
A Lesser-known Advantage of Using L2 Regularization — Part II
An untaught advantage of L2 regularization that most data scientists don't know.

A couple of days back, we discussed how L2 regularization helps us address multicollinearity.
Multicollinearity arises when two (or more) features are highly correlated OR two (or more) features can predict another feature:

The core idea we discussed in that post was that, say, we are using linear regression, and the dataset has multicollinearity.
Then…
Without L2 regularization, obtaining a single value for the parameters (θ) that minimizes the RSS is impossible.
L2 regularization helps us address this issue and obtain an optimum solution.
This is demonstrated below:

Note: If you want to learn about the probabilistic origin of L2 regularization, check out this article: The Probabilistic Origin of Regularization.
I mentioned that post here because other than reducing overfitting and addressing multicollinearity, there’s one more lesser-talked problem that L2 regularization neatly handles, which is related to multicollinearity.
Today, I want to talk about that.
Let’s begin!
Consider the OLS solution we obtain from linear regression:

Xis the matrix of independent variable (Shape:n*m).yis the vector of targets (Shape:m*1).θ is the weight vector (Shape:
m*1).
If we look closely, we see that the OLS solution will only exist if our matrix (XᵀX) is invertible.

But a problem arises when the number of features (m) exceeds the number of data points (n) — m>n, in which case, this matrix will not be invertible.
Of course, it is very unlikely to run into such a situations in ML. However, I have seen this in many other fields which actively use ML, such as genomics.
Nonetheless, we never know when we may encounter such a situation in ML so it’s good to be aware of it. Moreover, today’s post will show you one more to understand how L2 regularization eliminates multicollinearity.
For simplicity, consider we have the following input matrix X, which has more features than rows:

Here, it is ALWAYS possible to represent, say, the third column as a linear combination of the first two columns. This is depicted below:

The above system of linear equations has a solution for ‘a’ and ‘b’.
This shows that all datasets with the number of features exceeding the number of rows possess perfect multicollinearity.
This is because any column will ALWAYS be a linear combination of two other columns.
Speaking in a more mathematical sense, when (m>n), we always get a system of linear equations where the number of unknowns (a and b above) is equal to the number of equations we can generate.
However, had our dataset contained more rows than columns (n>m), it would not have been possible to solve that system of linear equations (unless the dataset itself possessed multicollinearity):

Now, given that any dataset in which the number of columns exceeds the number of rows has perfect multicollinearity, we can go back to what we discussed in the earlier post.
Without the L2 penalty, the residual plot will result in a valley. As a result, obtaining a single value for the parameters (θ) that minimizes the RSS will be impossible. This is depicted below:

With the L2 penalty, however, we get the following plot, which removes the valley we saw earlier and provides a global minima to the RSS error:
Now, obtaining a single value for the parameters (θ) that minimizes the RSS is possible.
In fact, there is one more way to prove that if X (irrespective of its dimensions) has perfect multicollinearity, then L2 regularization helps us eliminate it.
Consider the above 2*4 matrix again, and let’s apply the linear combination to the third and fourth columns:

Computing XᵀX on the final result, we get a noninvertible matrix:

This shows that if the dataset X (irrespective of the shape) has perfect multicollinearity, XᵀX will not be invertible (remember this as we’ll refer back to this shortly).
Moving on, let’s consider the loss function with the L2 penalty:

The objective is to find the parameters θ that minimize this.
Thus, we differentiate the above expression with respect to θ, and set it to zero:
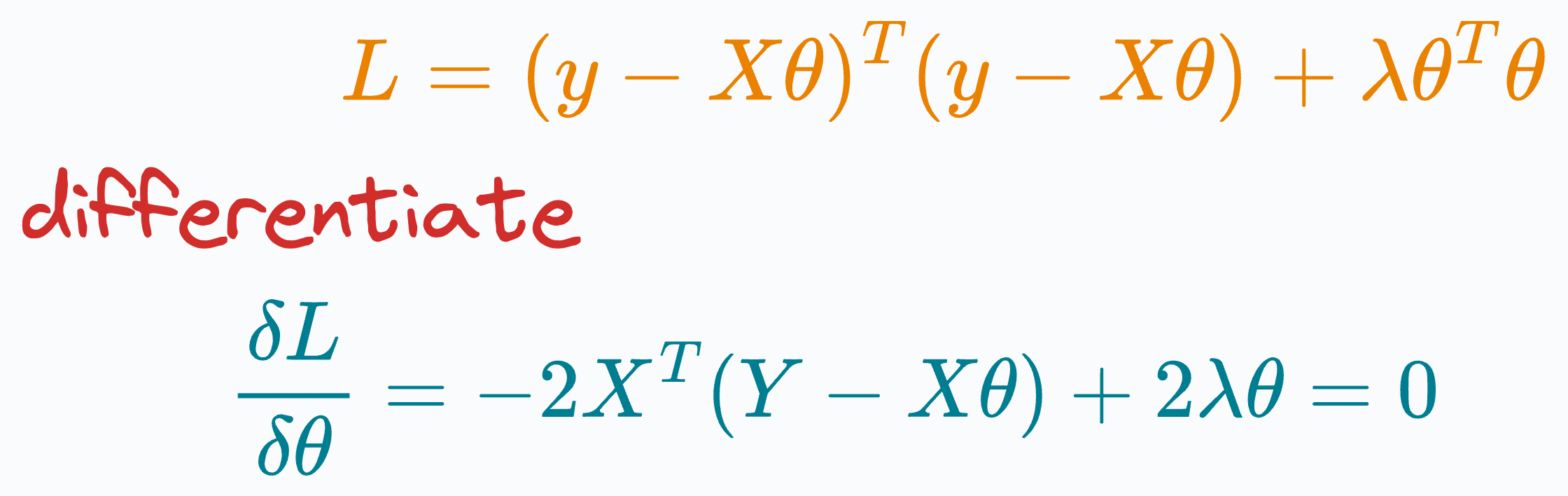
Next, we solve for θ to get the following:

Notice something here.
The OLS solution DOES NOT invert XᵀX now. Instead, there’s an additional diagonal matrix, which gets added to XᵀX, and it makes the result invertible (λ!=0):

That was another proof of how regularization helps us eliminate multicollinearity.
So remember that L2 regularization is not just a remedy to reduce overfitting. It is also useful to eliminate multicollinearity.
Hope you learned something new today :)
If you want to learn about the probabilistic origin of L2 regularization, check out this article: The Probabilistic Origin of Regularization.
While most of the community appreciates the importance of regularization, in my experience, very few learn about its origin and the mathematical formulation behind it.
It can’t just appear out of nowhere, can it?
Also, if you love to dive into the mathematical details, here are some topics that would interest you:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
👉 Over to you: What are some other advantages of using L2 regularization?
For those who want to build a career in DS/ML on core expertise, not fleeting trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.