
A Misconception About Log Transform
...and here's what it does.

Launching big data analytics projects can take days. DoubleCloud simplifies this and reduces the project launch time to just a few minutes.
Setting up a data analytics project is as simple as selecting technologies from a dropdown, and DoubleCloud takes care of the integration procedures.

I read on their website that DoubleCloud’s customers like:
LSports reduced query speed by 180x compared to MySQL.
Honeybadger experienced a 30x boost compared to Elasticsearch.
Spectrio cut costs by 30-40% compared to Snowflake.

Join below:
I recently wrote a newsletter issue about DoubleCloud in case you missed it: How To Simplify ANY Data Analytics Project with DoubleCloud?
Thanks to DoubleCloud for partnering today!
Misconception About Log Transform
Log transform is commonly used to eliminate skewness in data.

Yet, it is not always the ideal solution for eliminating skewness.
It is important to note that log transform:
DOES NOT eliminate left-skewness.
Only works for right-skewness, that too when the values are small and positive.
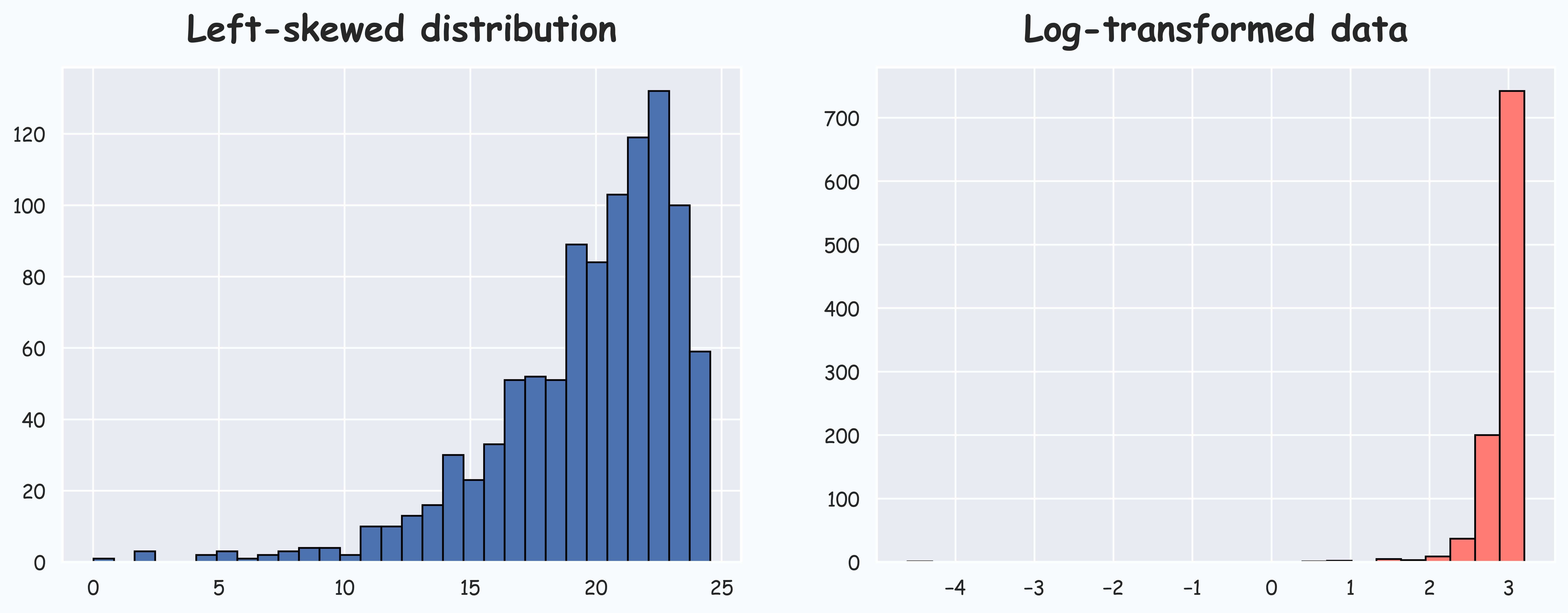
To understand better, consider the left-skewed distribution and its log transform below:

