
What Feature Scaling and Standardization is NOT Used For?
Understanding scaling and standardization from the perspective of skewness.

Feature scaling and standardization are two common ways to alter a feature’s range. For instance:
MinMaxScaler changes the range of a feature to [0,1]:
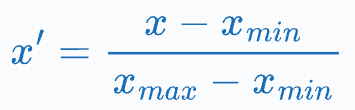
Standardization makes a feature’s mean zero and standard deviation one:

As you may already know, these operations are necessary because:
They prevent a specific feature from strongly influencing the model’s output.
They ensure that the model is more robust to wide variations in the data.
For instance, in the image below, the scale of “income” could massively impact the overall prediction.
Scaling (or standardizing) the data to a similar range can mitigate this and improve the model’s performance.
In fact, the following image precisely verifies this:
As depicted above, feature scaling is necessary for the better performance of many ML models.
So while the importance of feature scaling and standardization is pretty clear and well-known, I have seen many people misinterpreting them as techniques to eliminate skewness.
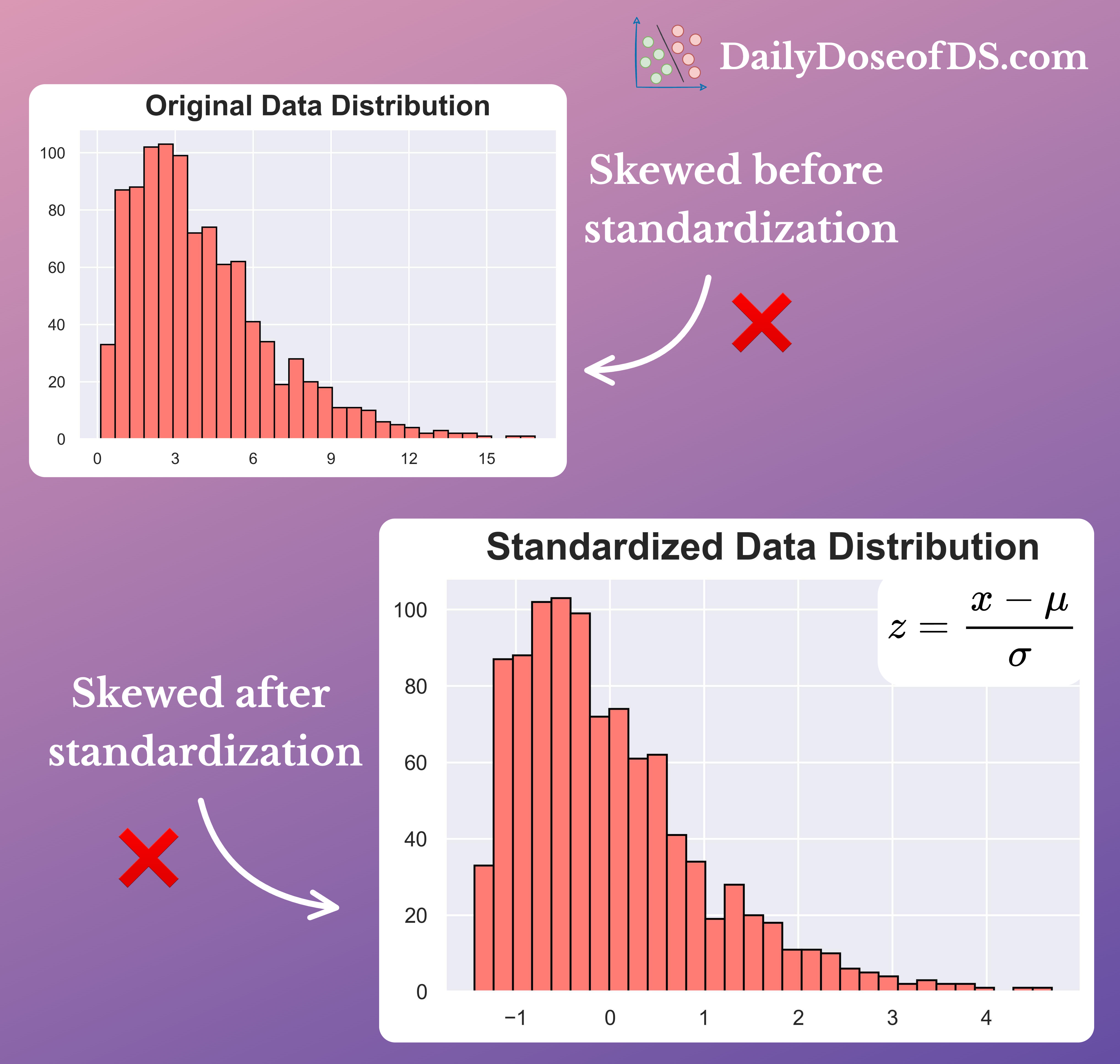
But contrary to this common belief, feature scaling and standardization NEVER change the underlying distribution.
