
3 Types of Missing Values
...and how to impute them.

After seeing missing values in a dataset, most people jump directly into imputing them.
But as counterintuitive as it may sound, the first step towards imputing missing data should NEVER be imputation.
Instead, the first step must be to understand the reason behind data missingness. This is because the data imputation strategy largely depends on WHY data is missing.

More specifically, missingness could be of three types:
Missing completely at random (MCAR).
Missing at random (MAR).
Missing not at random (MNAR).
Only when we determine the reason can we proceed with the appropriate imputation techniques.
What are MCAR, MAR, and MNAR?
Let’s understand them today in detail.
1) Missing completely at random (MCAR)
MCAR is a situation in which the data is genuinely missing at random and has no relation to any observed or unobserved variables.
In other words, the missing data points follow no discernable pattern.

For instance, in survey responses with missing values, assuming MCAR would mean that some participants may have unintentionally skipped to answer any random question.
However, in my experience, MCAR has mostly been an unrealistic assumption for missingness, i.e., data is usually not MCAR for most real-world datasets with missing values.
This is because, in real-world scenarios, the occurrence of missing data often tends to be influenced by some factor, either observed or unobserved.
Human behavior, survey administration, or any external events can be motivating factors for missing values to appear in a dataset.
For instance, participants may selectively omit sensitive information, or certain groups may be more prone to non-response, causing missingness.
That is why assuming MCAR for missing data is not a sensible assumption unless you know the end-to-end data collection process and/or have domain expertise in.
Here, it becomes essential for data scientists to talk to data engineers and understand the data collection process. In fact, this is not just about MCAR but applicable to the other two situations as well, which we shall discuss shortly.
Understanding the data collection process will NEVER hurt.
That said, nothing stops us from assuming that missing values are MCAR if that appears to be a fair thing to do based on the analysis and/or input from the domain experts and/or after understanding the data collection mechanism.
You can proceed with the simplest univariate imputation techniques.
2) Missing at random (MAR)
MAR is a situation in which the missingness of one feature can be explained by other observed features in the dataset.

In contrast to MCAR, MAR is more practically observed.
In this case, the missingness can be accounted for through appropriate statistical methods with reasonable accuracy.
Thus, even though the data is missing, its occurrence can still be (somewhat) estimated based on the information available in the dataset.
A common way to determine MAR is by conditioning on another observed features and noticing any increase in the probability of missingness.
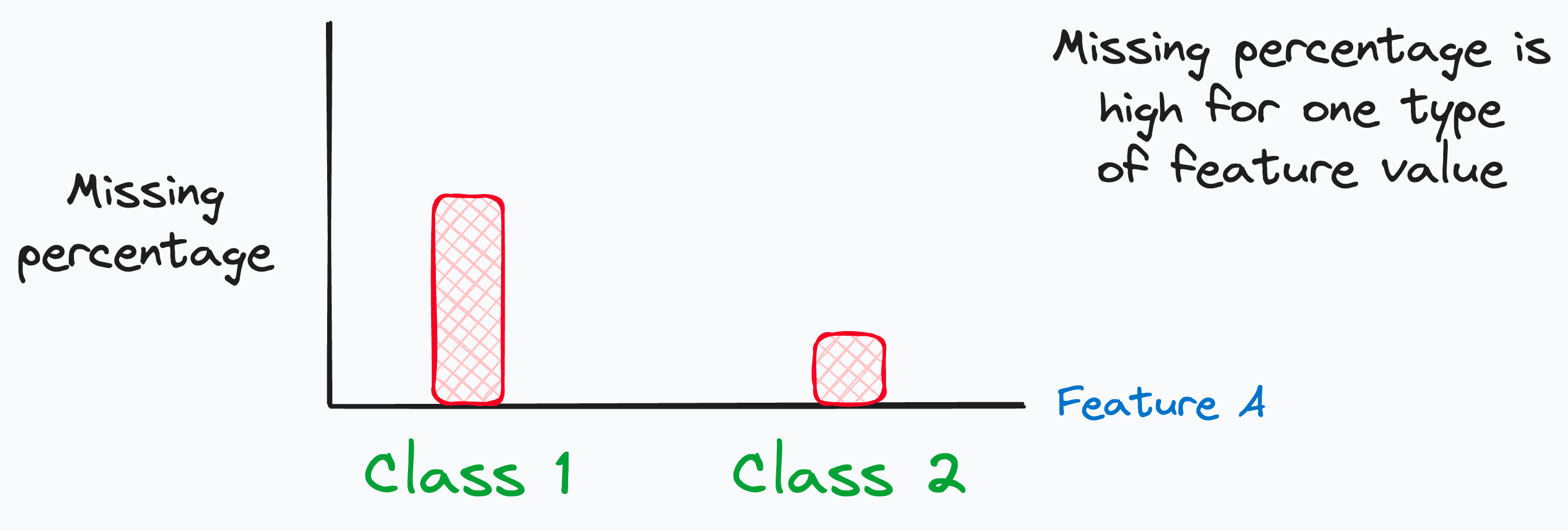
For instance, in an academic performance survey, students with higher grades might be less likely to disclose information about the number of hours they study (due to competition, maybe).
This is where techniques like kNN imputation, Miss Forest, etc., are quite effective. They use other observed features to impute the missing feature.
If you want to learn about them, we covered them here: MissForest and kNN Imputation.
kNN imputation

Miss Forest

3) Missing not at random (MNAR)
MNAR is the most complicated situation of all three.
In MNAR, missingness is either attributed to the missing value itself or the feature(s) that we didn’t collect data for.

In other words, within MNAR, there is a definite pattern in missing variables. However, the pattern is unrelated to any observed feature(s).
This is different from MCAR where there is no definite pattern.
For instance, in a health survey, participants with very high stress levels might consciously choose not to disclose their stress level due to stigma, or fear of judgment.
As a result, the missing data on stress level is not random; it is influenced by the stress level itself.
So, in a way, the higher the stress level, the less likely one will disclose it, and the more likely the value will be missing from the collected dataset.
Thus, the missingness is directly dependent on the very variable that is missing in the first place.
That’s tricky, isn’t it?
There’s not much we can do to address this, except for collecting more data/features. What’s more, domain expertise become extremely important to smartly tackle MNAR and improve the data collection process.
At times, I have also preferred proceeding with typical imputation techniques (used in MCAR and MAR) because further data collection can be infeasible in most cases.
But as discussed above, there is a definite missingness pattern in MNAR, which can be important. But direct imputation will discard that information.
One way to retain that missingness pattern is by adding a binary feature, indicating whether the feature was imputed.

This way, the ML algorithm can still access and learn the missing data patterns.
👉 Over to you: What other points would you like to add here about MCAR, MAR, and MNAR?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 81,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
In the case of “Missing not at random” (MNAR). Can non-missing data analysis be used to infer missing data? In the example you gave of the stress level, let's say the stress level is a value from 0 to 10. If the current data indicates, for values from 0 to 7, a normal, or uniform, or any other identifiable distribution, presenting exceptions to this distribution only in the quantities of values from 8 to 10, can we use the inferred distribution to insert the missing data?