
Implementing a Siamese Network
A beginner-friendly implementation guide.

Announcement (in case you missed it)
From 1st October, lifetime access to the Daily Dose of DS will be available at 3x the annual price (currently, it is 2x the annual price).
You can join below before it increases in the next ~30 hours.
It gives you lifetime access to the no-fluff, industry-relevant, and practical DS and ML resources that truly matter to your skills for succeeding and staying relevant in these roles.

I can’t wait to help you more. Join below:
Let’s get to today’s post now!
In yesterday’s issue, we learned how a Siamese network trained using contrastive loss can help us build a face unlock system.
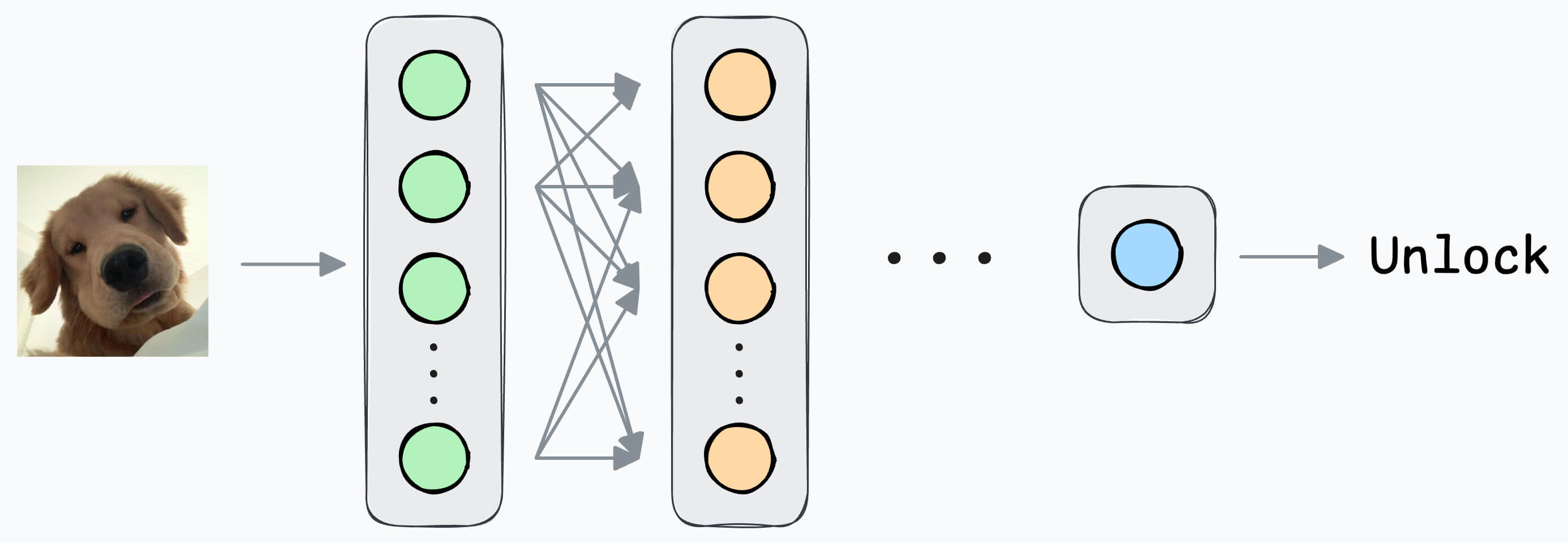
Today, let’s understand the implementation.
Quick recap
If you haven’t read yesterday’s issue, I highly recommend it before reading ahead.
It will help you understand the true motivation behind WHY we are using it:

Here’s a quick recap of the overall idea:
Create a dataset of face pairs:

If a pair belongs to different entities, the true label will be 1.
If a pair belongs to the same entity, the true label will be 0.

Next, define a network like this:

Pass both inputs through the same network to generate two embeddings.
If the true label is 0 (same entity) → minimize the distance between the two embeddings.
If the true label is 1 (different entities) → maximize the distance between the two embeddings.

Contrastive loss (defined below) helps us train such a model:
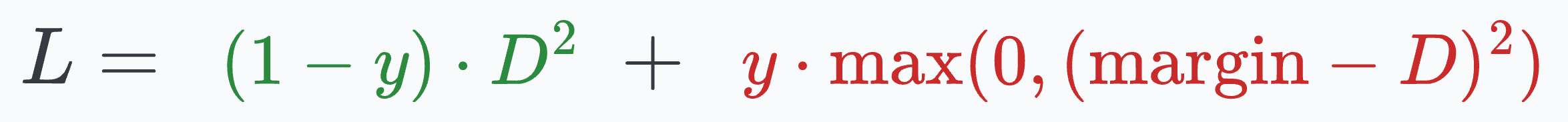
where:
yis the true label.Dis the distance between two embeddings.marginis a hyperparameter, typically greater than 1.
If you haven’t read yesterday’s issue, I highly recommend it before reading ahead. It will help you understand the true motivation behind why we are using it:
Implementation
Next, let’s look at the implementation of this model.
For simplicity, we shall begin with a simple implementation utilizing the MNIST dataset. In a future issue, we shall explore the face unlock model.
Let’s implement it.
As always, we start with some standard imports:

Next, we download/load the MNIST dataset:

Now, recall to build a Siamese network, we have to create image pairs:
In some pairs, the two images will have the same true label.
In other pairs, the two images will have a different true label.
To do this, we define a SiameseDataset class that inherits from the Dataset class of PyTorch:

This class will have three methods:
The
__init__method:

data parameter will be mnist_train and mnist_test defined earlier.The
__len__method:

