
Multivariate Covariate Shift — Part 1
Here's what most people overlook when detecting covariate shift.

Almost all real-world ML models gradually degrade in performance due to covariate shift.

For starters, covariate shift happens when the distribution of features changes over time, but the true (natural) relationship between input and output remains the same. We have already discussed it in detail before.
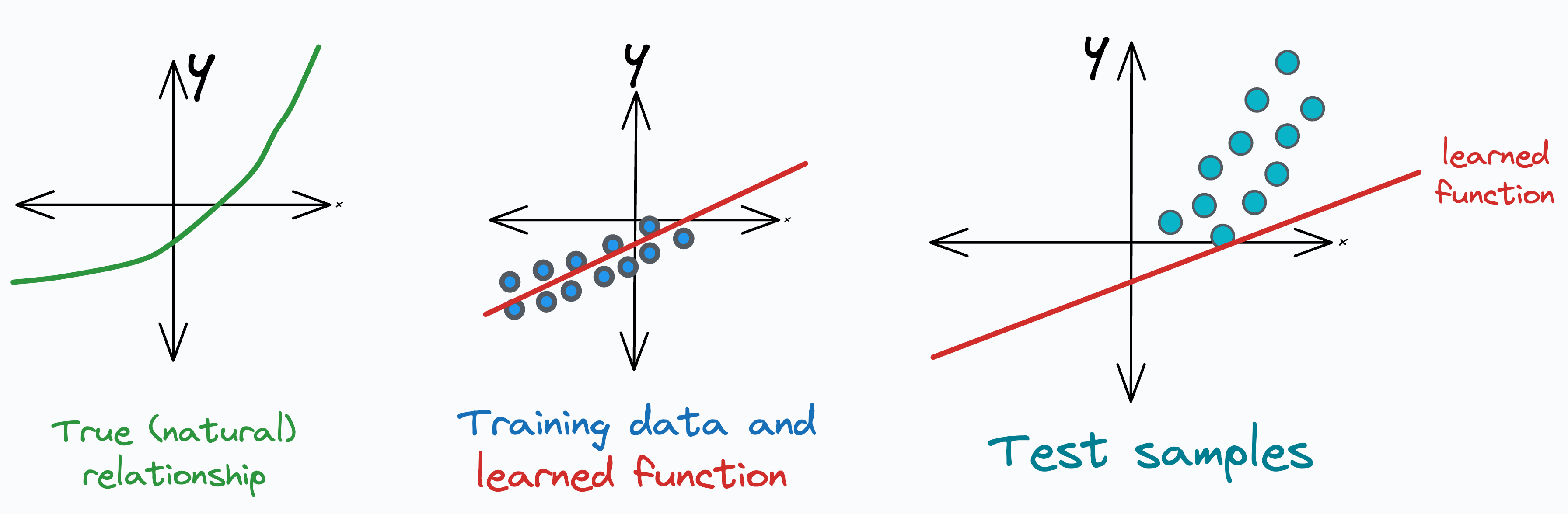
It is a serious problem because we trained the model on one distribution, but it is being used to predict on another distribution in production.
Thus, it is critical to detect covariate shift early so that models continue to work well.
One of the most common and intuitive ways to detect covariate shift is by simply comparing the feature distribution in training data to that in production.

This could be done in many ways, such as:
Compare their summary statistics — mean, median, etc.
Inspect visually using distribution plots.
Perform hypothesis testing.
Measure distances between training/production distributions using Bhattacharyya distance, KS test, etc.
While these approaches are often effective, the biggest problem is that they work on a single feature at a time.
But, in real life, we may observe multivariate covariate shift as well.
Multivariate covariate shift happens when:
The distribution of individual distributions remains the same:
P(X1) and P(X2) individually remain the same.
But their joint distribution changes:
P(X1, X2) changes.