Instead, they just alter the range of values.
Thus, after scaling (or standardization):
Normal distribution → stays Normal
Uniform distribution → stays Uniform
Skewed distribution → stays Skewed
and so on…
We can also verify this from the two illustrations below:
Here’s another image that verifies this:
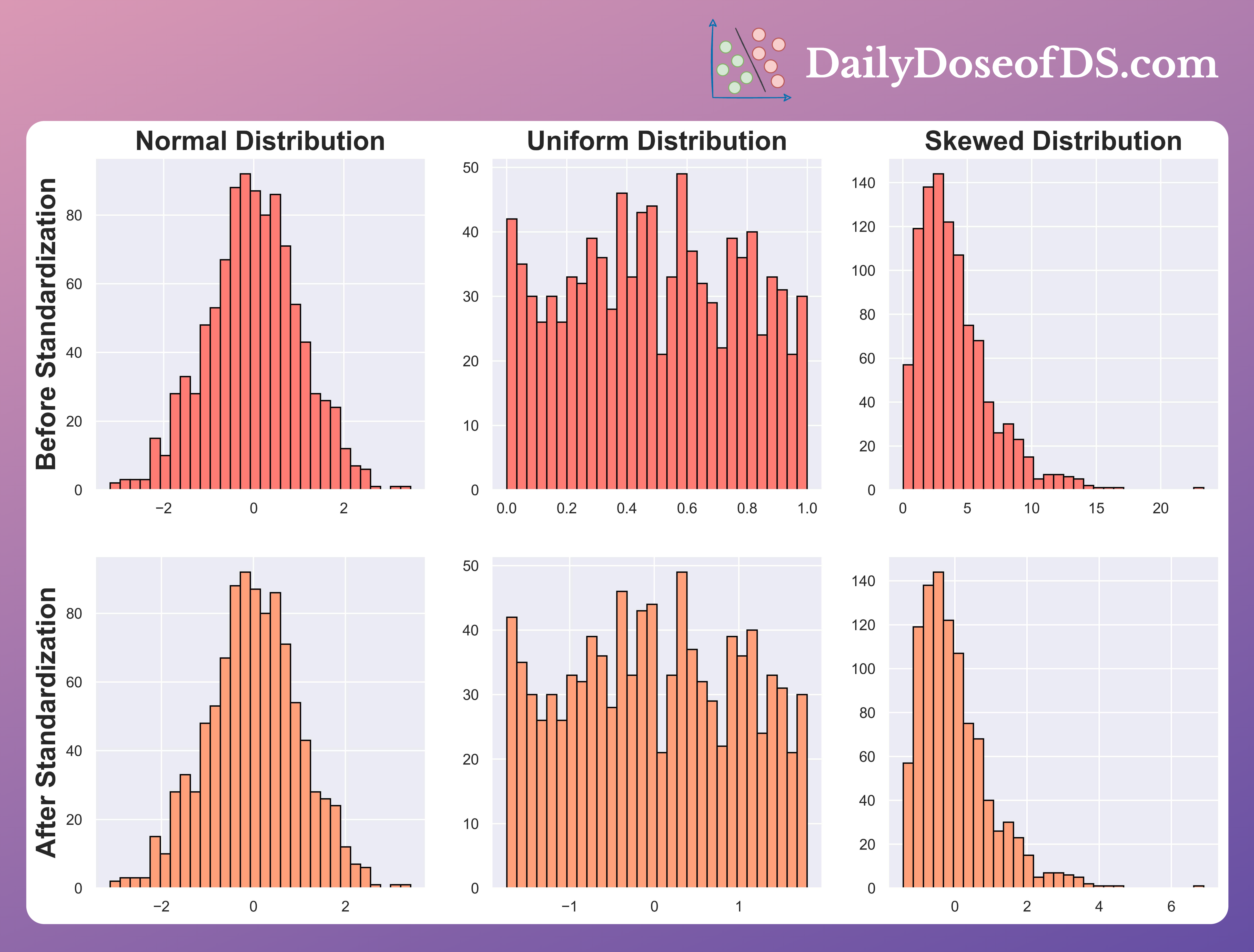
It is clear that scaling and standardization have no effect on the underlying distribution.
Thus, always remember that if you intend to eliminate skewness, scaling/standardization will never help.
Try feature transformations instead.
