
Why Sklearn's Linear Regression Has No Hyperparameters?
What are we missing here?

Almost all ML models we work with have some hyperparameters, such as:
Learning rate
Regularization
Layer size (for neural network), etc.
But as shown in the image below, why don’t we see any hyperparameter in Sklearn’s Linear Regression implementation?

It must have learning rate as a hyperparameter, right?
To understand the reason why it has no hyperparameters, we first need to learn that the Linear Regression can model data in two different ways:
Gradient Descent (which many other ML algorithms use for optimization):
It is a stochastic algorithm, i.e., involves some randomness.
It finds an approximate solution using optimization.
It has hyperparameters.
Ordinary Least Square (OLS):
It is a deterministic algorithm. Thus, if run multiple times, it will always converge to the same weights.
It always finds the optimal solution.
It has no hyperparameters.
Now, instead of the typical gradient descent approach, Sklearn’s Linear Regression class implements the OLS method.
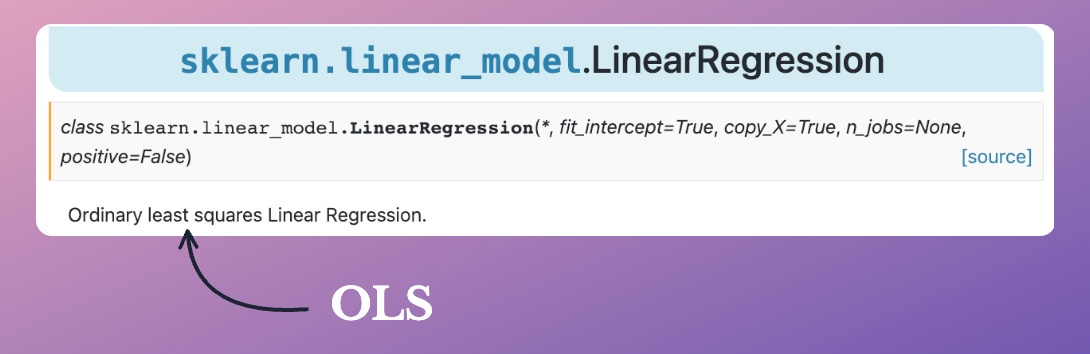
That is why it has no hyperparameters.
How does OLS work?
With OLS, the idea is to find the set of parameters (Θ) such that:
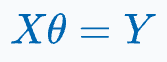
where,
X: input data with dimensions(n,m).Θ: parameters with dimensions(m,1).y: output data with dimensions(n,1).n: number of samples.m: number of features.
One way to determine the parameter matrix Θ is by multiplying both sides of the equation with the inverse of X, as shown below:

But because X might be a non-square matrix, its inverse may not be defined.
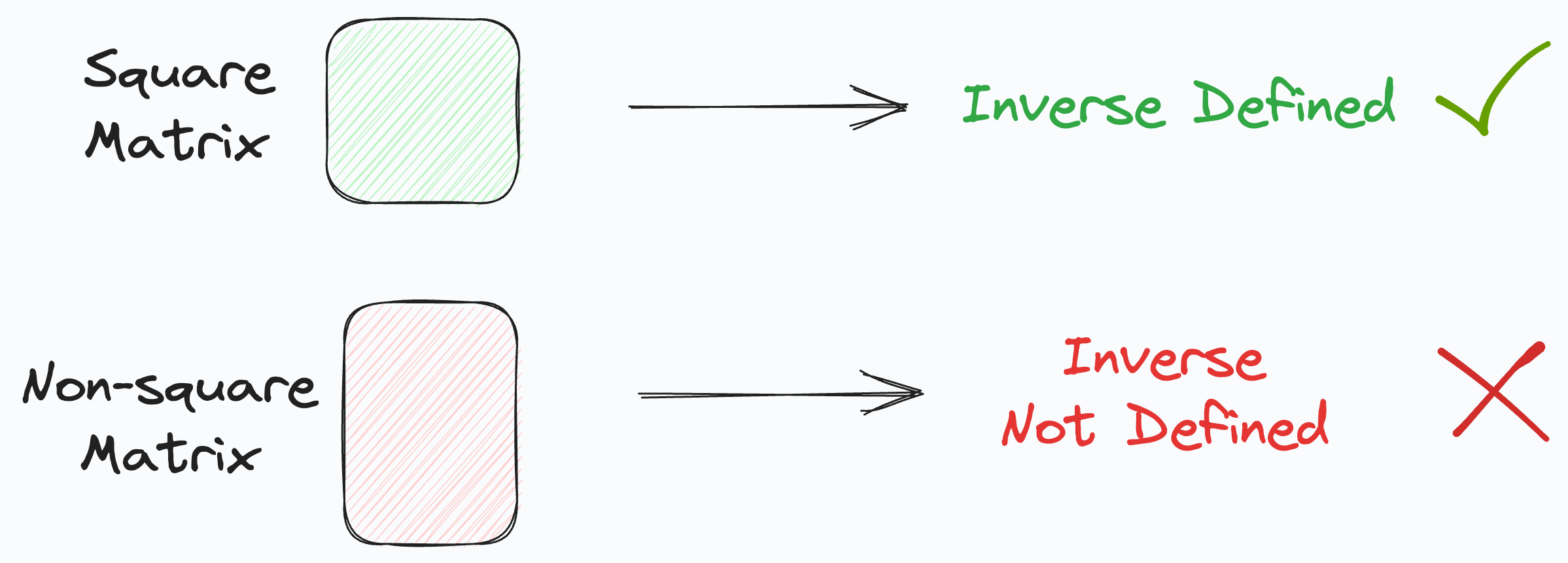
To resolve this, first, we multiply with the transpose of X on both sides, as shown below:
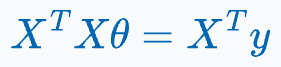
This makes the product of X with its transpose a square matrix.

