
15 Ways to Optimize Neural Network Training
A single frame summary.

Here are 15 ways I could recall in 2 minutes to optimize neural network training:

Some of them, as you can tell, are pretty basic and obvious, like:
Use efficient optimizers—AdamW, Adam, etc.
Utilize hardware accelerators (GPUs/TPUs).
Max out the batch size.
Here are other methods with more context:
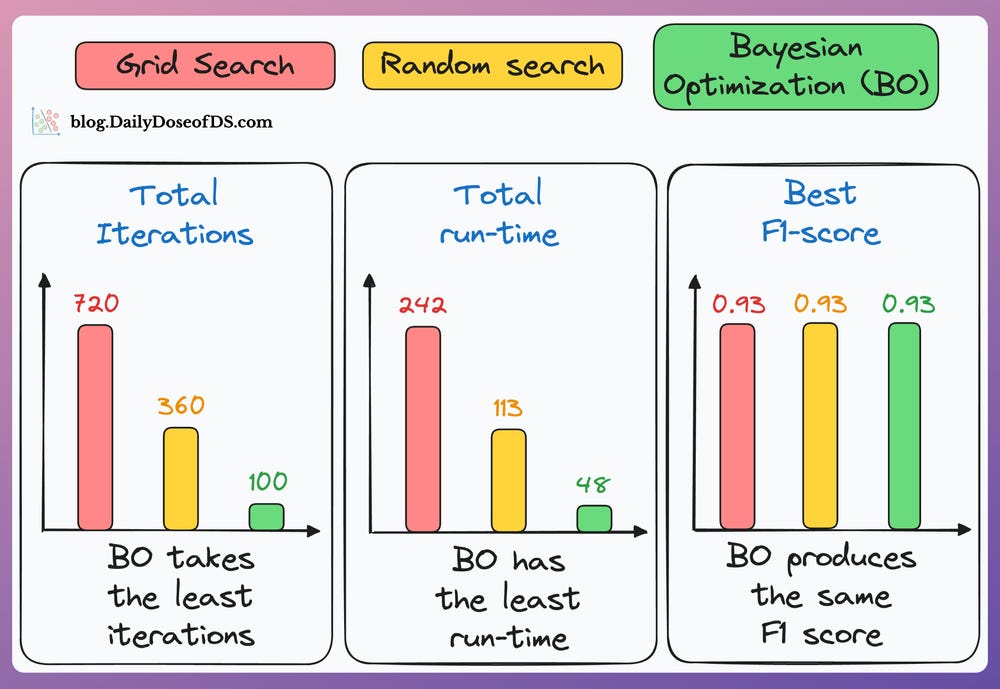
Use Bayesian Optimization if the hyperparameter search space is big:
The idea is to take informed steps based on the results of the previous hyperparameter configurations.
This lets it confidently discard non-optimal configurations. Consequently, the model converges to an optimal set of hyperparameters much faster.
We covered Bayesian optimization from scratch and implementation here.
As shown in the results below, Bayesian optimization (green bar) takes the least number of iterations, consumes the lowest time, and still finds the configuration with the best F1 score:
Use mixed precision training:
The idea is to employ lower precision
float16(wherever feasible, like in convolutions and matrix multiplications) along withfloat32— that is why the name “mixed precision training.”We covered it here: Mixed precision training.
This is a list of some models I found that were trained using mixed precision:


