
5 LLM Fine-tuning Techniques Explained Visually
Explained in a beginner-friendly way.

Sourcery is making manual code reviews obsolete with AI. Every pull request instantly gets a human-like review from Sourcery with general feedback, in-line comments, and relevant suggestions.

What used to take over a day now takes a few seconds only.
Sourcery handles 500,000+ requests every month (reviews + refactoring + writing tests + documenting code, etc.) and I have been using it for over 1.5 years now.
If you care about your and your team’s productivity, get started right away:
Thanks to Sourcery for partnering with me today!
Let’s get to today’s post now.
Fine-tuning LLMs
Traditional fine-tuning (depicted below) is infeasible with LLMs because these models have billions of parameters and are hundreds of GBs in size, and not everyone has access to such computing infrastructure.

Thankfully, today, we have many optimal ways to fine-tune LLMs, and five such popular techniques are depicted below:
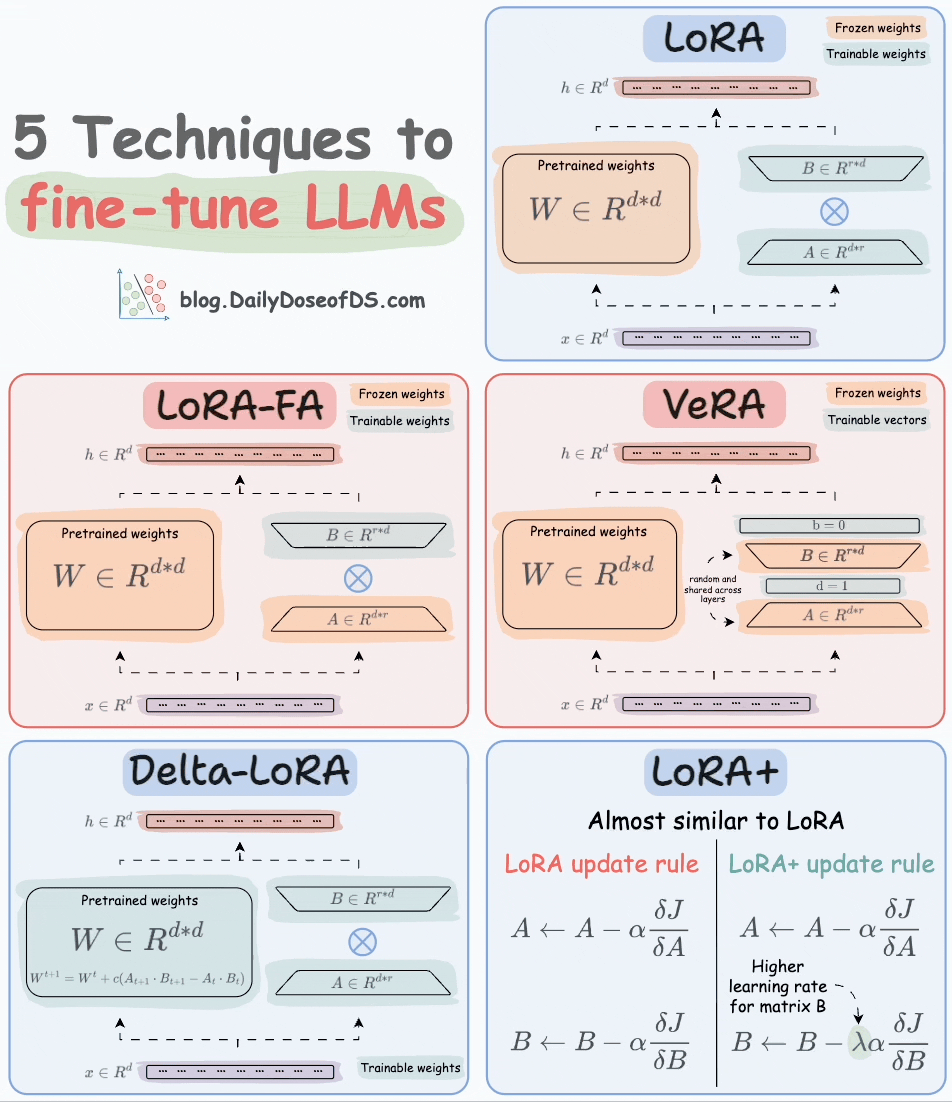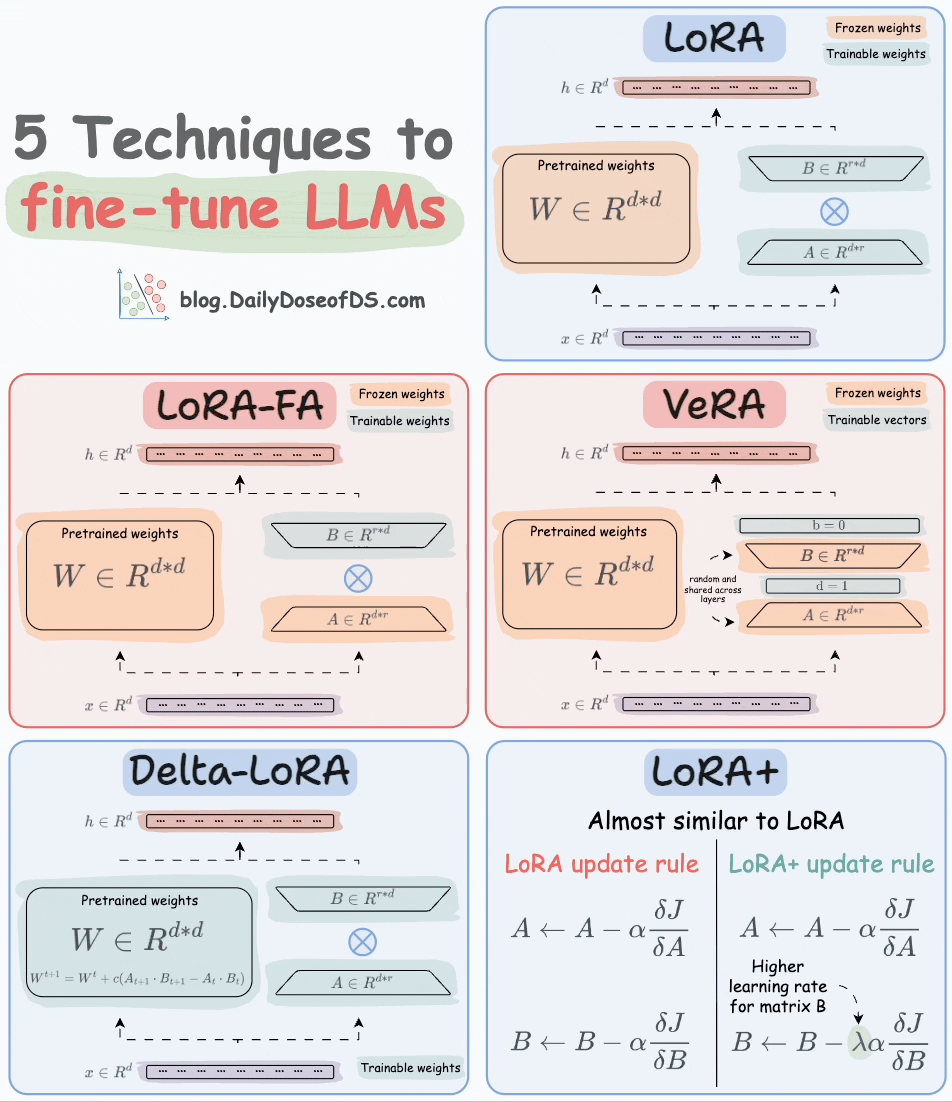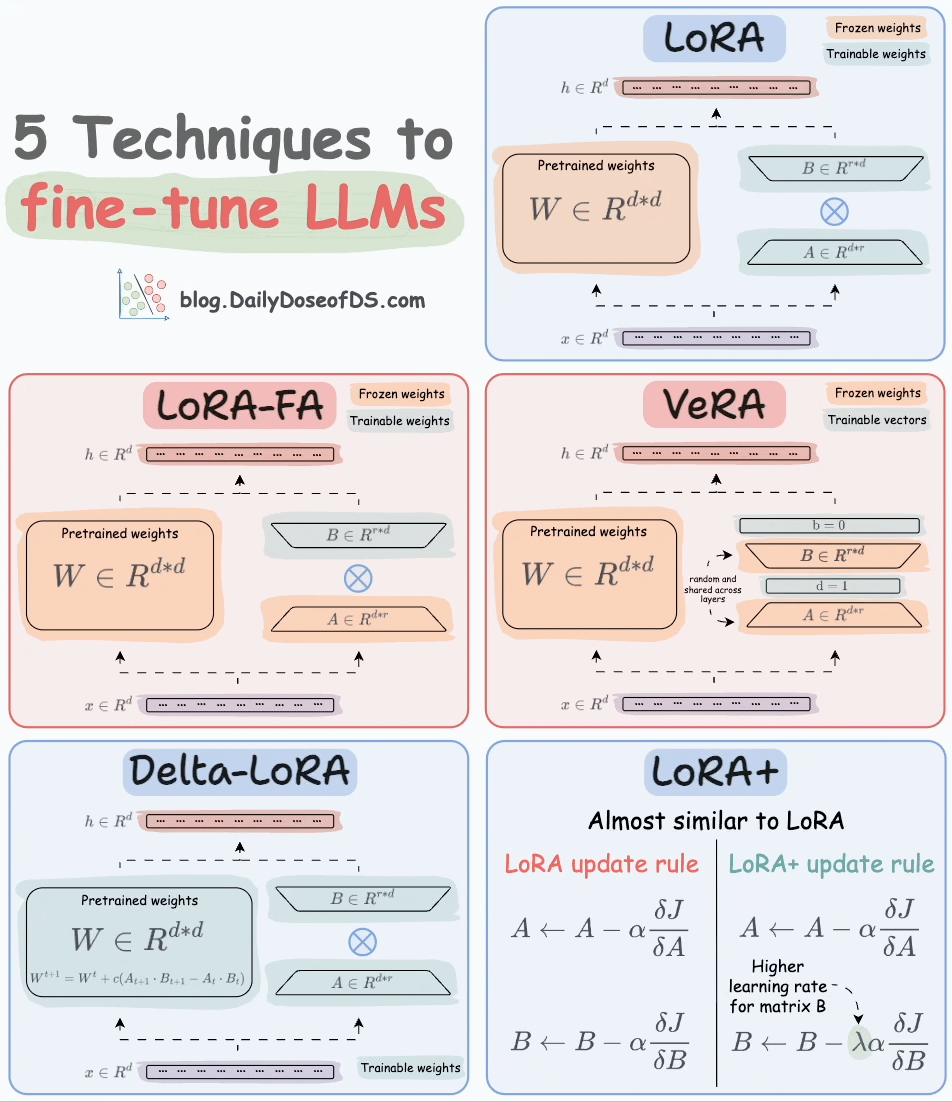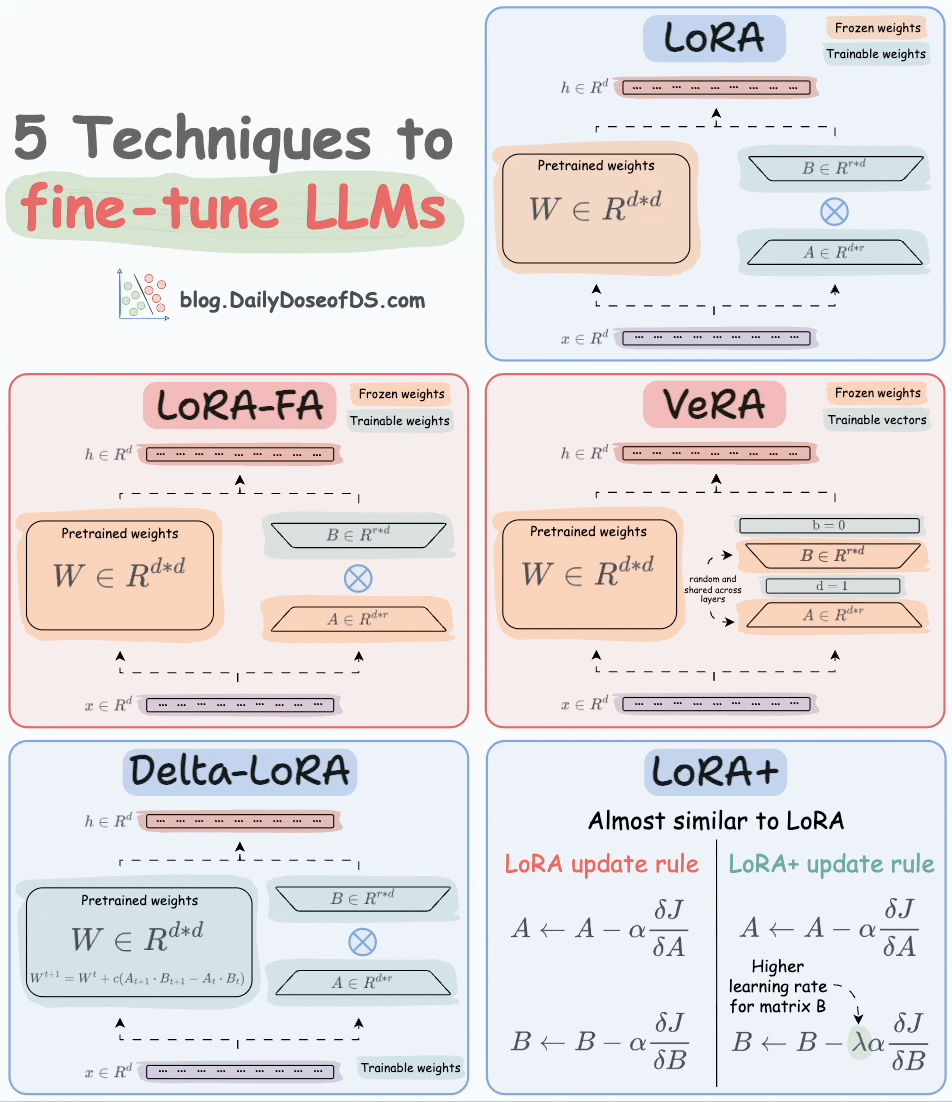
We covered them in detail here:
Here’s a brief explanation:
LoRA: Add two low-rank matrices
AandBalongside weight matrices, which contain the trainable parameters. Instead of fine-tuningW, adjust the updates in these low-rank matrices.

LoRA-FA: While LoRA considerably decreases the total trainable parameters, it still requires substantial activation memory to update the low-rank weights. LoRA-FA (FA stands for Frozen-A) freezes the matrix
Aand only updates matrixB.

VeRA: In LoRA, every layer has a different pair of low-rank matrices
AandB, and both matrices are trained. In VeRA, however, matricesAandBare frozen, random, and shared across all model layers. VeRA focuses on learning small, layer-specific scaling vectors, denoted asbandd, which are the only trainable parameters in this setup.

Delta-LoRA: Here, in addition to training low-rank matrices, the matrix
Wis also adjusted but not in the traditional way. Instead, the difference (or delta) between the product of the low-rank matricesAandBin two consecutive training steps is added toW:

LoRA+: In LoRA, both matrices
AandBare updated with the same learning rate. Authors found that setting a higher learning rate for matrixBresults in more optimal convergence.

To get into more detail about the precise steps, intuition, and results, read these articles:
That said, these are not the only LLM fine-tuning techniques. The following visual depicts a timeline of popular approaches:

👉 Over to you: What are some ways to reduce the computational complexity of fine-tuning LLMs?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 77,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.