
Most People Overlook This Critical Step After Cross Validation
How to finalize a model after cross validation?

Today, let me ask you a question.
But before I do that, I need to borrow your imagination for just a moment.
Imagine you are building some supervised machine learning model.
You are using cross-validation to determine an optimal set of hyperparameters.
Some context:
Cross-validation means repeatedly partitioning the available data into subsets, training the model on a few subsets, and validating on the remaining subsets.
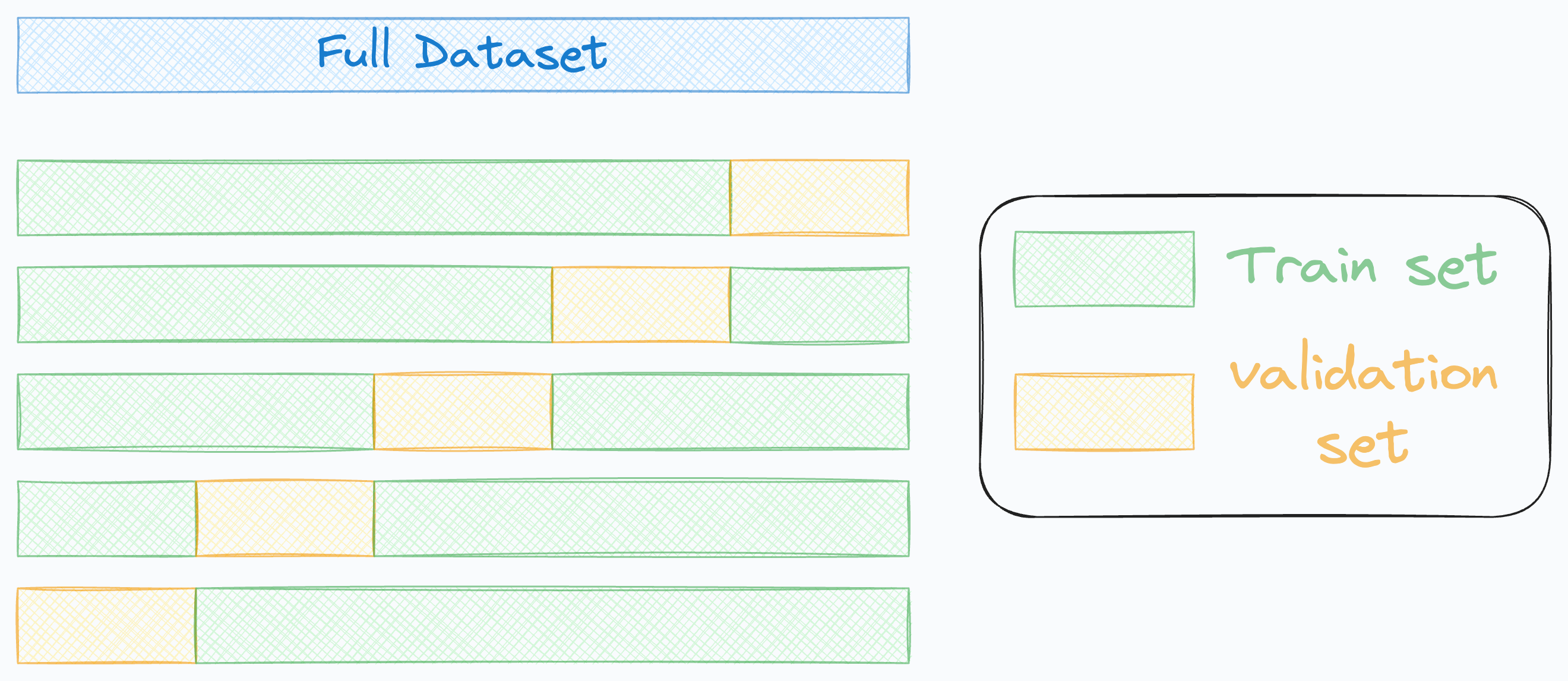
The main advantage of cross validation is that it provides a more robust and unbiased estimate of model performance compared to the traditional validation method.
In other words, tuning machine learning models on a single validation set can be misleading and sometimes yield overly optimistic results.
This can occur due to a lucky random split of data, which results in a model that performs exceptionally well on the validation set but poorly on new, unseen data.