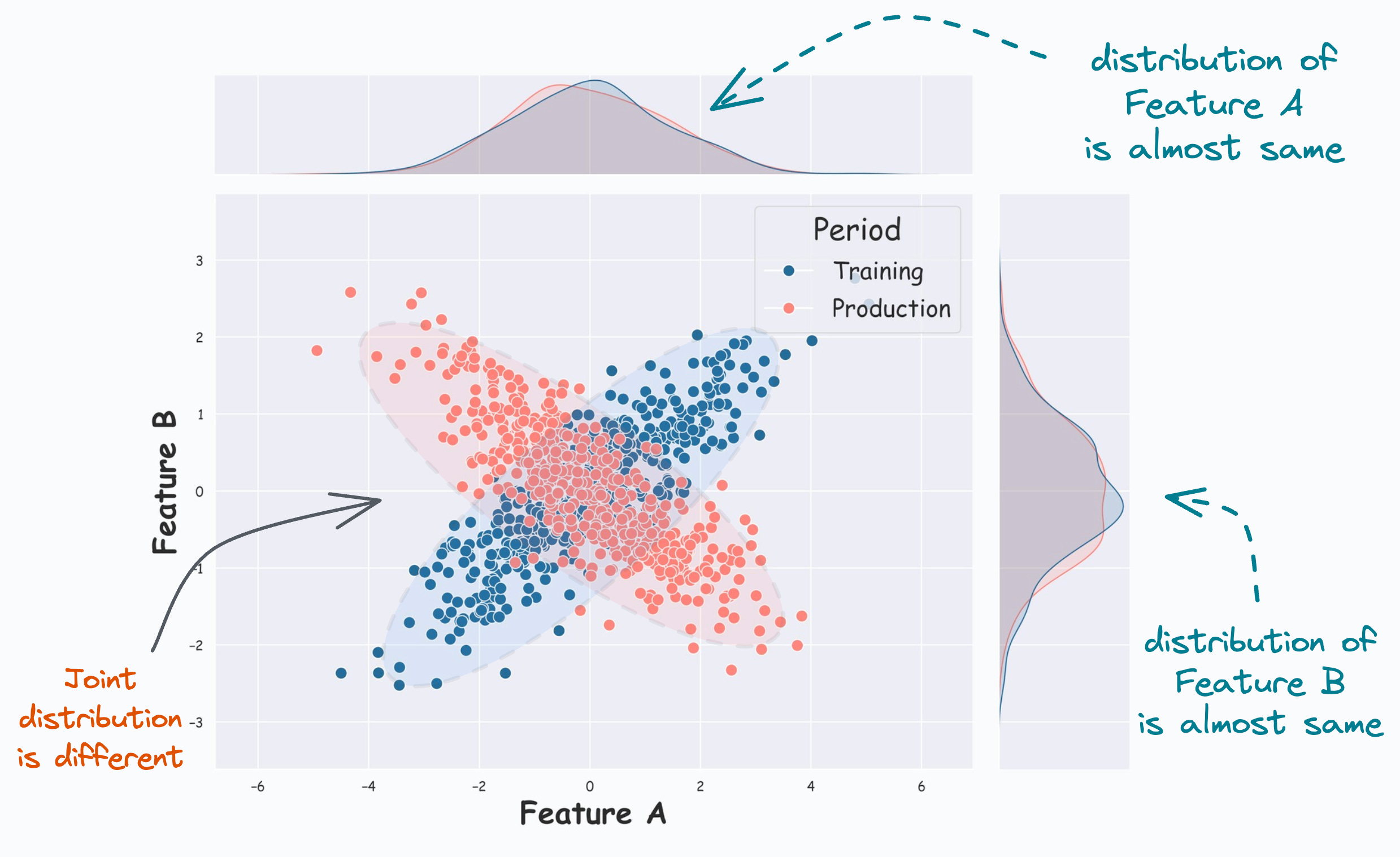
This is evident from the image below:
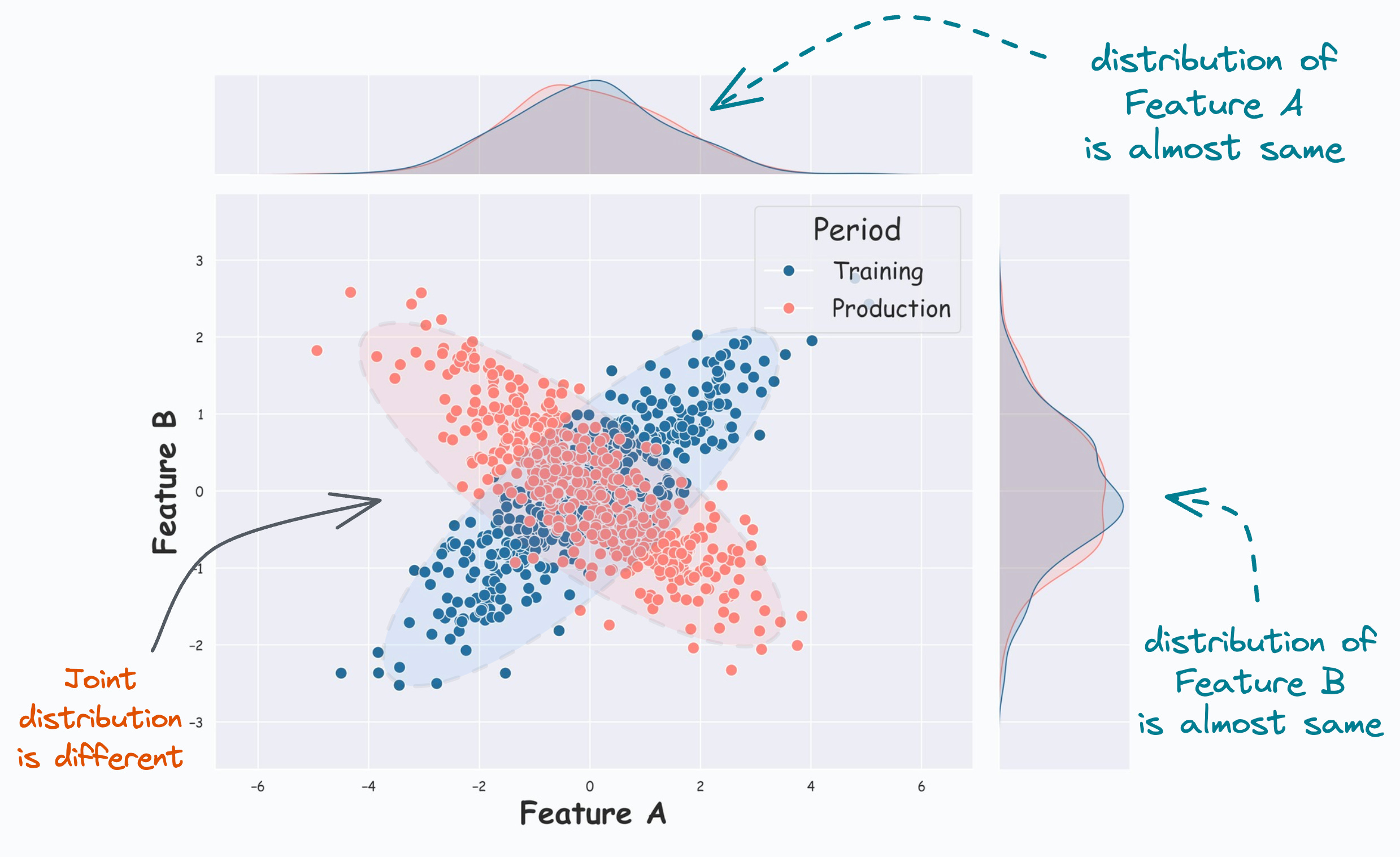
From the KDE plots on the top and the right, it is clear that the distribution of both features (covariates) is almost the same.
But, the scatter plot reveals that their joint distribution in training (Blue) differs from that in production (Red).
And it is easy to guess that the univariate covariate shift detection methods discussed above will produce misleading results.