The obtained matrix, being square, can be inverted (provided it is non-singular).
Next, we take the collective inverse of the product to get the following:

It’s clear that the above equation has:
No hyperparameters.
No randomness. Thus, it will always return the same solution, which is also optimal.
This is precisely what the Linear Regression class of Sklearn implements.
To summarize, it uses the OLS method instead of gradient descent.
That is why it has no hyperparameters.
Of course, do note that there is a significant tradeoff between run time and convenience when using OLS vs. gradient descent.
This is also clear from the algorithm time-complexity table I once shared in this newsletter:

As depicted above, the run-time of OLS is cubically related to the number of features (m).
Thus, when we have many features, it may not be a good idea to use the LinearRegression() class. Instead, use the SGDRegressor() class from Sklearn.
Of course, the good thing about LinearRegression() class is that it involves no hyperparameter tuning.
Thus, when we use OLS, we trade run-time for finding an optimal solution without hyperparameter tuning.
While this was about linear regression, do you know that Sklearn’s logistic regression has no learning rate hyperparameter?
To begin, the most common way of learning the weights (θ) of a logistic regression model, as taught in most lectures/blogs/tutorials, is using gradient descent:

As depicted above, we specify a learning rate (α) before training the model and run it for a specified number of iterations (epochs).
However, if that is how we train logistic regression, then why don’t we see a learning rate hyperparameter (α) in its sklearn implementation:

Interesting, isn’t it?
Moreover, the parameter list has the ‘max_iter’ parameter that intuitively looks analogous to the epochs.

But how does that make sense?
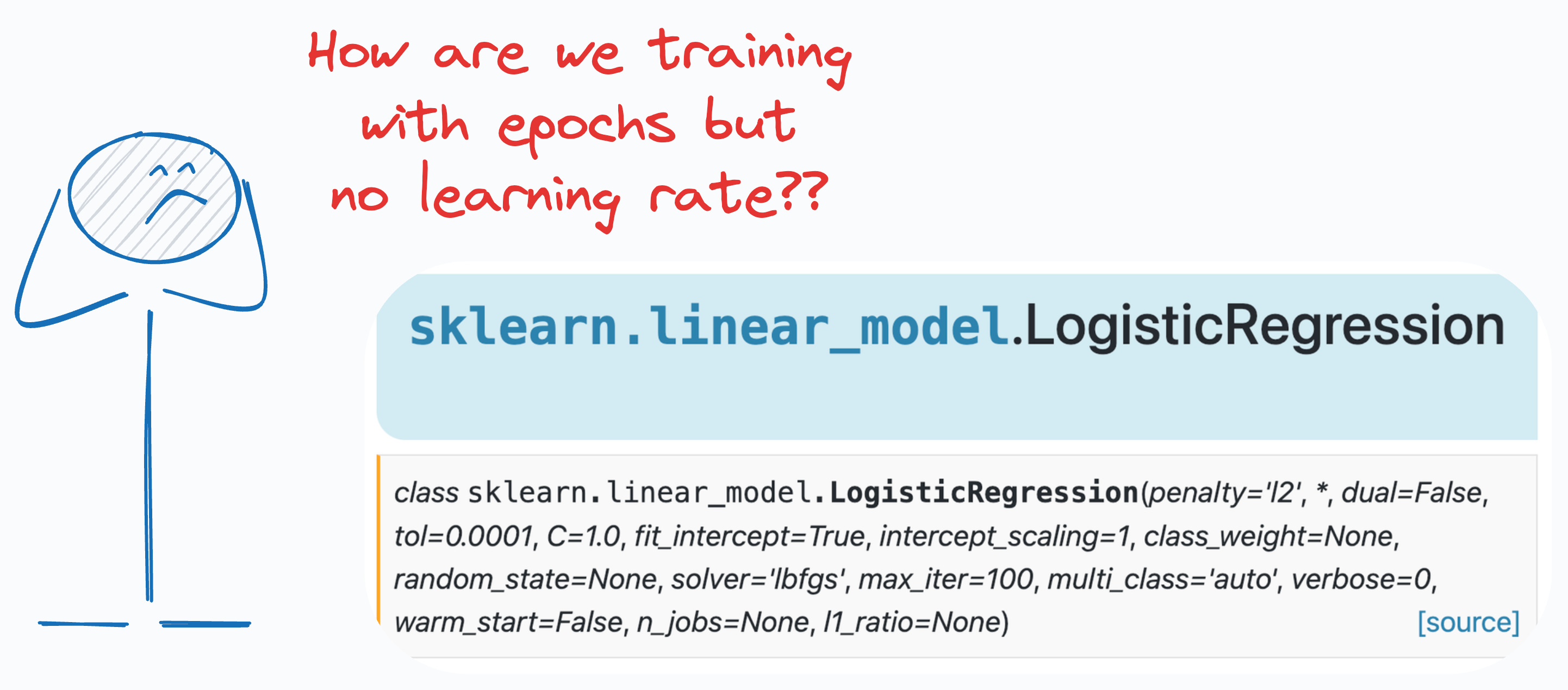
We have epochs but no learning rate (α), so how do we even update the model parameters using SGD?
If you are curious, we discussed the alternative methods to fit logistic regression in detail here: Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
👉 Over to you: How would you prove that the solution returned by OLS is optimal? Would love to read your answers :)
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 78,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Great insights! What's nice about sklearn is that it can be played around like a toy, it's very simple to use, but under the hood, if you care to learn more, you have all the powerful stuff.