Use He or Xavier initialization for faster convergence (usually helps).
Utilize multi-GPU training through Model/Data/Pipeline/Tensor parallelism. For large models, use DeepSpeed, FSDP, YaFSDP, etc.
We covered multi-GPU training here: A Beginner-friendly Guide to Multi-GPU Model Training.
We covered techniques like DeepSpeed here: A Practical Guide to Scaling ML Model Training.
Always use
DistributedDataParallel, notDataParallel.We covered the internals of DistributedDataParallel and DataParallel here: A Beginner-friendly Guide to Multi-GPU Model Training.
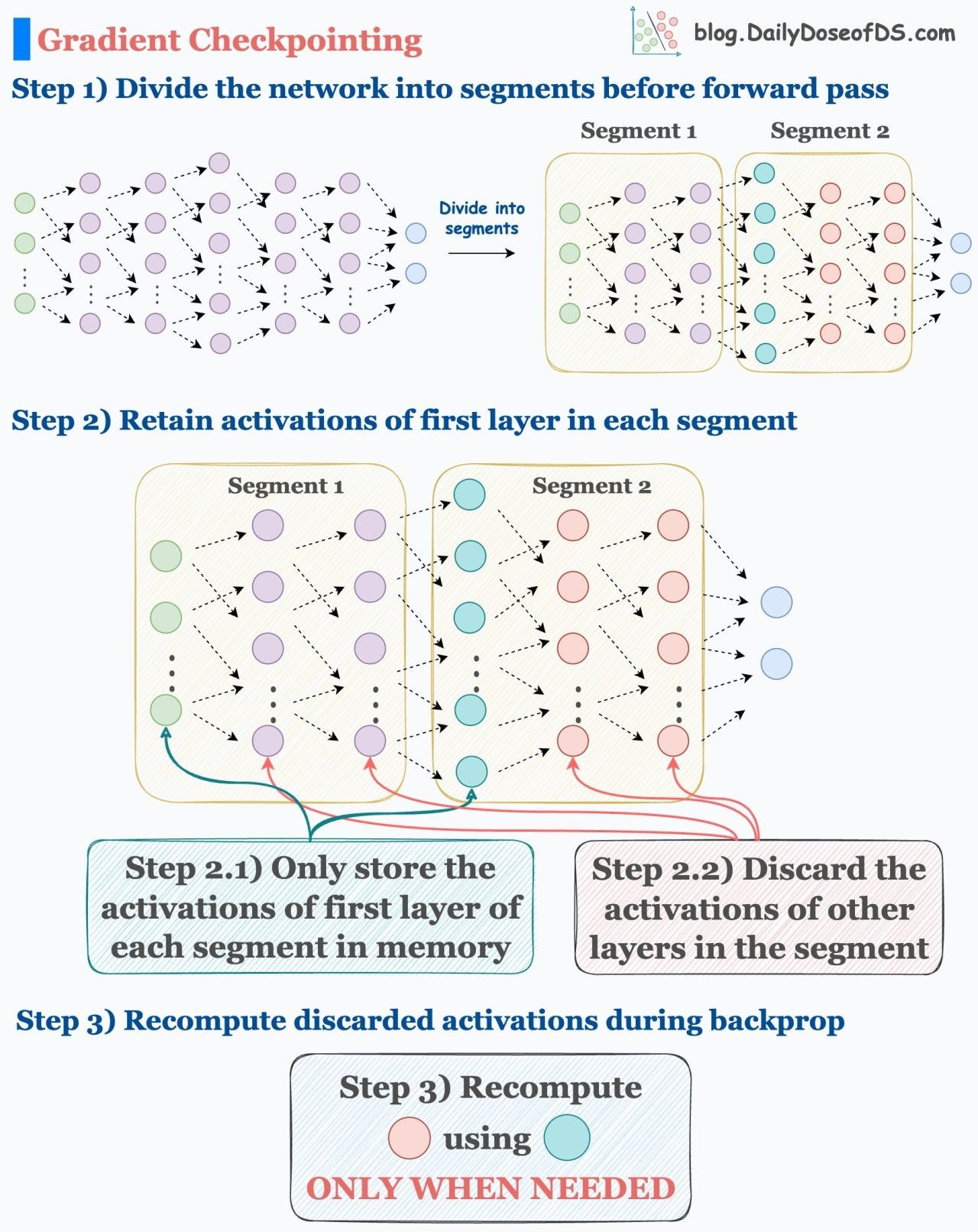
Use activation checkpointing to optimize memory (run-time will go up).

The idea is that we don’t need to store all the intermediate activations in memory.
Instead, storing a few of them and recomputing the rest ONLY WHEN THEY ARE NEEDED can significantly reduce the memory requirement.
Typically, gradient checkpointing can reduce memory usage by a factor of
sqrt(M), whereMis the memory consumed without gradient checkpointing.The reduction is massive. But of course, due to recomputations, this does increase run-time (15-25% increases typically).
We covered this here: Gradient checkpointing.
Normalize data after transferring to GPU (for integer data, like pixels):