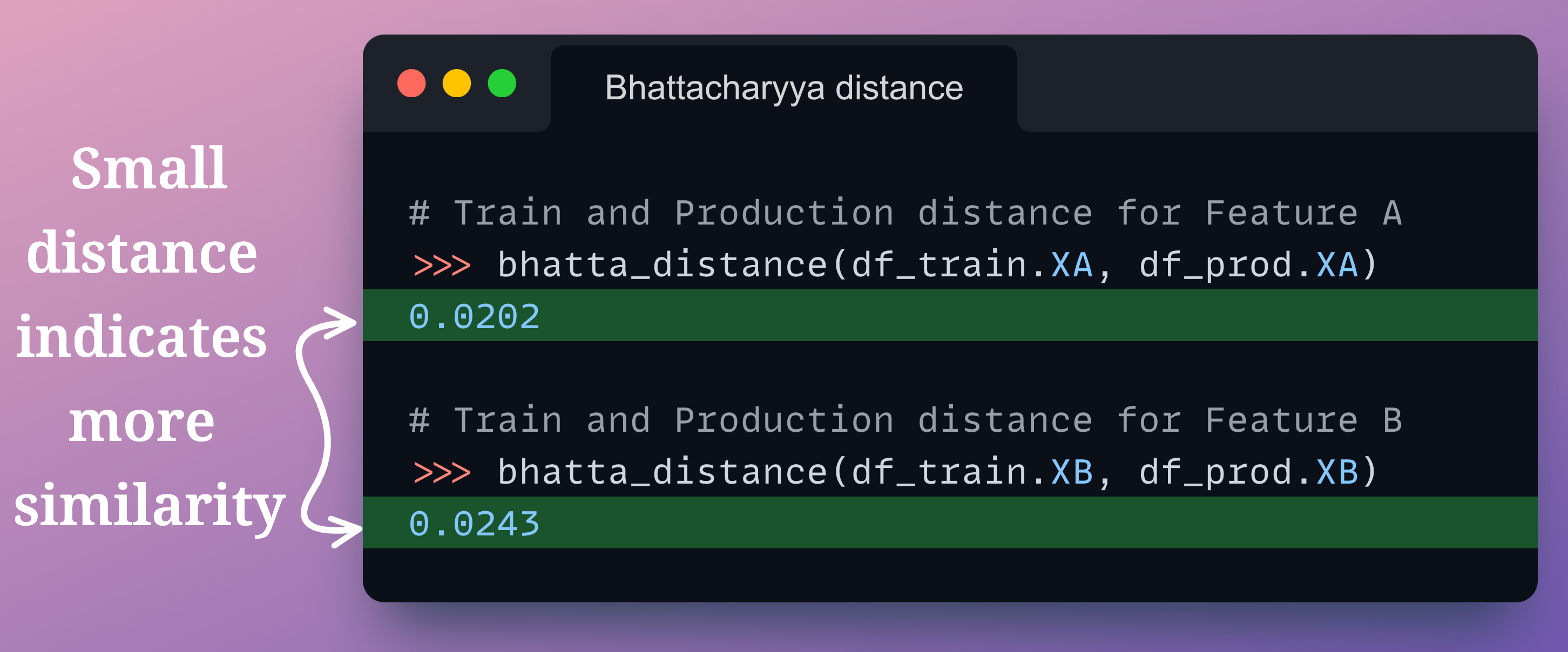
For instance, as demonstrated below, measuring the Bhattacharyya distance between a training and production feature gives a very low distance value, indicating high similarity:
In fact, even though the individual feature distribution is the same, we can confirm experimentally that this will result in a drop in model performance:
Let’s say the true output y = 2*Feature_A + 3*Feature_B + noise.
