
Train Classical ML Models on Large Datasets
Extending the Bagging objective.

An update on student discounts
Student discounts are difficult to automate. It is handled on a case-by-case basis, which takes up quite some time.
So, I have decided to release slots for student discounts once every 4 months.
The current slot will remain active till Sunday, and we will have the next slots in August.
Fill out this form and provide the details to get a student discount: Student Discount Form. I will onboard you this week if you are eligible.
Let’s get to today’s post now.
The problem
Most classical ML algorithms cannot be trained with a batch implementation. This limits their usage to only small/intermediate datasets.
For instance, this is the list of sklearn implementations that support a batch API:

It’s pretty small, isn’t it?
This is concerning because, in the enterprise space, the data is primarily tabular. Classical ML techniques, such as tree-based ensemble methods, are frequently used for modeling.
However, typical implementations of these models are not “big-data-friendly” because they require the entire dataset to be present in memory.
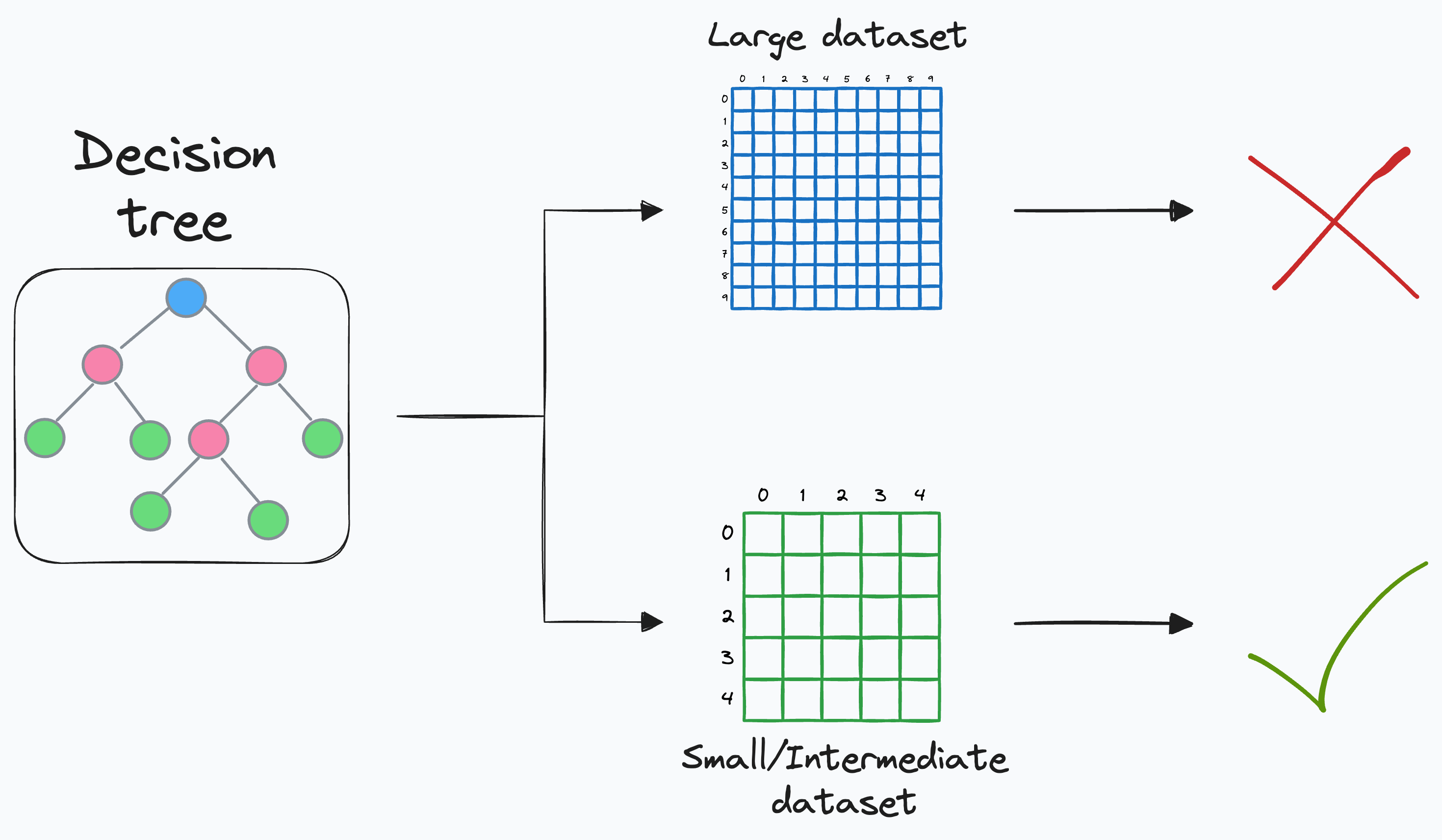
There are two ways to approach this:
The first way is to use big-data frameworks like Spark MLlib to train them. We covered this here: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
There’s one more way, which Dr. Gilles Louppe discussed in his PhD thesis — Understanding Random Forests.
Here’s what he proposed.
Random Patches
Before explaining, note that this approach will only work in an ensemble setting. So, you would have to train multiple models.
The idea is to sample random data patches (rows and columns) and train a tree model on them.