Consider image data, which has pixels (8-bit integer values).
Normalizing before transferring to the GPU leads to 32-bit floats being transferred.
But normalizing after transfer means 8-bit integers are transferred, which takes lower memory.
Use gradient accumulation (may have marginal improvement at times).
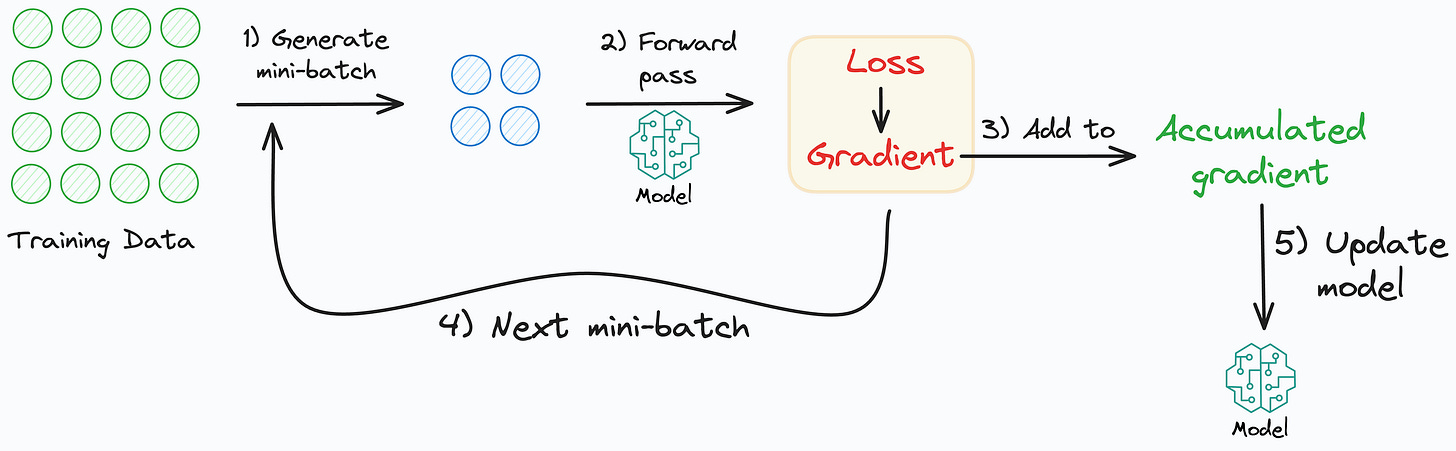
Under memory constraints, it is always recommended to train the neural network with a small batch size.
Despite that, there’s a technique called gradient accumulation, which lets us (logically) increase batch size without explicitly increasing the batch size.
torch.rand(2, 2, device = ...)creates a tensor directly on theGPU. Buttorch.rand(2,2).cuda()first creates on the CPU, then transfers to the GPU, which is slow. The speedup is evident from the image below:


Set
max_workersandpin_memoryin DataLoader.The typical neural network training procedure is as follows:
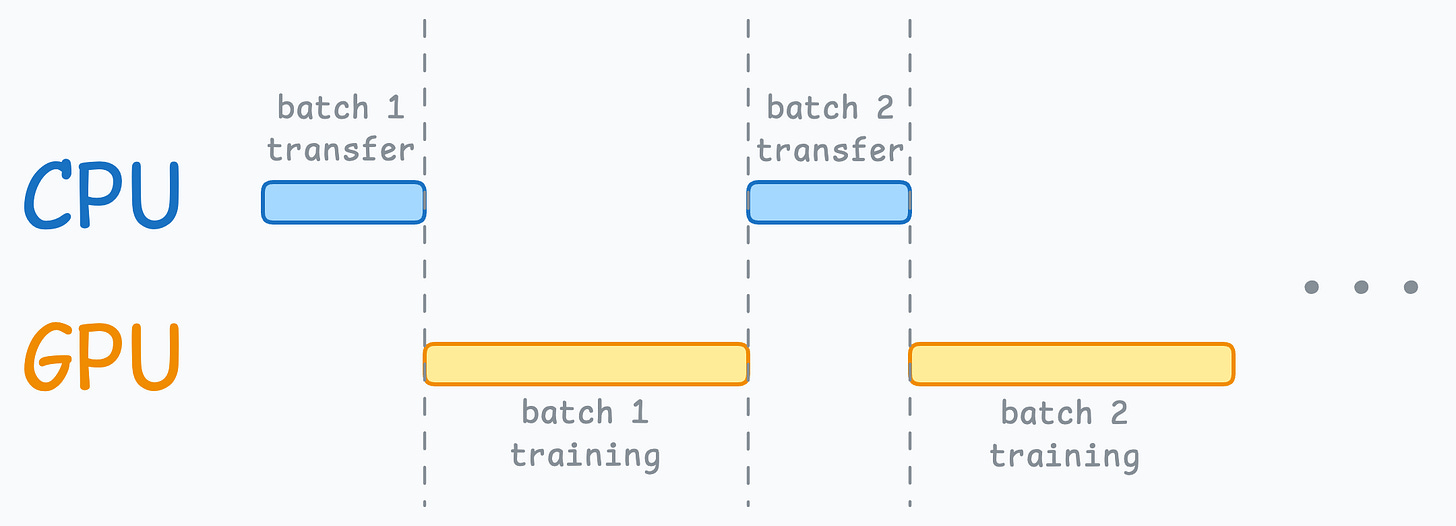
As shown above, when the GPU is working, the CPU is idle, and when the CPU is working, the GPU is idle.
But here’s what we can do to optimize this:

