
Train Large ML Models With Activation Checkpointing
...without running out of memory.

Neural networks primarily utilize memory in two ways:

When they store model weights (this is fixed memory utilization).
When they are trained (this is dynamic). It happens in two ways:
During forward pass while computing and storing activations of all layers.
During backward pass while computing gradients at each layer.
The latter, i.e., dynamic memory utilization, often restricts us from training larger models with bigger batch sizes.

This is because memory utilization scales proportionately with the batch size.
That said, there’s a pretty incredible technique that lets us increase the batch size while maintaining the overall memory utilization.
It is called Activation checkpointing, and in my experience, it’s a highly underrated technique to reduce the memory overheads of neural networks.
Let’s understand this in more detail.
While activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation)
How does Activation checkpointing work?
Activation checkpointing is based on two key observations on how neural networks typically work:
The activations of a specific layer can be solely computed using the activations of the previous layer. For instance, in the image below, “Layer B” activations can be computed from “Layer A” activations only:

Updating the weights of a layer only depends on two things:
The activations of that layer.
The gradients computed in the next (right) layer (or rather, the running gradients).

Activation checkpointing exploits these two observations to optimize memory utilization.
Here’s how it works:
Step 1) Divide the network into segments before the forward pass:
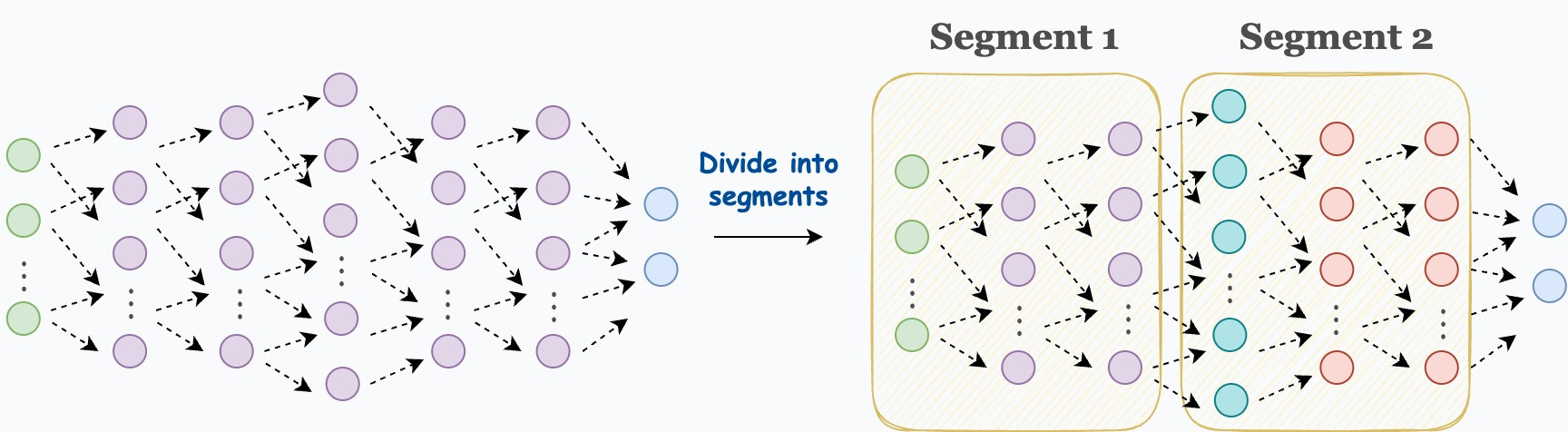
Step 2) During the forward pass, only store the activations of the first layer in each segment. Discard the rest when they have been used to compute the activations of the next layer.
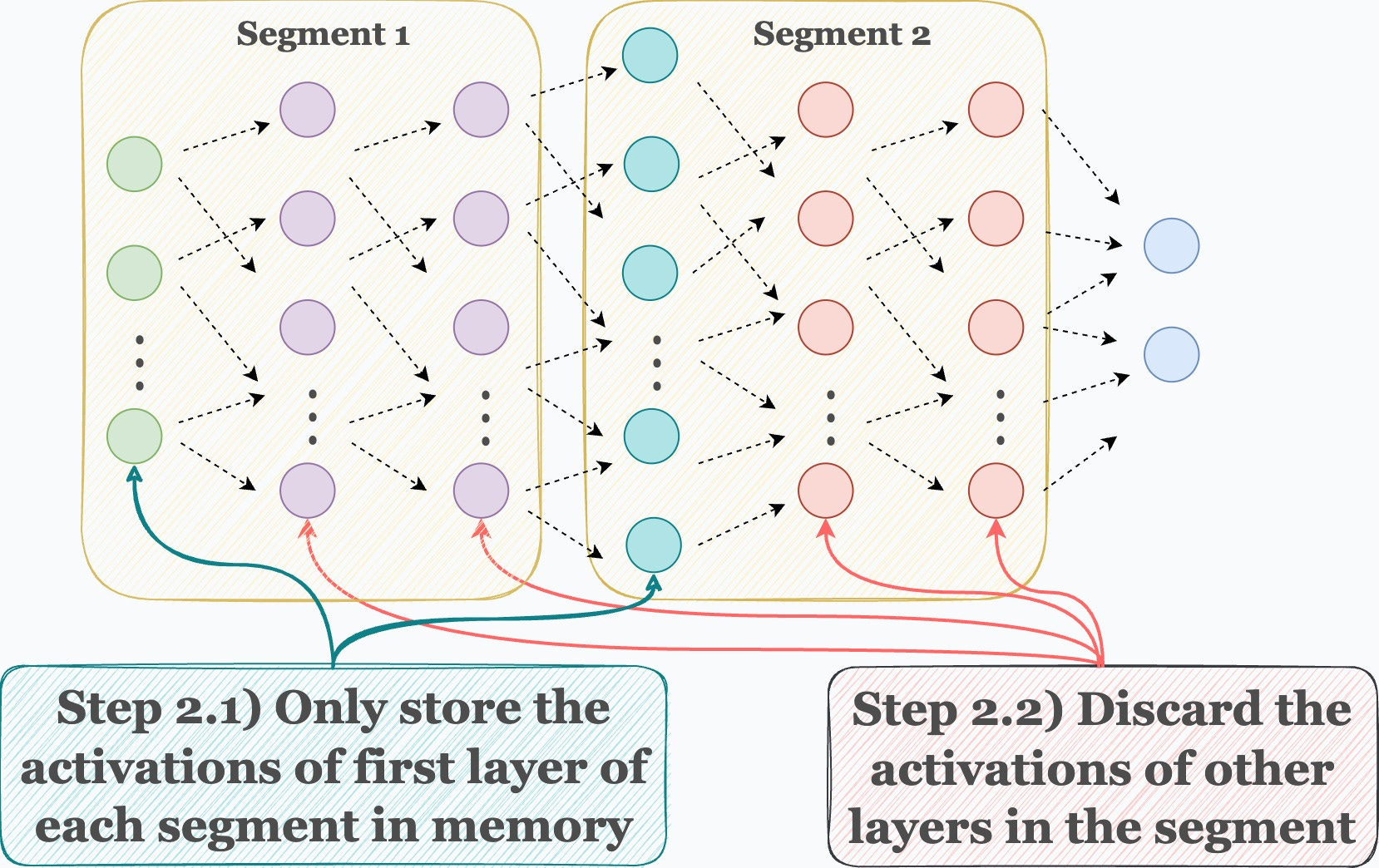
Step 3) Now comes backpropagation. To update the weights of a layer, we need its activations. Thus, we recompute those activations using the first layer in that segment.
For instance, as shown in the image below, to update the weights of the red layers, we recompute their activations using the activations of the cyan layer, which are already available in memory.
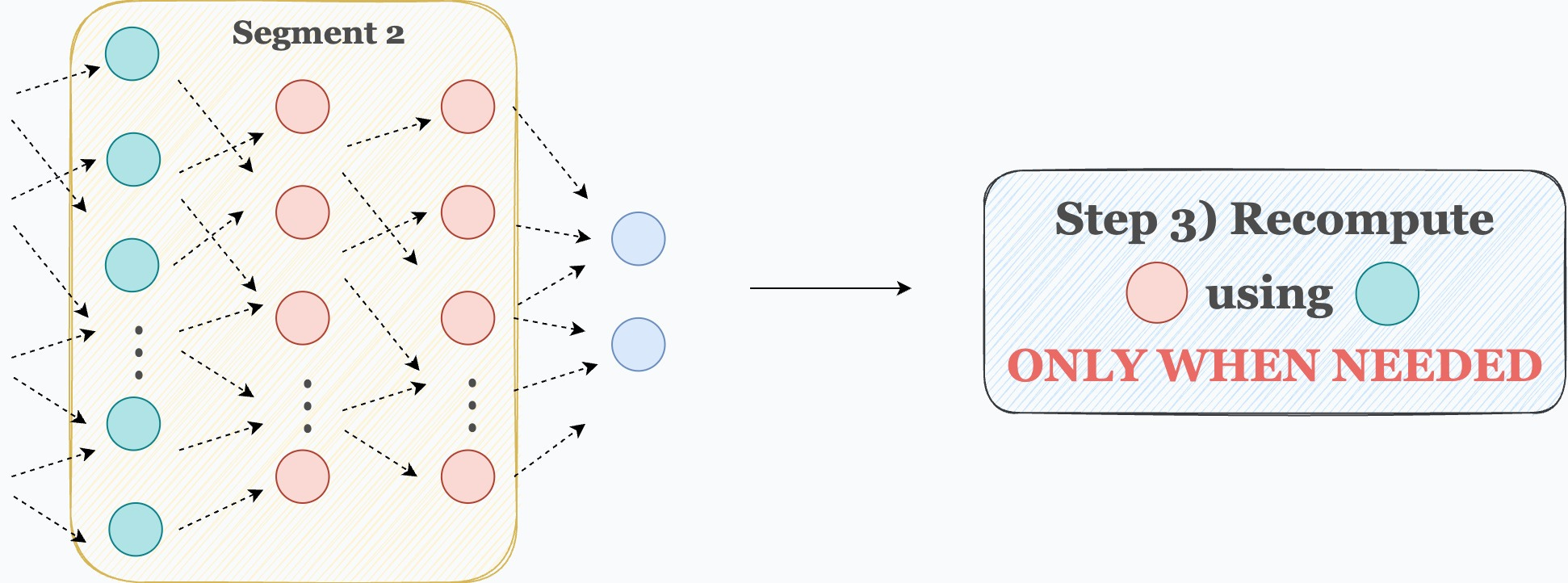
Done!
This is how Activation checkpointing works.
To summarize, the idea is that we don’t need to store all the intermediate activations in memory.
Instead, storing a few of them and recomputing the rest only when they are needed can significantly reduce the memory requirement.
The whole idea makes intuitive sense as well.
In fact, this also allows us to train the network on larger batches of data.
Typically, activation checkpointing can reduce memory usage to sqrt(M), where M is the memory usage without activation checkpointing.