Here’s a full post about cross-validation if you want to learn more about this topic: 5 Must-know Cross Validation Techniques Explained Visually.
Coming back to the topic…
Essentially, every hyperparameter configuration corresponds to a cross-validation performance:

After obtaining the best hyperparameters, we need to finalize a model (say for production); otherwise, what is the point of all this hassle?
Now, here’s the question:
After obtaining the optimal hyperparameters, what would you be more inclined to do:
Retrain the model again on the entire data (train + validation + test) with the optimal hyperparameters?

If we do this, remember that we can’t reliably validate this new model as there is no unseen data left.
Just proceed with the best-performing model based on cross-validation performance itself.

If we do this, remember that we are leaving out important data, which we could have trained our model with.


What would you do?
Mark your response below before reading the answer (the poll is anonymous):
Recommended path
My strong preference has almost always been “retraining a new model with entire data.”

There are, of course, some considerations to keep in mind, which I have learned through the models I have built and deployed.
That said, in most cases, retraining is the ideal way to proceed.
Let me explain.
Why retrain the model?
We would want to retrain a new model because, in a way, we are already satisfied with the cross-validation performance, which, by its very nature, is an out-of-fold metric.
An out-of-fold data is data that has not been seen by the model during the training. An out-of-fold metric is the performance on that data.
In other words, we already believe that the model aligns with how we expect it to perform on unseen data.

Thus, incorporating this unseen validation set in the training data and retraining the model will MOST LIKELY have NO effect on its performance on unseen data after deployment (assuming a sudden covariate shift hasn’t kicked in, which is a different issue altogether).
If, however, we were not satisfied with the cross-validation performance itself, we wouldn’t even be thinking about finalizing a model in the first place.