When the model is being trained on the 1st mini-batch, the CPU can transfer the 2nd mini-batch to the GPU.
This ensures that the GPU does not have to wait for the next mini-batch of data as soon as it completes processing an existing mini-batch.
While the CPU may remain idle, this process ensures that the GPU (which is the actual accelerator for our model training) always has data to work with.

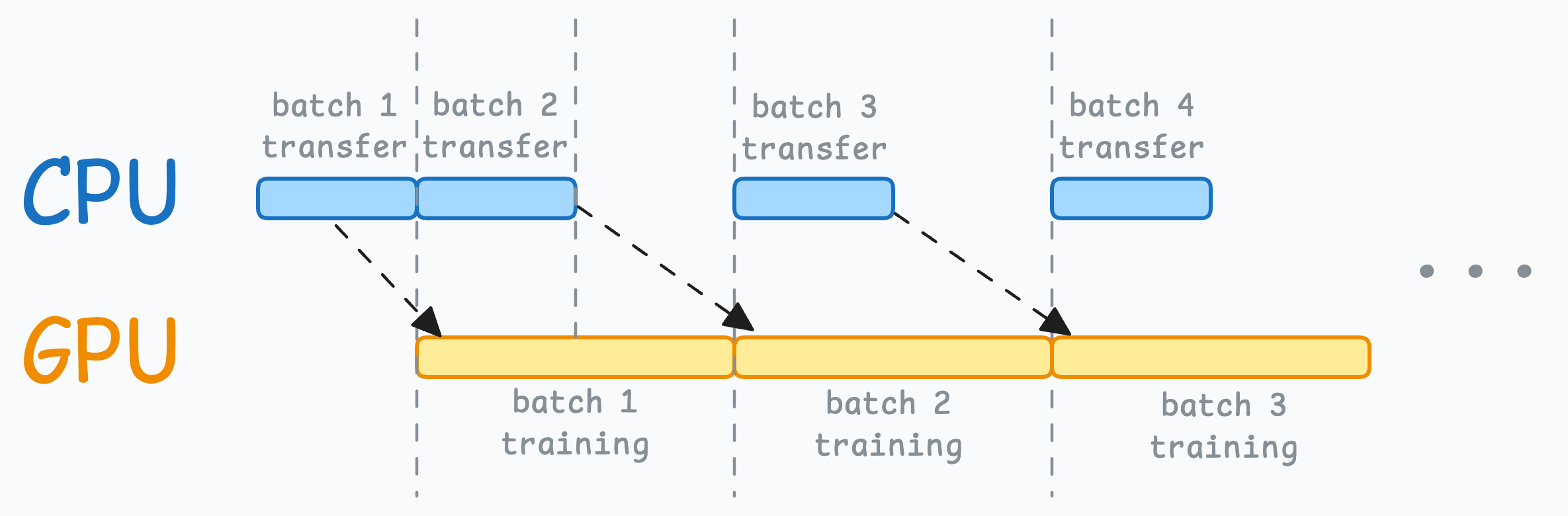
Of course, the above is not an all-encompassing list.
👉 Over to you: Can you add more techniques to optimize neural network training?
Production/Deployment Roadmap
That said, once the model has been trained, we move to productionizing and deploying it.
If ideas related to production and deployment intimidate you, here’s a quick roadmap for you to upskill (assuming you know how to train a model):
First, you would have to compress the model and productionize it. Read these guides:
Model Compression: A Critical Step Towards Efficient Machine Learning.
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
If you use sklearn, here’s a guide that teaches you to optimize models like decision trees with tensor operations: Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Next, you move to deployment. Here’s a beginner-friendly hands-on guide that teaches you how to deploy a model, manage dependencies, set up model registry, etc.: Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
Although you would have tested the model locally, it is still wise to test it in production. There are risk-free (or low-risk) methods to do that. Read this to learn them: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
For those who want to build a career in DS/ML on core expertise, not fleeting trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.