
Multivariate Covariate Shift — Part 3
Solving critical challenges of real-world model deployment.

Today’s post is the last one in our three-part multivariate covariate shift detection series. Read the first two posts here if you missed them:
Yesterday, we discussed an interesting technique to detect multivariate covariate shift in ML models.
To reiterate, the idea was based on data reconstruction, where in, we learn a mapping that projects the training data to low dimensions and then reconstructs the original data from the low dimensions.
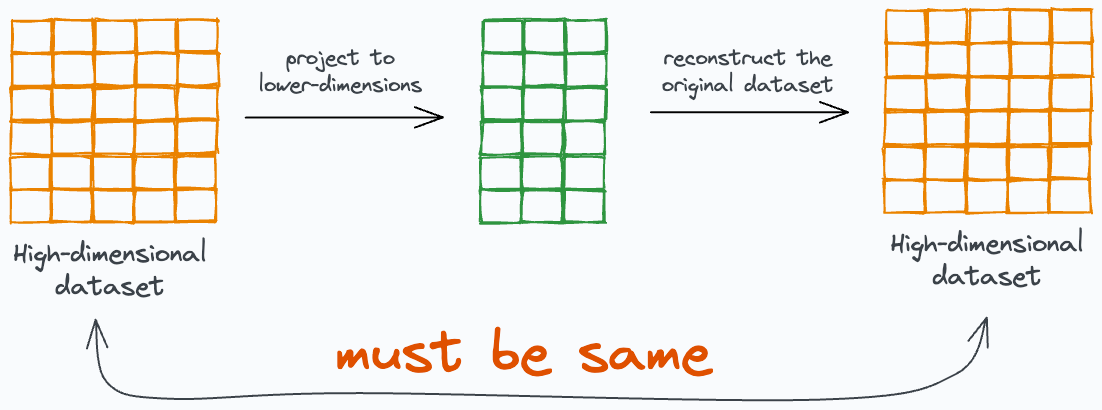
Autoencoders can be used here:

They are neural networks that learn to encode data in a lower-dimensional space, and then decode the original data back.
How to use this model to detect covariate shift?
Consider we have deployed our model, and it is generating predictions on new data.

First, we can train an Autoencoder (or other suitable data reconstruction models) on the training data.

This way, the Autoencoder will capture the essence of our training data and its distribution.
Next, as new data is coming in and the model is making predictions, we can periodically determine the change in data distribution by finding the reconstruction loss on this new data using the Autoencoder model:
If the reconstruction loss is high, it indicates that the distribution has changed.
If the reconstruction loss is low, it indicates that the distribution is almost the same.

But the question is “How do we interpret reconstruction loss?”
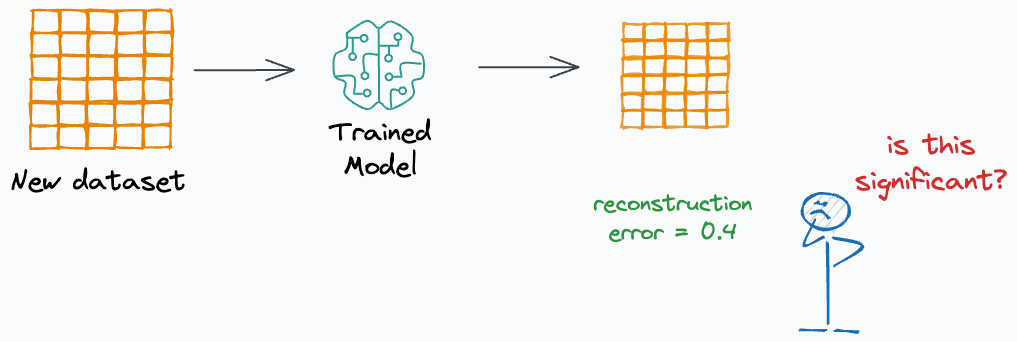
For instance, if the reconstruction loss is 0.4 (say), how do we determine whether this is significant?
We need more context.
Let’s understand how we can solve this problem.
Background
Contrary to what many think, covariate shift happens gradually in ML models.
In other words, it is unlikely that our model is performing pretty well one day, and the next day, it starts underperforming DUE TO COVARIATE SHIFT.

Of course, abrupt degradation is possible but it is rarely due to covariate shift. Most of the time, it happens due to other issues like:
May be due to some compliance issue, the team has stopped collecting a feature. As a result, your model no longer has access to a feature you trained it with.
Or may be there were some updates to the inference logic which was no thoroughly tested.
and more.
But performance degradation happens gradually due to covariate shift.
And in that phase of performance degradation, we must decide to update the model at some point to adjust for distributional changes.

While data reconstruction loss is helpful in deciding model updates, it conveys very little meaning alone.
Simply put, we need a baseline reconstruction loss value to compare our future reconstruction losses.
So here’s what we can do.
Let’s say we decided to review our model every week.
After training the model on the gathered data:

We determine our baseline reconstruction score using the new data gathered over the first week in the post-training phase.
We use this baseline score to compare future losses of every subsequent week.

A high difference between reconstruction loss and the baseline score will indicate a covariate shift.
Simple and intuitive, right?
The above reconstruction metric, coupled with the model performance, becomes a reliable way to determine if covariate shift has stepped in.
Of course, as discussed yesterday, true labels might not be immediately available at times.
Thus, determining performance in production can be difficult.
To counter this, all ML teams consistently try to gather feedback from the end user to learn if the model did well or not.

This is especially seen in recommendation systems:
Was this advertisement relevant to you?
Was this new video relevant to you?
And more.
These things are a part of the model logging phase, where we track model performance in production.
This helps us decide whether we should update our model or not.
However, model updates are not done like: “Train a new model today and delete the previous one.”
Never!
Instead, all deployments are driven by proper version controlling.
I have written multiple deep dives on deployment version controlling, which you can read next to learn this critical real-world ML development skill:
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
You Cannot Build Large Data Projects Until You Learn Data Version Control
Model Compression: A Critical Step Towards Efficient Machine Learning
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
👉 Over to you: What are some other ways to detect covariate shift in ML models?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
1. what if we just label all the data except the last week as 0, the last week as 1 and build a classifier? In case there is no difference between them ROC AUC will be near 0.5. Then repeat this procedure once per week, until the metric is statistically different from 0.5 -- a signal to retrain the model?
2. In many cases, when applicable, just retrain the model once per week without even checking for covariance shift. Just keep track on CV score sending an alert if the new quality is lower than expected