
How to Build Linear Models?
The data generation perspective.

In a recent post, we covered Poisson regression and how it differs from linear regression.
Today, we shall continue discussing that topic, and I will help you cultivate what I think is one of the MOST overlooked and underappreciated skills in developing linear models.
I can guarantee that harnessing this skill will give you a lot of clarity and intuition in the modeling stages.
But let’s do a quick recap of yesterday’s post before we proceed.
Recap
Having a non-negative response in the training data does not stop linear regression from outputting negative values.
Essentially, you can always extrapolate the regression fit for some inputs to get a negative output.

While this is not an “issue” per se, negative outputs may not make sense in cases where you can never have such outcomes.
For instance:
Predicting the number of calls received.
Predicting the number of cars sold in a year, etc.
More specifically, the issue arises when modeling a count-based response, where a negative output wouldn’t make sense.
In such cases, Poisson regression often turns out to be a more suitable linear model than linear regression.
This is evident from the image below:

For in-depth info, please read yesterday’s post after today’s issue: Poisson Regression vs. Linear Regression.
I thought of continuing yesterday’s post because people sometimes become overly optimistic about how Poisson regression can handle those limitations.
But, trust me, Poisson regression is no magic.
It’s just that, in our specific use case, the data generation process didn’t perfectly align with what linear regression is designed to handle.
In other words, earlier when we trained a linear regression model, we inherently assumed that the data was sampled from a normal distribution.
But that was not true in this Poisson regression case.

Instead, it came from a Poisson distribution, which is why Poisson regression worked better.
Thus, the takeaway is that whenever you train linear models, always always and always think about the data generation process.
It goes like this:
Okay, I have this data.
I want to fit a linear model through it.
What information do I get about the data generation process that can help me select an appropriate linear model?
You’d start appreciating the importance of data generation when you realize that literally every member of the generalized linear model family stems from altering the data generation process.

For instance:
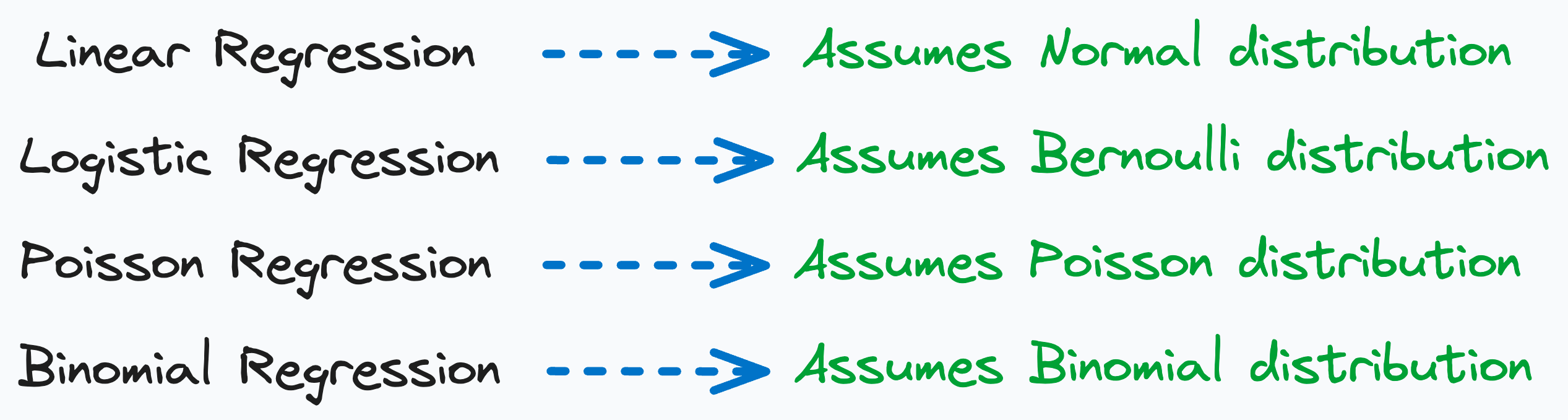
If the data generation process involves a Normal distribution → you get linear regression.
If the data has only positive integers in the response variable, maybe it came from a Poisson distribution → and this gives us Poisson regression. This is precisely what we discussed yesterday.
If the data has only two targets —
0and1, maybe it was generated using Bernoulli distribution → and this gives rise to logistic regression.If the data has finite and fixed categories
(0, 1, 2,…n), then this hints towards Binomial distribution → and we get Binomial regression.
See…
Every linear model makes an assumption and is then derived from an underlying data generation process.
Thus, developing a habit of holding for a second and thinking about the data generation process will give you so much clarity in the modeling stages.
I am confident this will help you get rid of that annoying and helpless habit of relentlessly using a specific sklearn algorithm without truly knowing why you are using it.
Consequently, you’d know which algorithm to use and, most importantly, why.
This improves your credibility as a data scientist and allows you to approach data science problems with intuition and clarity rather than hit-and-trial.
In fact, once you understand the data generation process, you will automatically get to know about most of the assumptions of that specific linear model.
Here, I would really encourage you to read the deep dive on generalized linear models (GLMs) because there are so many nuances that one must be aware of.
👉 Read it here: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Why care?
A linear regression model is undeniably an extremely powerful model, in my opinion.
However, it does make some strict assumptions about the type of data it can model.
So, if linear regression is the only linear model you know, it is difficult to expect good modeling results because nothing stops real-world datasets from violating these assumptions.
That is why being aware of its extensions is immensely important.
The GLM article covers the following topics:
How does linear regression model data and its limitations?
What are GLMs?
What are the core components of GLMs?
How do they relax the assumptions of linear regression?
What are the common types of GLMs?
What are the assumptions of these GLMs?
How do we use maximum likelihood estimates with these GLMs?
How to build a custom GLM for your own data?
Best practices and takeaways.
👉 Interested folks can read it here: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 80,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Thank you! The way you explained each model's relationship to a distribution is very insightful.