Of course, as we compute some activations twice, this does come at the cost of increased run-time, which can typically range between 15-25%.
So there’s always a tradeoff between memory and run-time.

That said, another advantage is that it allows us to use a larger batch size, which can slightly (not entirely though) counter the increased run-time.
Nonetheless, activation checkpointing is an extremely powerful technique to train larger models, which I have found to be pretty helpful at times, without resorting to more intensive techniques like distributed training, for instance.
Thankfully, activation checkpointing is also implemented by many open-source deep learning frameworks like Pytorch, etc.
Activation checkpointing in PyTorch
To utilize this, we begin by importing the necessary libraries and functions:

Next, we define our neural network:

As demonstrated above, in the forward method, we use the checkpoint_sequential method to use activation checkpointing and divide the network into two segments.
Next, we can proceed with network training as we usually would.
Pretty simple, isn’t it?
While activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation).
Also, if you want to understand how models like GPT end up using so much memory during training, I highly recommend reading this newsletter issue:

For more context, one can barely train a 3GB GPT-2 model on a single GPU with 32GB of memory.
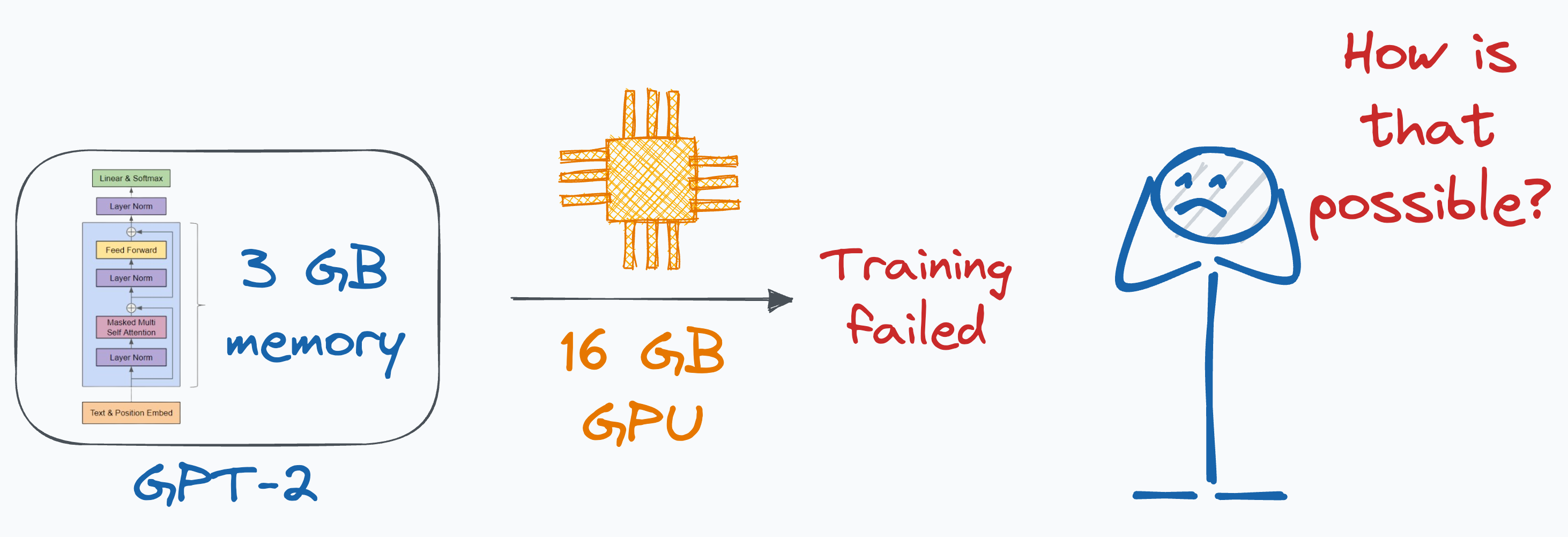
But how could that be even possible? Where does all the memory go?
The above newsletter issue explains this in detail.
👉 Over to you: What are some ways you use to optimize a neural network’s training?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 100,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.