
The Most Overlooked Source of Optimization in Data Pipelines
Sometimes, the pain point can be outside your code.

Most data science pipelines involve some interaction with a storage source:
Either they load the data from disk,
Or they store the output to a disk,
Or both.
Now, in my experience, most programmers dedicate optimization efforts (run-time and memory) to the algorithmic side.
But very few realize the profound improvement they can get by optimizing the I/O-related operations.

This is because when it comes to data, the most common storage option is a CSV.
But unknown to many, they are among the most time-inefficient and storage-inefficient storage formats you could ever utilize in your data pipeline.
If you use CSVs all the time, then this post is for you.
Let’s understand in detail!
In addition to a CSV, there are various other options that we can dump a DataFrame to:

So comparing their performance on the following parameters can be pretty useful to optimize our data pipeline:
The space they occupy on disk.
The read and write run-time.
To conduct this experiment, I created a dummy dataset with:
1M rows
20 columns:
Case 1: With only numerical columns.
Case 2: With 10 numerical and 10 string columns.
The following visual depicts the memory utilization of these DataFrames (Case 1 and Case 2) when stored in each of the above formats:
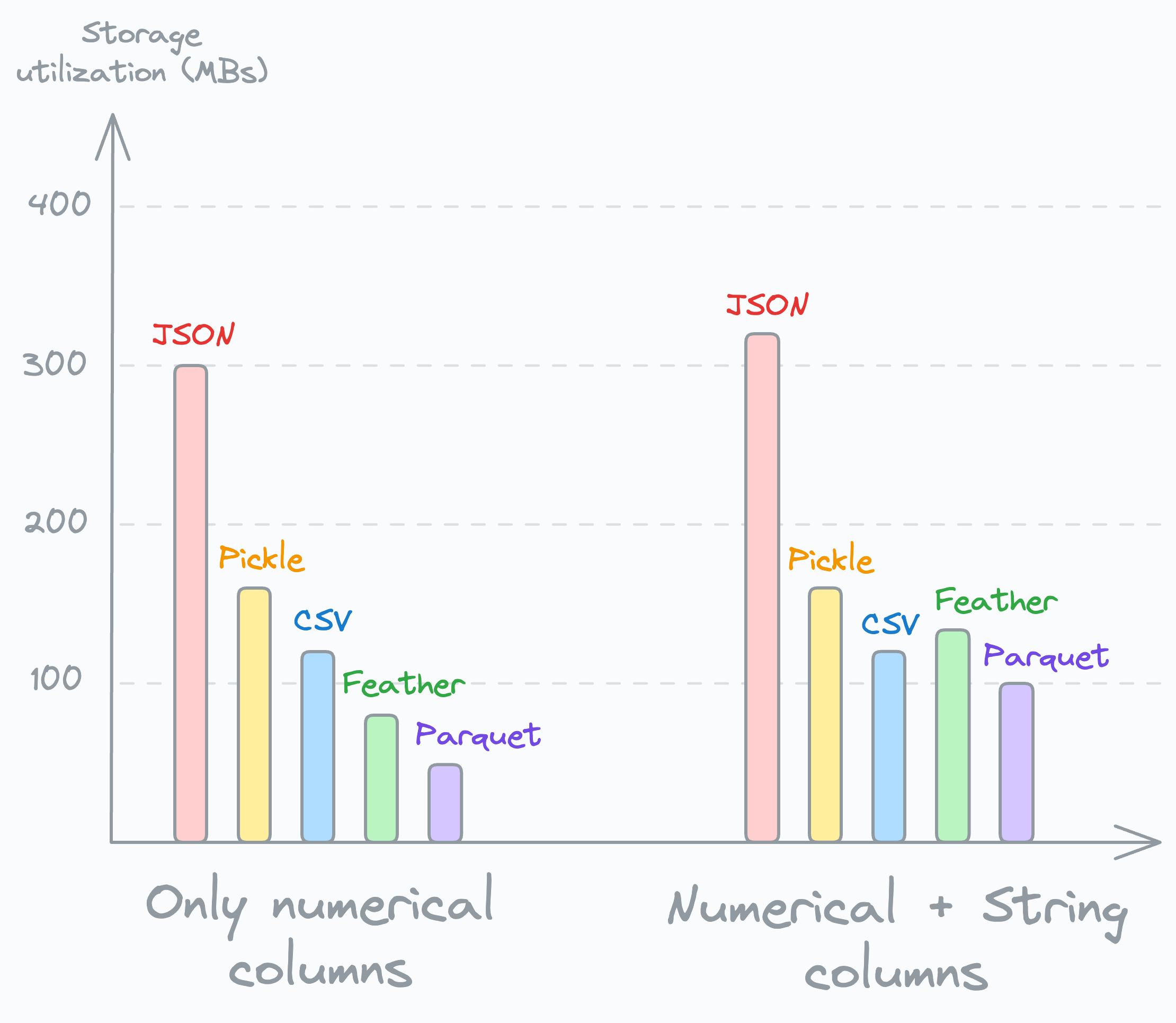
As depicted above:
In both cases, CSVs are not the most optimal format to dump DataFrame to.
For numerical data, Parquet consumes over 2x less space than CSV.
For numerical data, Feather is also promising.
In the case of mixed columns, except JSON, all formats take up almost equal space.
Next, the following visual depicts the run-time to store the DataFrame in those formats:

