
Where Did the GPU Memory Go?
Estimating memory consumption of GPT-2.

Launching big data analytics projects can take days.
Currently, one must manually integrate the technologies for their data analytics projects, like cluster, data source, and compute resource, and then test these integrations.
DoubleCloud simplifies this and reduces the project launch time to just a few minutes.
Setting up a data analytics project is as simple as selecting technologies from a dropdown, and DoubleCloud takes care of the integration procedures.

I read on their website that DoubleCloud’s customers like:
LSports reduced query speed by 180x compared to MySQL.
Honeybadger experienced a 30x boost compared to Elasticsearch.
Spectrio cut costs by 30-40% compared to Snowflake.

Join below:
I recently wrote a newsletter issue about DoubleCloud in case you missed it: How To Simplify ANY Data Analytics Project with DoubleCloud?
Thanks to DoubleCloud for partnering today!
Where Did the GPU Memory Go?
Let’s start today’s issue with a question.
GPT-2 (XL) has 1.5 Billion parameters, and its parameters consume ~3GB of memory in 16-bit precision.

Under 16-bit precision, one parameter takes up 2 bytes of memory, so 1.5B parameters will consume 3GB of memory.
What’s your estimate for the minimum memory needed to train GPT-2 on a single GPU?
Optimizer → Adam
Batch size → 32
Number of transformer layers → 48
Sequence length → 1000
The answer might surprise you.
