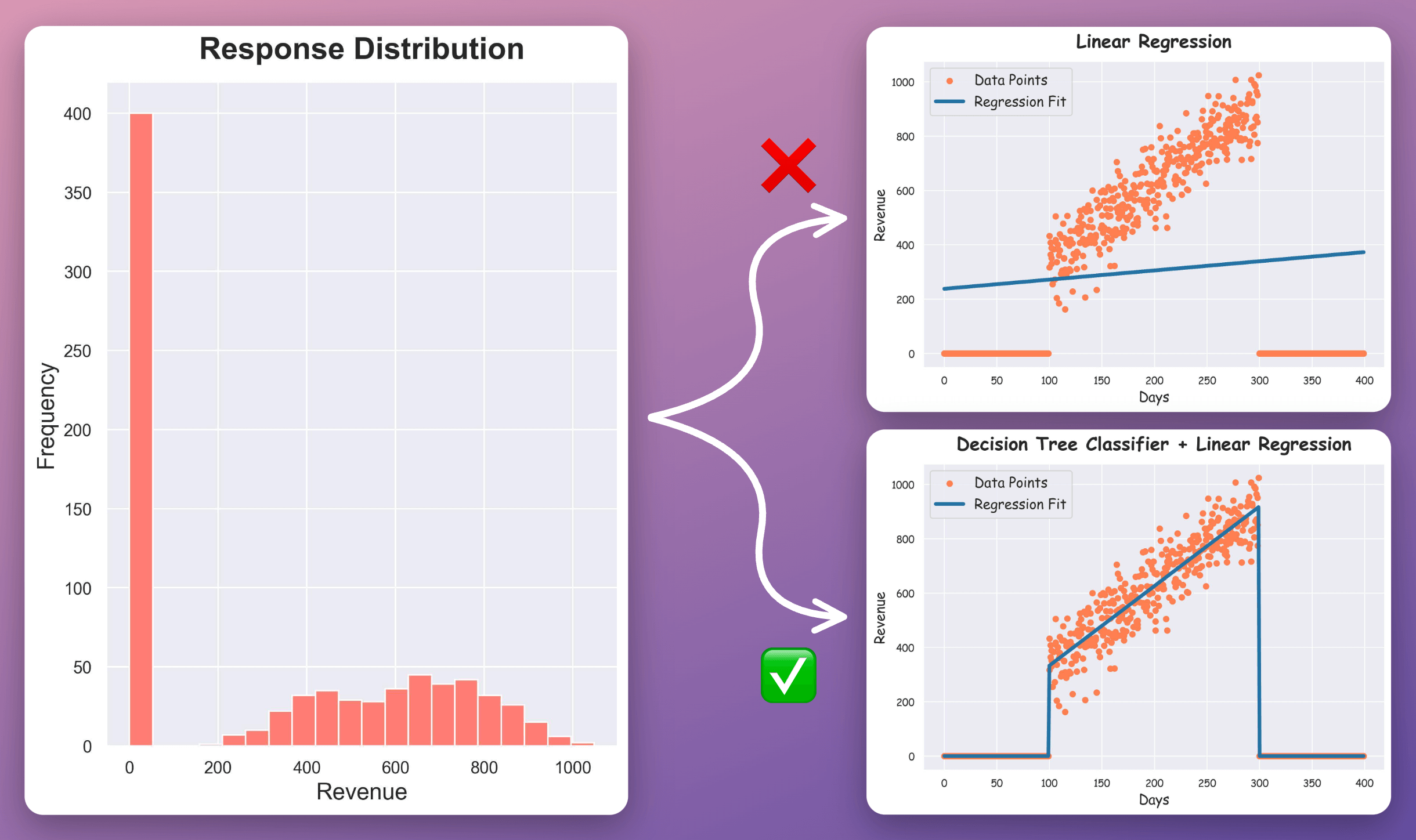
Linear regression alone underfits the data.
Linear regression with a classifier performs as expected.
We covered 8 more pitfalls in data science here: 8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
👉 Over to you: What are other ways to train a model on a zero-inflated dataset?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 13 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.