The
__getitem__method, which is used to return an instance of the train data. In our case, we shall pair the current instance from the training dataset with:Either another image from the same class as the current instance.
Or another image from a different class.
Which class to pair with will be decided randomly.
The __getitem__ method is implemented below:

Line 5: We obtain the current instance.
Line 7: We randomly decide whether this instance should be paired with the same class or not.
Lines 9-12: If
flag=1, continue to find an instance until we get an instance of the same class.Lines 14-17: If
flag=0, continue to find an instance until we get an instance of a different class.Line 19-21: Apply transform if needed.
Line 23:
If the two labels are different, the true label for the pair will be 1.
If the two labels are the same, the true label for the pair will be 0.
After defining the class, we create the dataset objects below:

Next, we define the neural network:

The two input images are fed through the same network to generate an embedding (
outputAandoutputB).
Moving on, we define the contrastive loss:
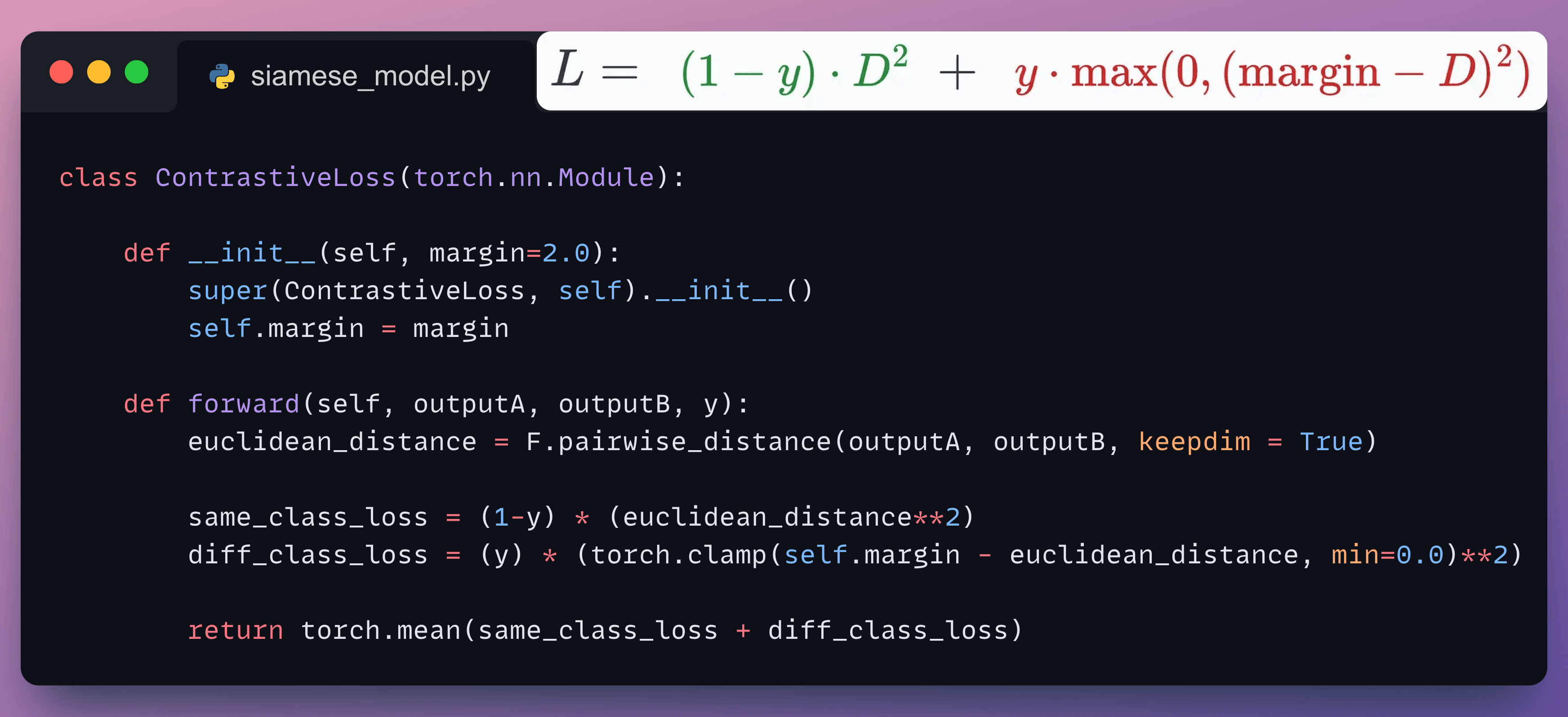
Almost done!
Next, we define the dataloader, the model, the optimizer, and the loss function:

Finally, we train it:

And with that, we have successfully implemented a Siamese Network using PyTorch.
Results
Let’s look at some results using images in the test dataset:
We can generate a similarity score as follows:

Image pair #1: Similarity is high since both images depict the same digit:

Image pair #2: Similarity is low since both images depict different digits:

Image pair #3: Similarity is high since both images depict the same digit:

Image pair #4: Similarity is low since both images depict different digits:

Great, it works as expected!
And with that, we have successfully implemented and verified the predictions of a Siamese Network.
That said, there’s one thing to note.
Since during the data preparation step, we paired the instance either with the same or a different class…
…this inherently meant that this approach demands labeled data.
There are several techniques to get around this, which we shall discuss soon.
👉 In the meantime, it’s over to you: Can you tell how you would handle unlabeled data in this case?
The code for today’s issue is available here: Siamese Network Implementation.
For those wanting to develop “Industry ML” expertise:
All businesses care about impact.
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with “Industry ML.” Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
Being able to code is a skill that’s diluting day by day.
Thus, the ability to make decisions, guide strategy, and build solutions that solve real business problems and have a business impact will separate practitioners from experts.
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Very good!
Thanks for sharing 🤓!