One can barely train a 3GB GPT-2 model on a single GPU with 32GB of memory.
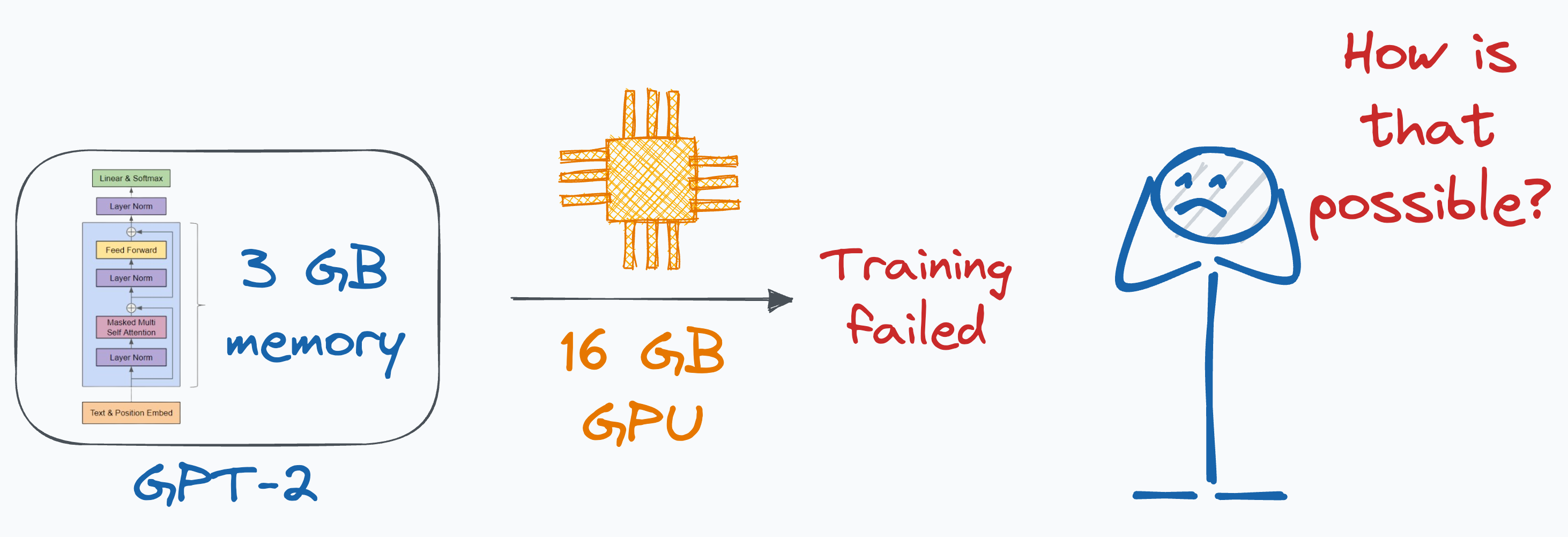
But how could that be even possible? Where does all the memory go?
Let’s understand today!
There are so many fronts on which the model consistently takes up memory during training.
#1) Optimizer states, gradients, and parameter memory
Mixed precision training is widely used to speed up model training.
As the name suggests, the idea is to utilize lower-precision float16 (wherever feasible, like in convolutions and matrix multiplications) along with float32 — that is why the name “mixed precision.”
If you recall the newsletter issue on Mixed precision training, both the forward and backward propagation are performed using the 16-bit representations of weights and gradients.
Thus, if the model has Φ parameters, then:
Weights will consume 2*Φ bytes.
Gradients will consume 2*Φ bytes.
Here, the figure “2” represents a memory consumption of 2 bytes/paramter (16-bit).
Moreover, the updates at the end of the backward propagation are still performed under 32-bit for effective computation. I am talking about the circled step in the image below:
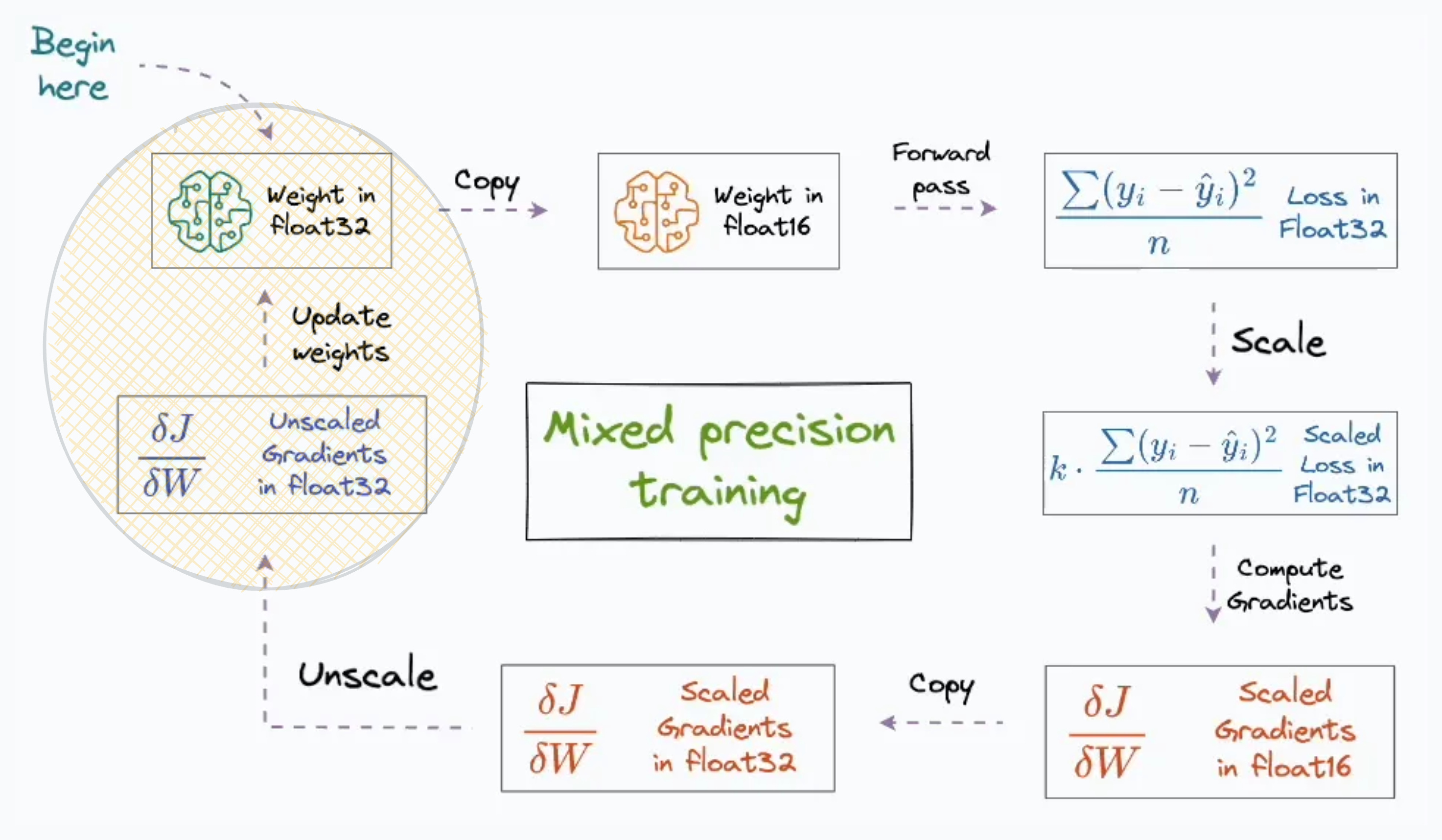
Adam is one of the most popular optimizers for model training.
While many practitioners use it just because it is popular, they don’t realize that during training, Adam stores two optimizer states to compute the updates — momentum and variance of the gradients:

