
10 Regression and Classification Loss Functions
...summarized in a single frame.

The visual below depicts the most commonly used loss functions for regression and classification tasks.
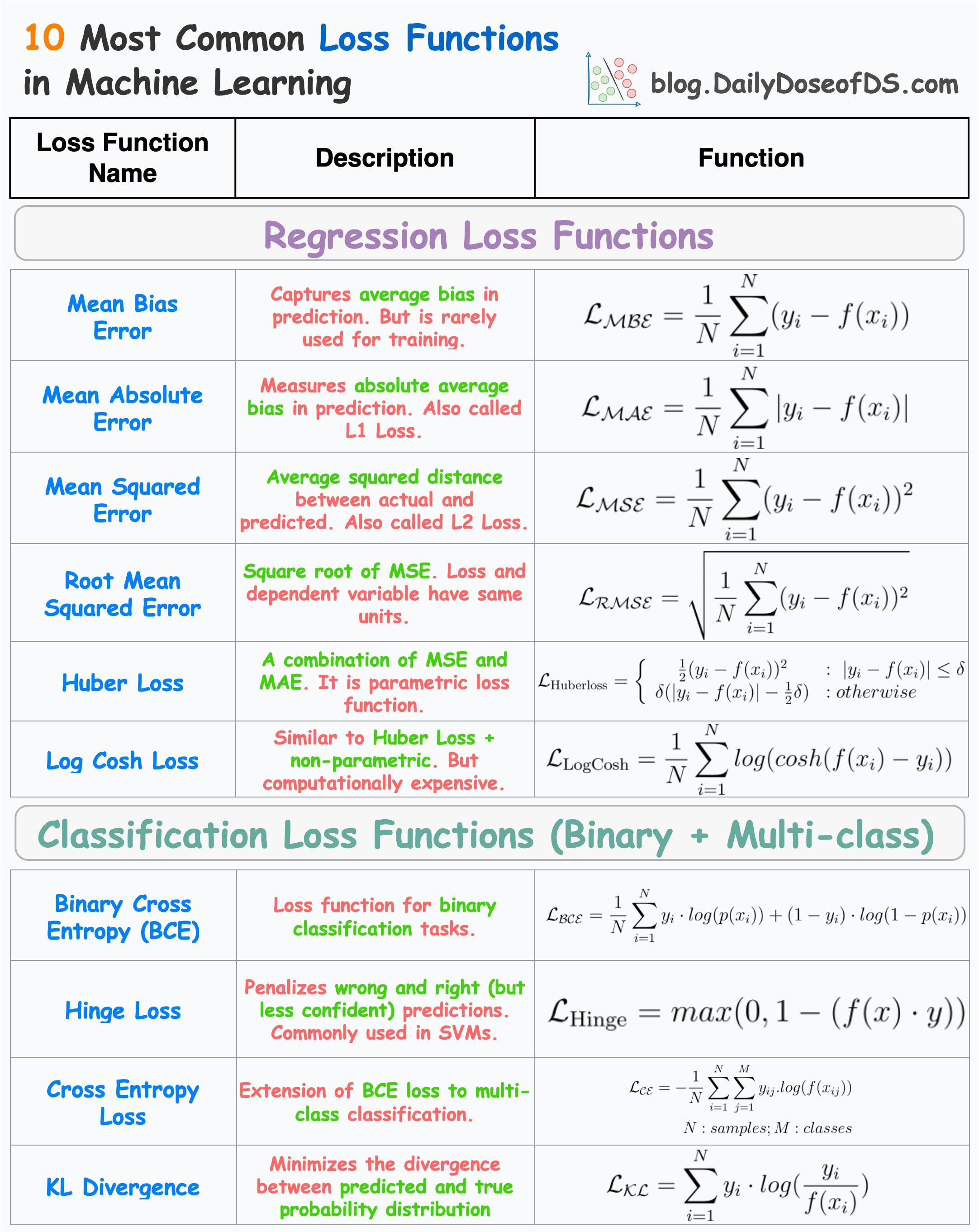
1) Regression
1.1) Mean Bias Error

Captures the average bias in the prediction.
However, it is rarely used in training ML models.
This is because negative errors may cancel positive errors, leading to zero loss, and consequently, no weight updates.
Mean bias error is foundational to the more advanced regression losses discussed below.
1.2) Mean Absolute Error (or L1 loss)

Measures the average absolute difference between predicted and actual value.
Positive errors and negative errors don’t cancel out.
One caveat is that small errors are as important as big ones. Thus, the magnitude of the gradient is independent of error size.
1.3) Mean Squared Error (or L2 loss)

It measures the squared difference between predicted and actual value.
Larger errors contribute more significantly than smaller errors.
The above point may also be a caveat as it is sensitive to outliers.
Yet, it is among the most common loss functions for many regression models. If you want to understand the origin of mean squared error, we discussed it in this newsletter issue: Why Mean Squared Error (MSE)?
1.4) Root Mean Squared Error

Mean Squared Error with a square root.
Loss and the dependent variable (y) have the same units.
1.5) Huber Loss

It is a combination of mean absolute error and mean squared error.
For smaller errors, mean squared error is used, which is differentiable through (unlike MAE, which is non-differentiable at
x=0).For large errors, mean absolute error is used, which is less sensitive to outliers.
One caveat is that it is parameterized — adding another hyperparameter to the list.
Read this full issue to learn more about Huber Regression: A Simple Technique to Robustify Linear Regression to Outliers.
1.6) Log Cosh Loss

For small errors, log cash loss is approximately →
x²/2— quadratic.For large errors, log cash loss is approximately →
|x| - log(2)— linear.Thus, it is very similar to Huber loss.
Also, it is non-parametric.
The only caveat is that it is a bit computationally expensive.
2) Classification
2.1) Binary cross entropy (BCE) or Log loss
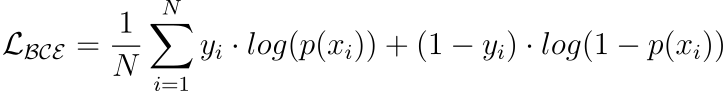
A loss function used for binary classification tasks.
Measures the dissimilarity between predicted probabilities and true binary labels, through the logarithmic loss.
Where did the log loss originate from? We discussed it here: Why Do We Use log-loss To Train Logistic Regression?
2.2) Hinge Loss

Penalizes both wrong and right (but less confident) predictions).
It is based on the concept of margin, which represents the distance between a data point and the decision boundary.
The larger the margin, the more confident the classifier is about its prediction.
Particularly used to train support vector machines (SVMs).
2.3) Cross-Entropy Loss
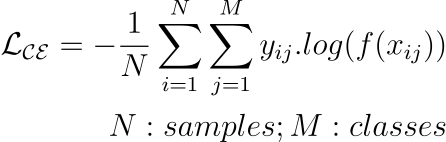
An extension of Binary Cross Entropy loss to multi-class classification tasks.
2.4) KL Divergence

Measure information lost when one distribution is approximated using another distribution.
The more information is lost, the more the KL Divergence.
For classification, however, using KL divergence is the same as minimizing cross entropy (proved below):

Thus, it is recommended to use cross-entropy loss directly. That said, KL divergence is widely used in many other algorithms:
As a loss function in the t-SNE algorithm. We discussed it here: t-SNE article.
For model compression using knowledge distillation. We discussed it here: Model compression article.
👉 Over to you: What other common loss functions have I missed?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.