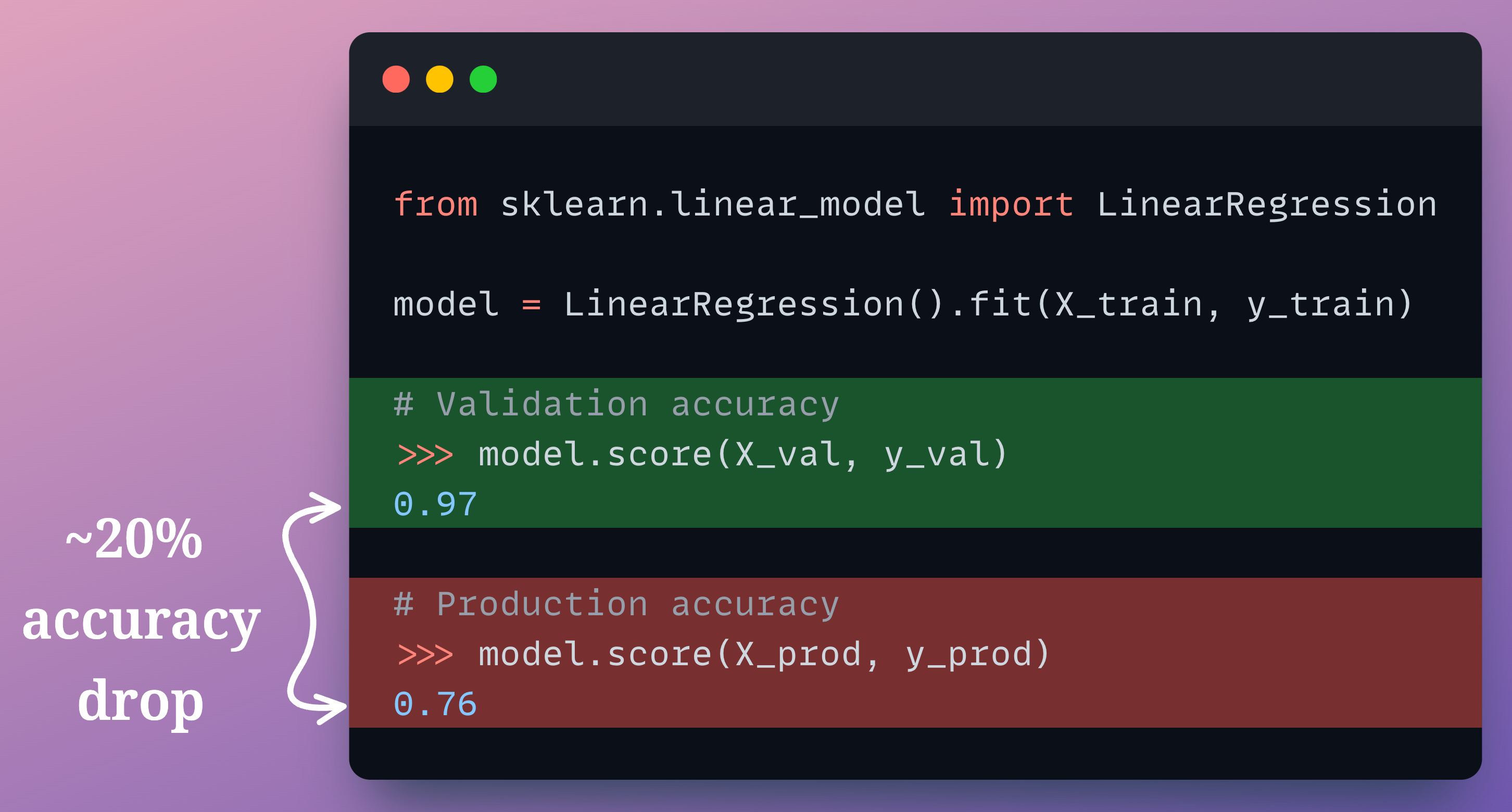
In most cases, the true output predictions on production data are not immediately available. In the above demonstration, just assume that we have already gathered the true predictions somehow.
As depicted above, the model performance drops by 20% in production, which is huge.
Here, we may completely rule out the possibility of covariate shift if we think that covariate shift can never be multivariate in nature.
Of course, in the figure below, it was easy to identify multivariate covariate shift because we are only looking at two features.
But multivariate covariate shift can happen with more than two features as well.
Unlike the bivariate case above, visual inspection will not be possible for higher dimensions.
Now you know the problem.
So how can we detect this?
Today, instead of proposing the solution myself, I want you to give this problem a thought.
More specifically, you have to think about:
How can we detect multivariate covariate shift?
We will continue the discussion tomorrow, but in the meantime, I would love to hear from you :)
Multivariate covariate shift is a common problem that many real-world ML models suffer from.
Thus, it is critical to detect covariate shift early so that models continue to work as expected.
I am eagerly waiting to hear from you.
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Just discovered this newsletter! It is really clarifying and beginner-friendly
How about using correlation matrix and monitoring for changes?