Instead, we would be thinking about ways to improve the model by working on feature engineering, trying new hyperparameters, experimenting with different models, and more.
The reasoning makes intuitive sense as well.
It’s hard for me to recall any instance where retraining did something disastrously bad to the overall model.
In fact, I vividly remember one instance wherein, while I was productionizing the model (it took me a couple of days after retraining), the team had gathered some more labeled data.
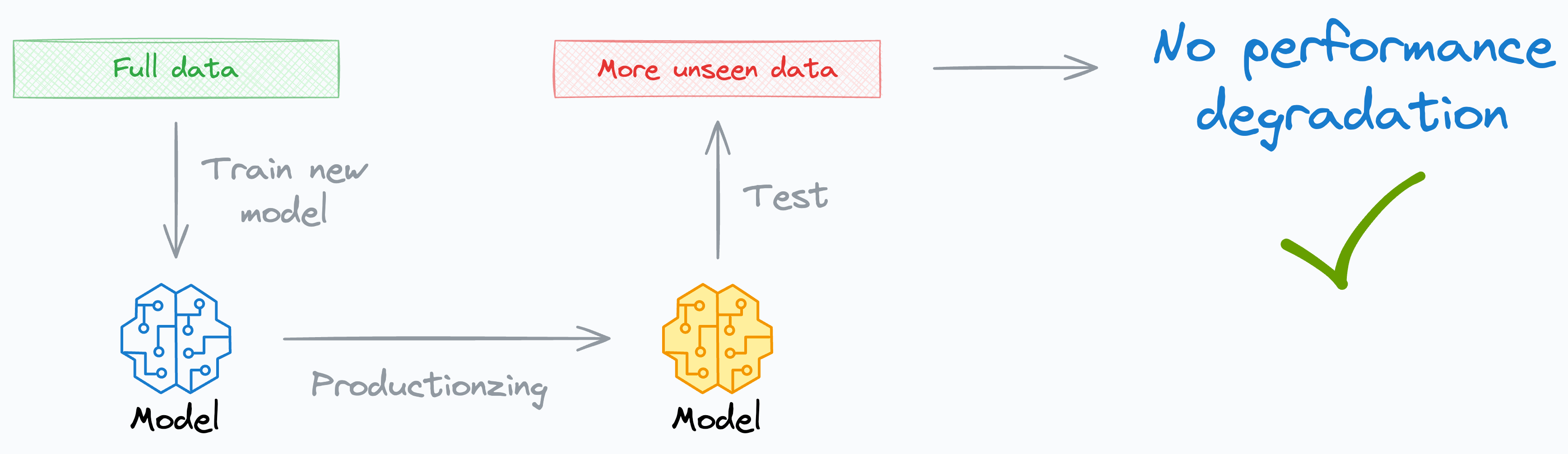
The model didn’t show any performance degradation when I evaluated it (just to double-check).
As an added benefit, this also helped ensure that I had made no errors while productionizing my model.
Some considerations
Here, please note that it’s not a rule that you must always retrain a new model.
The field itself and the tasks one can solve are pretty diverse, so one must be open-minded while solving the problem at hand.
One of the reasons I wouldn’t want to retrain a new model is that it takes days or weeks to train the model.
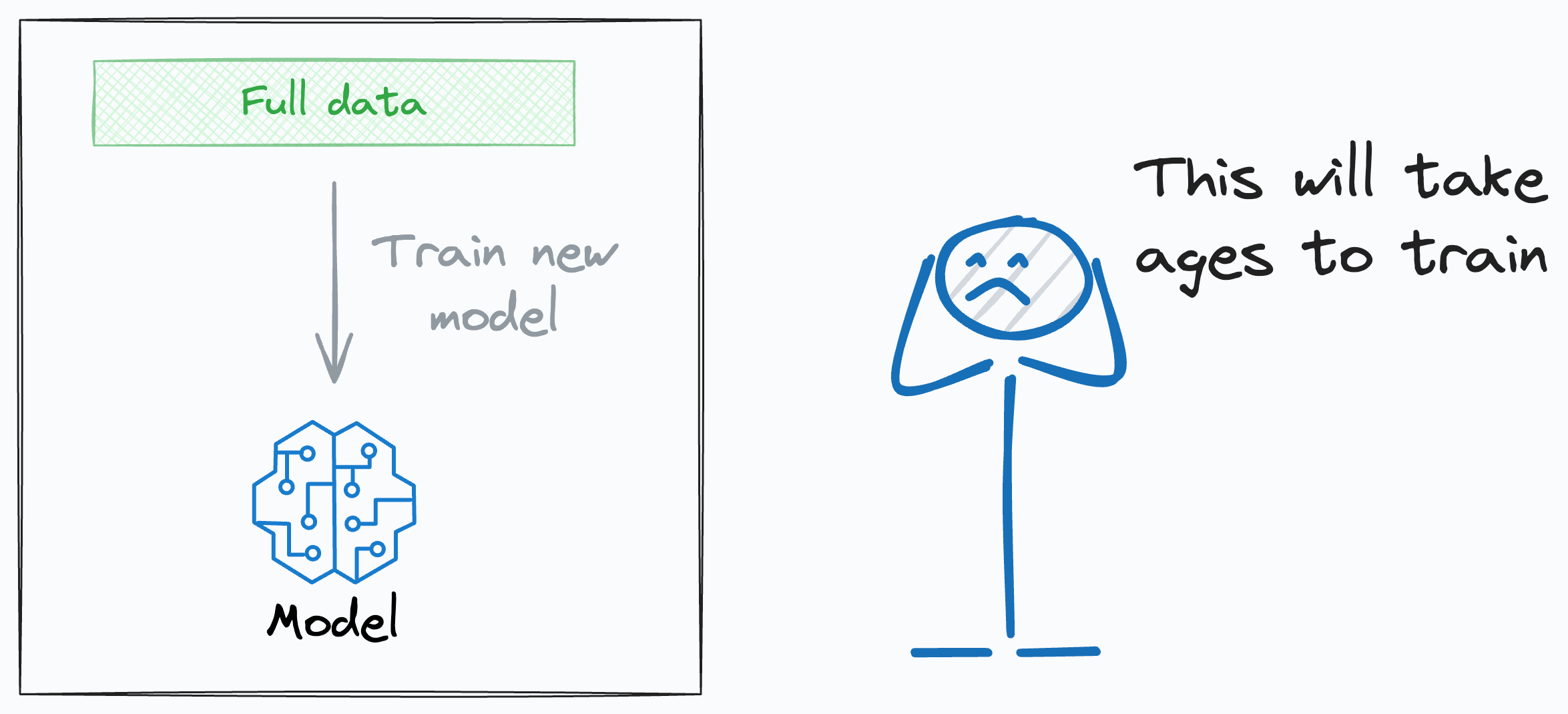
In fact, even if we retrain a new model, there are MANY business situations in which stakes are just too high.
Thus, one can never afford to be negligent about deploying a model without re-evaluating it — transactional fraud, for instance.
In such cases, I have seen that while a team works on productionizing the model, data engineers gather some more data in the meantime.
Before deploying, the team would do some final checks on that dataset.
The newly gathered data is then considered in the subsequent iterations of model improvements.
👉 Over to you: What other considerations would you like to add here?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Great insight, as always ! Thanks Avi Chawla !
Good content, I remember working on a project where cross-validation and retraining played an important role to finalise the model for an imbalanced class dataset classification prioblem.