Repeat this step multiple times by generating different patches of data randomly to obtain the entire random forest model.
The efficacy?
The thesis presents many benchmarks (check pages 174 and 178 if you need more details) on 13 datasets, and the results are shown below:

From the above image, it is clear that in most cases, the random patches approach performs better than the traditional random forest.
In other cases, there wasn’t a significant difference in performance.
And this is how we can train a random forest model on large datasets that do not fit into memory.
Why does it work?
While the thesis did not provide a clear intuition behind this, I can understand why such an approach would still be as effective as random forest.
It’s the same idea we discussed in the Bagging article, which allowed us to build our own variant of a Bagging algorithm: Why Bagging is So Ridiculously Effective At Variance Reduction?
In a gist, building trees that are as different as possible guarantees a greater reduction in variance.
In this case, the dataset overlap between any two trees is NOT expected to be huge compared to the typical random forest. This aids in the Bagging objective.
For more information, check this out: Why Bagging is So Ridiculously Effective At Variance Reduction?
Also, in a recent issue, we discussed a cool technique to condense a random forest into a decision tree:
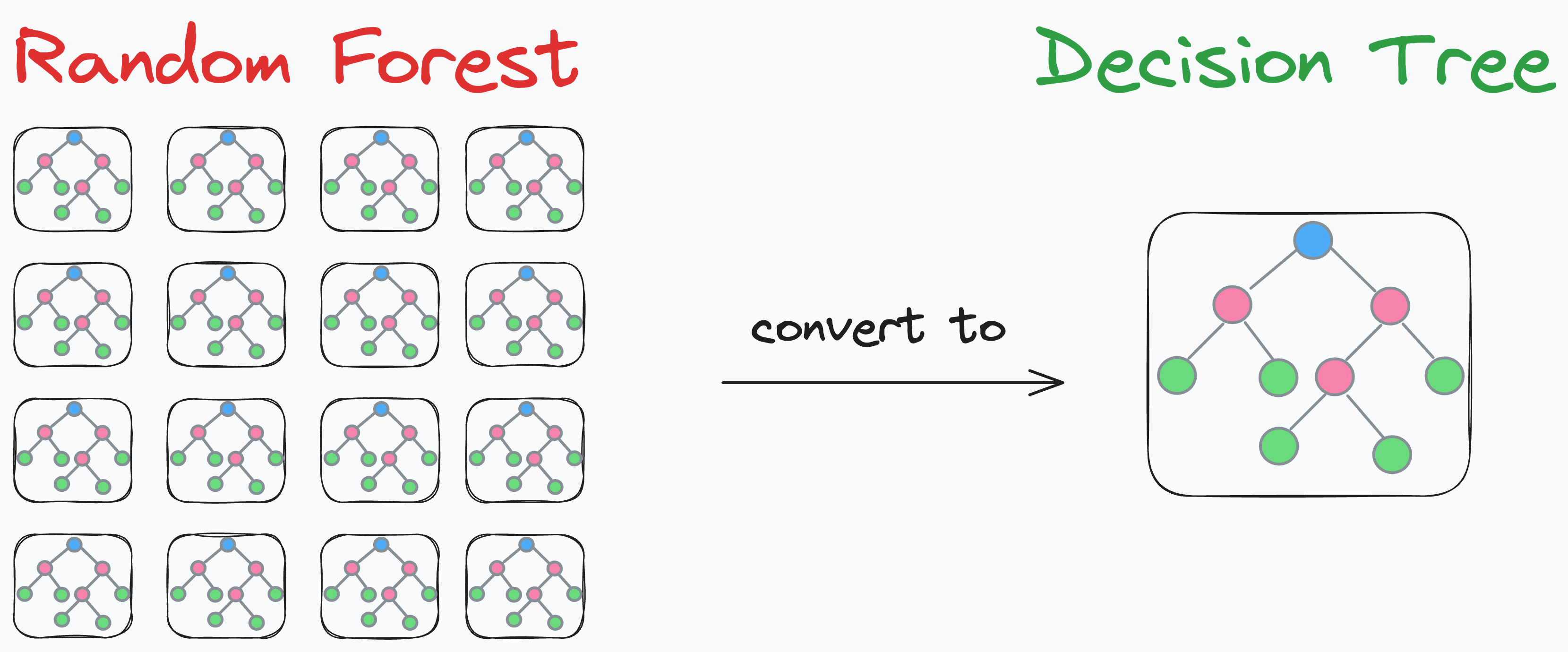
This allowed us to:
Decrease the prediction run-time (shown below).