It is clear that log transform did not eliminate skewness.
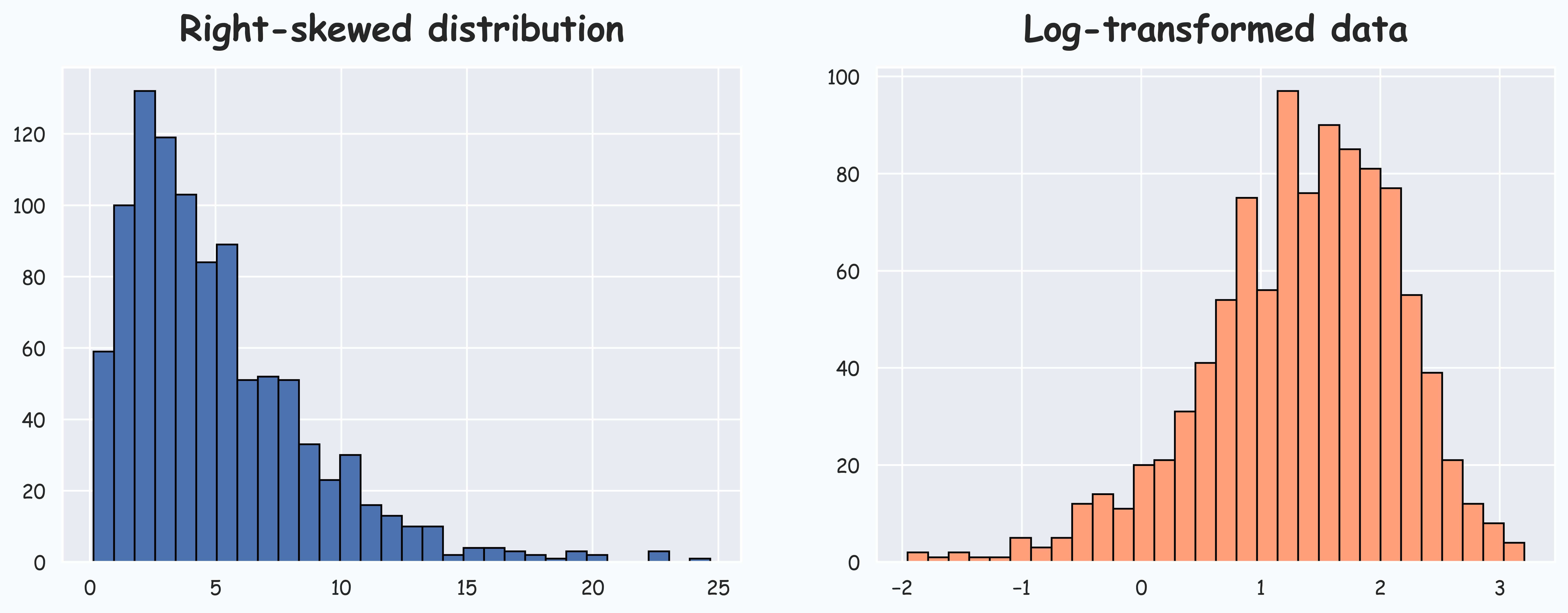
However, now consider a right-skewed distribution:

This time, it eliminates the skewness.
This happens because the log function grows faster for lower values. Thus, it stretches out the lower values more than the higher values.

More specifically, in the case of left-skewness, the tail exists to the left, which gets stretched more than the majority of the probability mass that exists to the right. Thus, skewness isn't affected much.
However, in the case of right-skewness, the majority of probability mass exists to the left, which gets stretched out more.
That said, it is important to note that even if we have a right-skewed distribution, log transform will not be effective if the values are large.

This happens because the stretch effect of the log function diminishes at large values:

I have often found the box-cox transform to be quite effective at eliminating both right-skewness and left-skewness, as depicted below:

To read next, here are 8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
👉 Over to you: What are some other ways to eliminate skewness?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of more than 76,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.