As depicted above:
Saving a DataFrame to pickle is ridiculously faster than CSV when we only have numerical columns. But this run-time drastically increases when we have mixed columns.
Feather appears to be a clear winner because it has the least saving run-time in both cases. Also, recalling the storage results above, the Feather format was among the most promising formats.
Here, the Parquet format is also promising.
Finally, the following visual depicts the run-time to load the DataFrame from memory when stored in those formats:

As depicted above:
Read time from Pickle, Feather, and Parquet is the lowest when we have numerical columns. But Parquet’s read time drastically increases when we have mixed columns.
Yet again, Feather appears to be the most promising format, with low run-time in both cases.
Putting it all together
I understand this might be a lot of information, so let me summarize it and provide clear action steps.
CSVs are rarely an optimal choice:
The only reason you would want to use them is when you want to open the data in tools like Excel.
Another reason is when you want to constantly append new data to the CSV file. Other formats do not support this operation.
In addition to memory and run-time issues, another problem is that CSVs cannot preserve data type information.
For instance, if you change the data type of a column (from, say,
inttostr) → store the DataFrame to a CSV → load it back, CSV format will not preserve the data type change.After loading the DataFrame, you will get back the
intdata type for that column.
Pickle is a promising choice:
Pickle’s storage utilization is unaffected by file format.
But its read and write run-time suffers in the case of mixed columns.
Also, remember that the pickle format is Python-specific. You are restricted to Python when you use it.
That being said, unlike CSVs, Pickle preserves data type information.
Comparing Feather and Parquet:
Feather consumes slightly more memory, but it’s the most optimal choice for run-time improvements.
Parquet is good, but similar to the Pickle format, it is well suited for numerical data only.
If your priority is to minimize storage utilization, Parquet is better.
If your priority is to optimize run-time, Feather is better.
Of course, please note that these experiments may not entirely translate to every use case.
The idea of this post was to:
Make you aware of the problems CSV format imposes.
Share insights on what is typically the most optimal choice and when.
If you want to run this experiment yourself, download this notebook: Storage Format Optimization Experiment.
👉 Over to you: What are some other sources of optimization in data pipelines that many overlook?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
I presume that all of the figures were calculated using a single node/CPU.
My usage of parquet has been on clusters of multiple nodes running on cloud environments (AWS,Databricks) atop S3 storage. If a very large dataset has been "sharded" into, say, 20 parquet files, and if the cluster is running a like number (20) of nodes, then reading and writing the dataset to/from parquet can be lightning-fast.
It would be interesting to rerun the analysis on clusters of varying sizes where formats such as parquet would benefit from the parallelization while other formats may not.
Worthwhile to investigate all sorts of potyential optimization areas...On my machine I tend to think of the multiple things I'm running locall rather that connections as I have a fiber connection..but that is not necessarily the case.