Thus, if the model has Φ parameters, then these two optimizer states will consume:
4*Φ bytes for momentum.
Another 4*Φ bytes for variance.
Here, the figure “4” represents a memory consumption of 4 bytes/paramter (32-bit).
Lastly, as shown in the figure above, the final updates are always adjusted in the 32-bit representation of the model weights. This leads to:
Another 4*Φ bytes for model parameters.
Let’s sum them up:
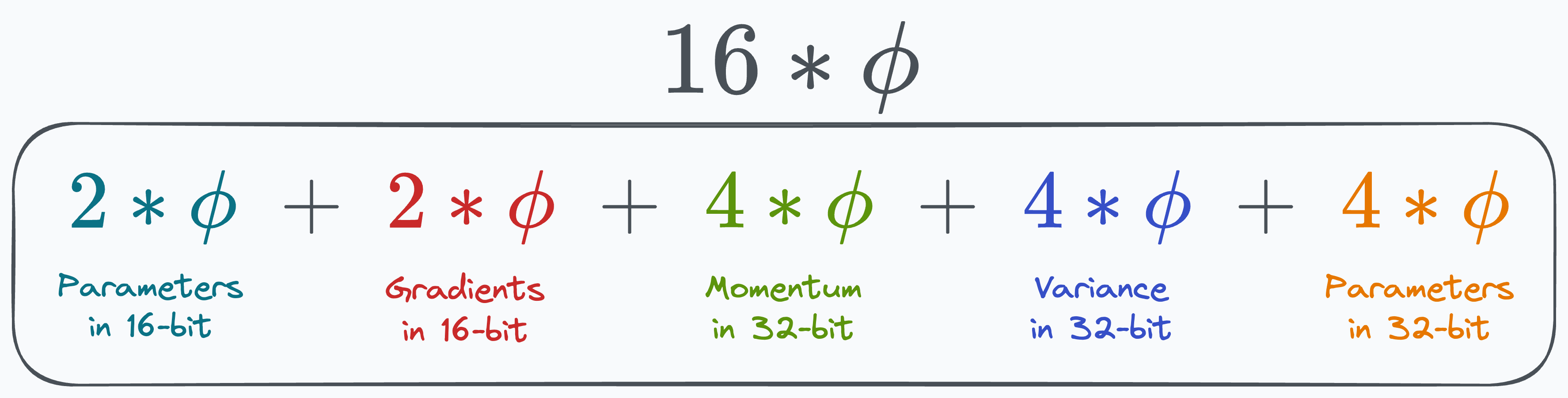
That’s 16*Φ, or 24GB of memory, which is ridiculously higher than the 3GB memory utilized by 16-bit parameters.
And we haven’t considered everything yet.
#2) Activations
For big deep learning models, like LLMs, Activations take up significant memory during training.
More formally, the total number of activations computed in one transform block of GPT-2 are:

Thus, across all transformer blocks, this comes out to be:

This is the configuration for GPT2-XL:

This comes out to be ~30B activations. As each activation is represented in 16-bit, all activations collectively consume 60GB of memory.
With techniques like activation checkpointing (we discussed it here), this could be brought down to about 8-9GB at the expense of 25-30% more run-time.
The following visual depicts how it works:

Step 1) Divide the network into segments before the forward pass.
Step 2.1) During the forward pass, only store the activations of the first layer in each segment.
Step 2.2) Discard the rest when they have been used to compute the activations of the next layer.
Step 3) Now, we must run backpropagation. To update the weights of a layer, we need its activations. Thus, recompute those activations using the first layer in that segment.
This technique takes complete memory consumption to about 32-35GB range, which I mentioned earlier, for a meager 3GB model, and that too with a pretty small batch size of just 32.
On top of this, there are also some more overheads involved, like memory fragmentation.
It occurs when there are small, unused gaps between allocated memory blocks, leading to inefficient use of the available memory.

Memory allocation requests fail because of the unavailability of contiguous memory blocks.
Conclusion
In the above discussion, we considered a relatively small model — GPT-2 (XL) with 1.5 Billion parameters, which is tiny compared to the scale of models being trained these days.
However, the discussion may have helped you reflect on the inherent challenges of building LLMs.
Many people often say that GPTs are only about stacking more and more layers in the model and making the network bigger.
If it was that easy, everybody would have been doing it.
From today’s discussion, you may have understood that it’s not as simple as appending more layers.
Even one additional layer can lead to multiple GBs of additional memory requirement.
Multi-GPU training is at the forefront of these models, which we covered here: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, here’s an article that teaches CUDA programming from scratch: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming
👉 Over to you: What are some other challenges in building large deep learning models?
1 Referral: Unlock 450+ practice questions on NumPy, Pandas, and SQL.
2 Referrals: Get access to advanced Python OOP deep dive.
3 Referrals: Get access to the PySpark deep dive for big-data mastery.
Get your unique referral link:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
About #(activations) in 1 gpt-2 transformer block, why is it 12?
It seems
1. Text & Position embed have no activations;
2. Masked Multi Self Attention layer has 1 softmax only; (does mask and dropout count as activations also?)
3. Feed Forward layer has only 1 GELU;
Could you help to figure out where exactly are the 12 activations?