There are many of them, but the most commonly used transformations are:
Log transform
Sqrt transform
Box-cox transform
Their effectiveness is evident from the image below:
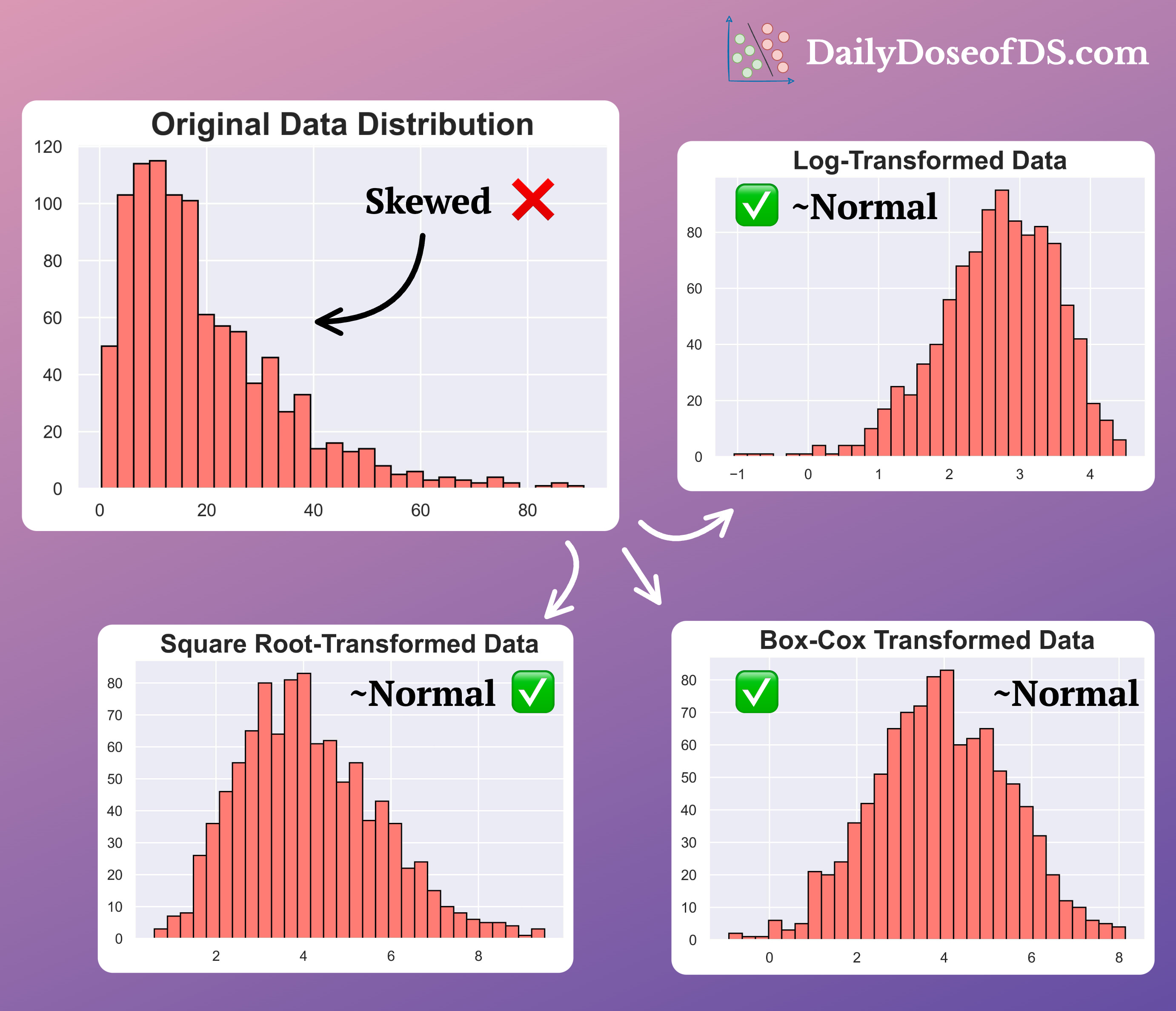
As depicted above, applying these operations transforms the skewed data into a (somewhat) normally distributed variable.
Before I conclude, please note that while log transform is commonly used to eliminate data skewness, it is not always the ideal solution.
I recently wrote about it on X (read here or click the post below):

And if you are wondering why did we convert the above-skewed data to a normal distribution, and what its purpose was, then check out this issue:

👉 Over to you: What are some other ways to eliminate skewness?
For those who want to build a career in DS/ML on core expertise, not trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.
For instance:
15 Ways to Optimize Neural Network Training (With Implementation)
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.