Improve interpretability.
Reduce the memory footprint.
Simplify the model.
Preserve the generalization power of the random forest model (shown below).
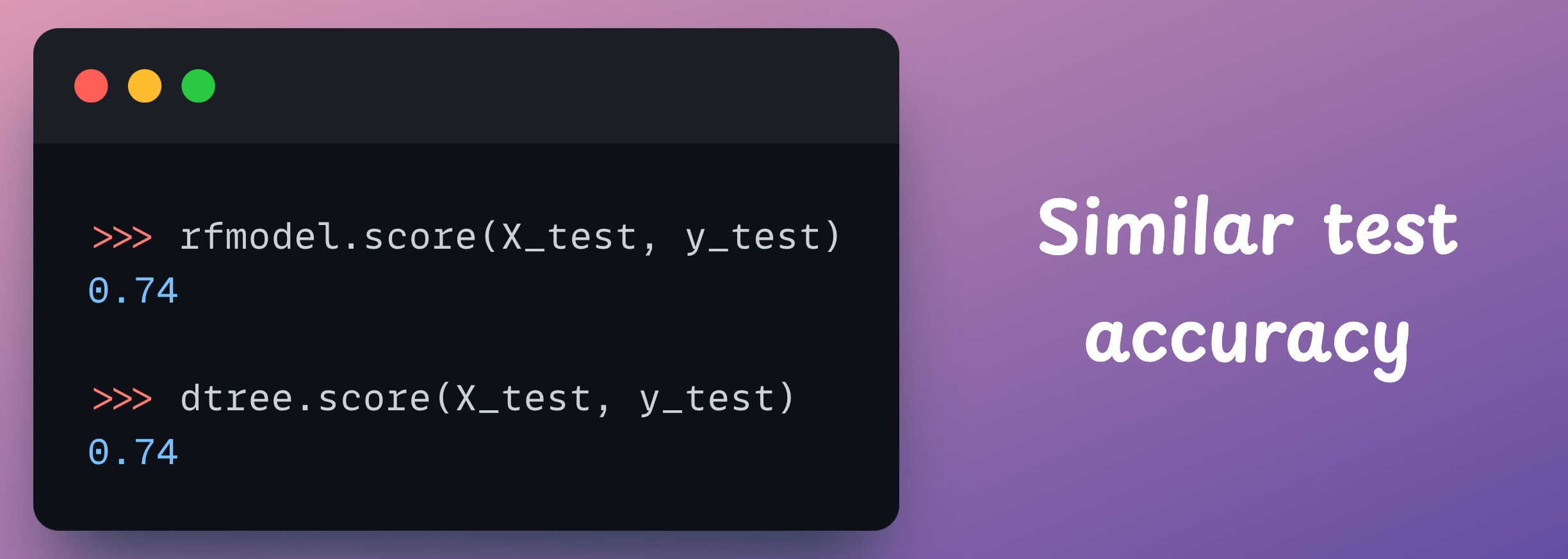
Read it here: Condense Random Forest into a Decision Tree.
👉 Over to you: Do you know any other way to train a random forest on a large dataset?
Thanks for reading!
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
“In this case, the dataset overlap between any two trees is expected to be huge compared to the typical random forest.”
Is this a typo, or did I misunderstand? In a batching context isn’t the batch size normally much smaller than the whole dataset? And wouldn’t that imply minimal overlap in datasets between trees compared to a typical random forest? I agree though this would aid the bagging objective and reduce bias.