

In today's newsletter:
A mini crash course on AI Agents!
Create eval metrics for LLM Apps in pure English.
Agent communication protocol (ACP).
A mini crash course on AI Agents!
We just released a free mini crash course on building AI Agents, which is a good starting point for anyone to learn about Agents and use them in real-world projects.
Watch the video attached at the top.
Here's what it covers:
What is an AI Agent
Connecting Agents to tools
Overview of MCP
Replacing tools with MCP servers
Setting up observability and tracing
Everything is done with a 100% open-source tool stack:
CrewAI for building MCP-ready Agents.
Zep Graphiti to add memory to Agents.
Opik for observability and tracing.
It builds Agents based on the following definition:
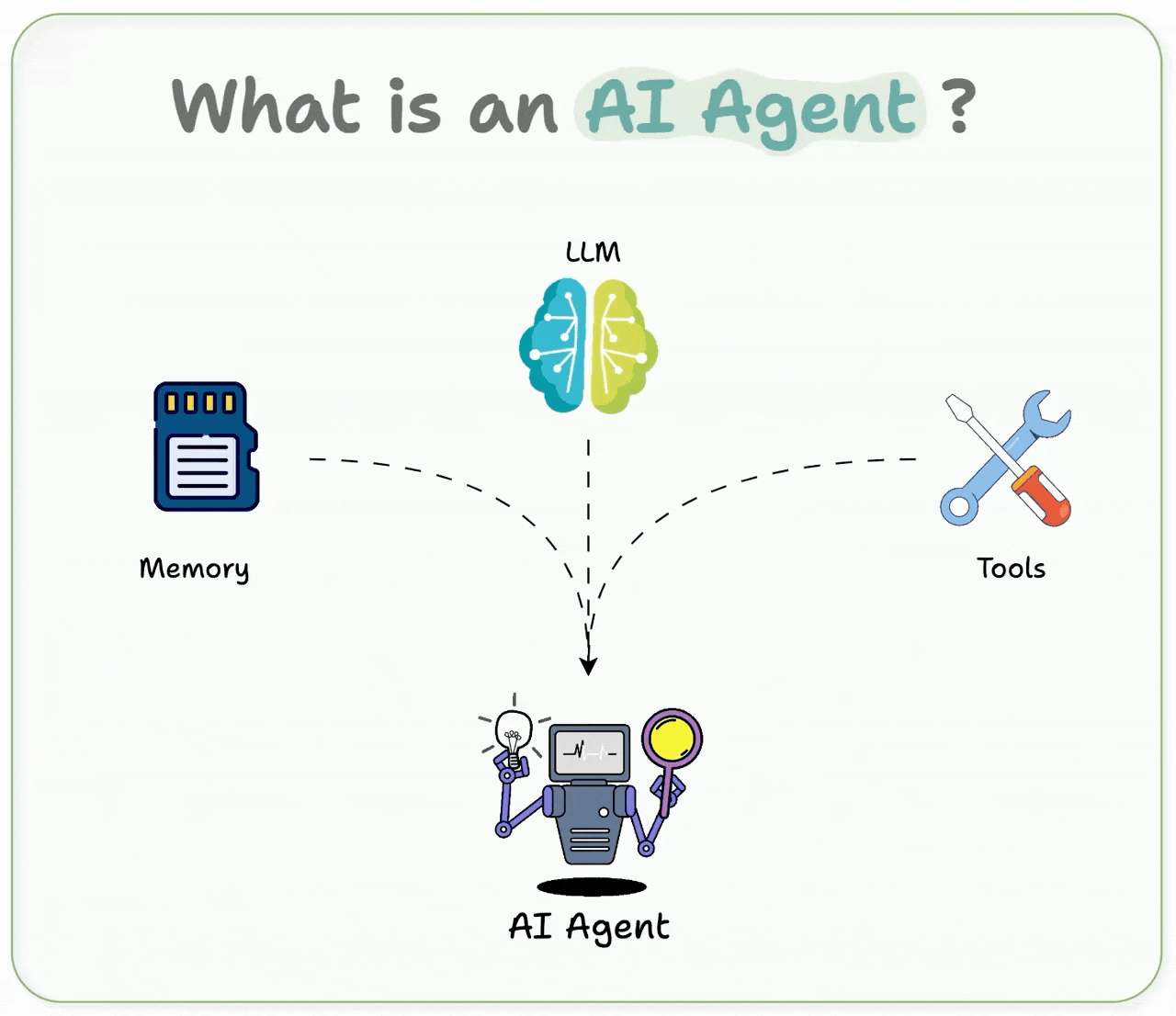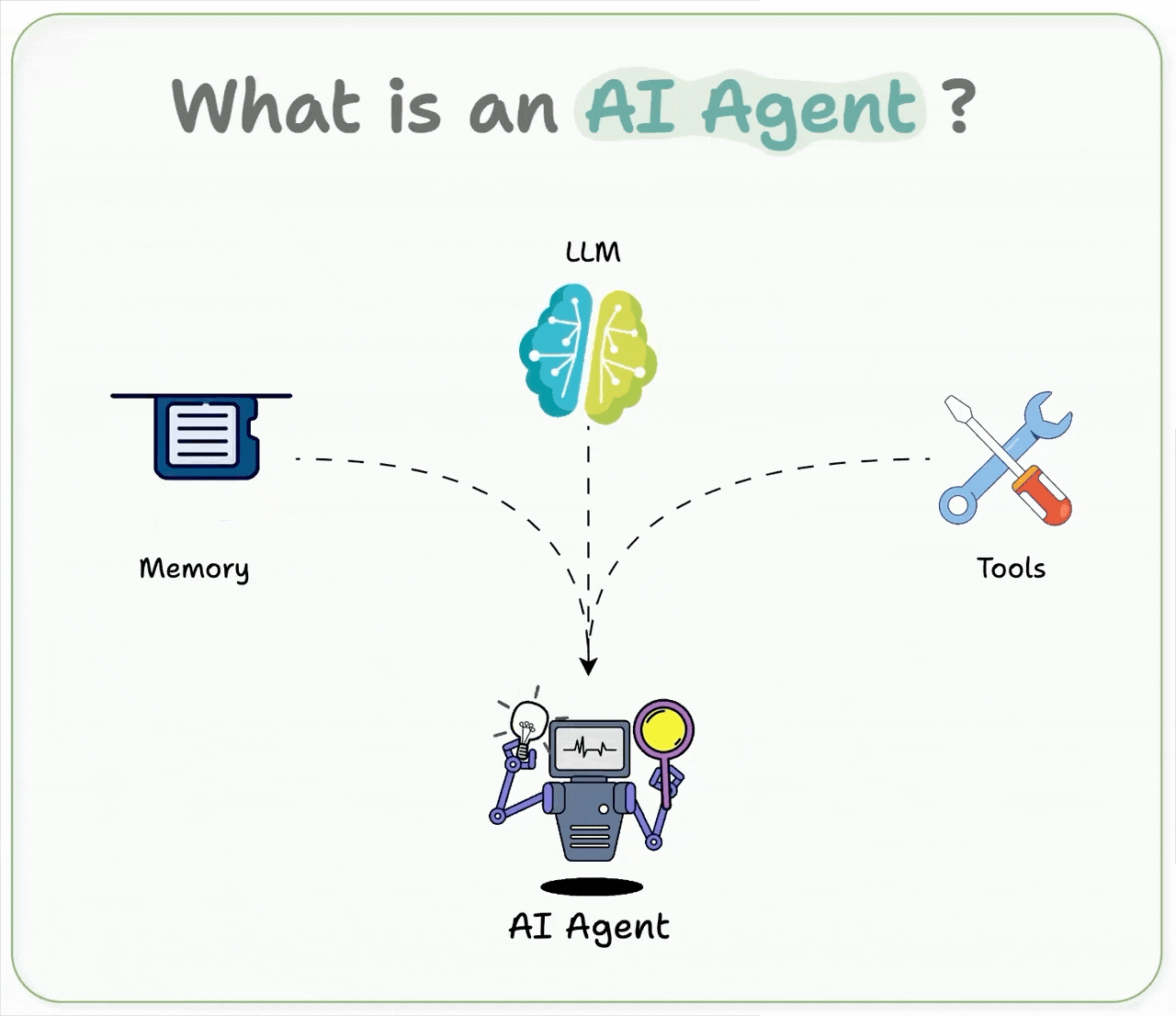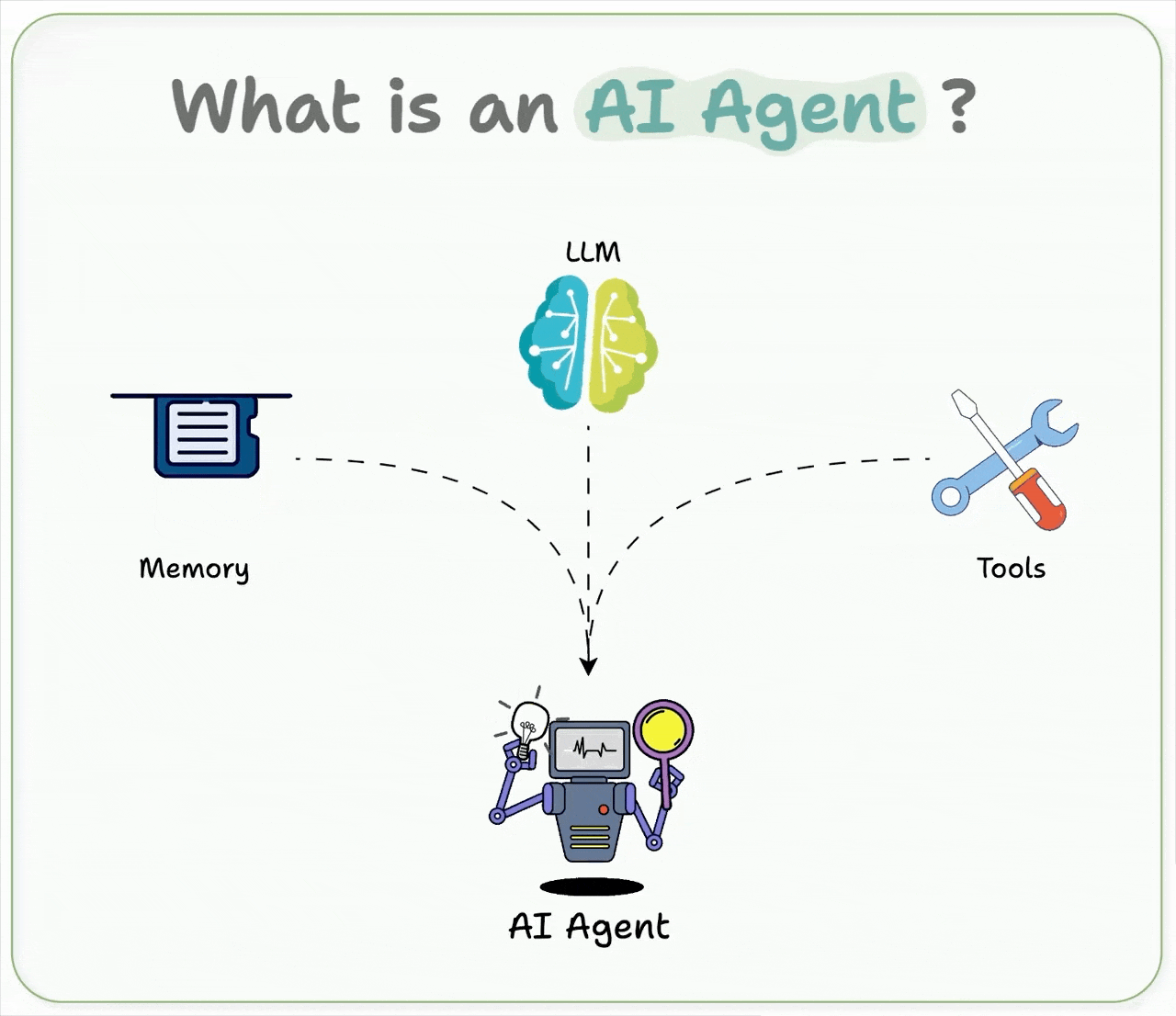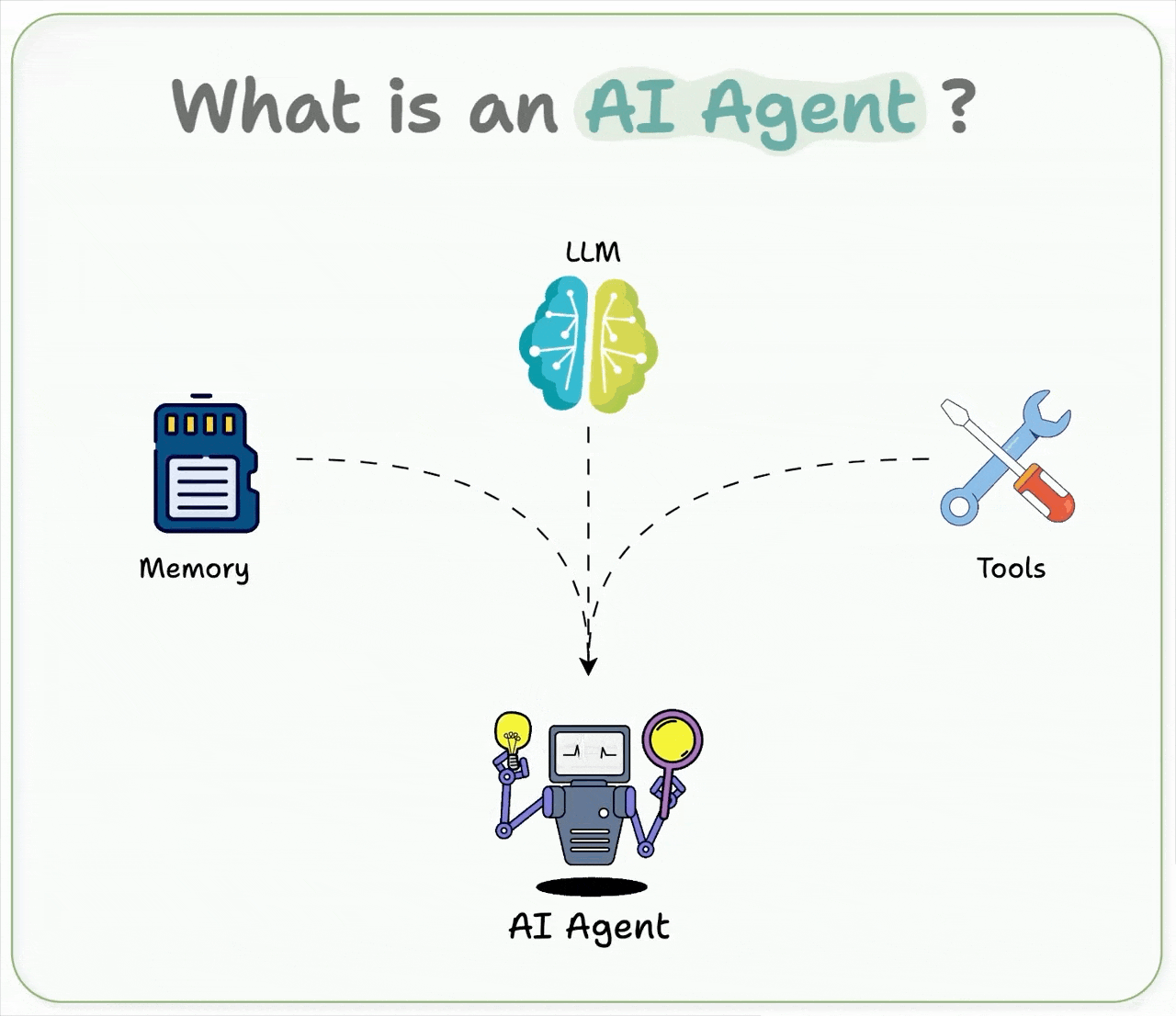
An AI agent uses an LLM as its brain, has memory to retain context, and can take real-world actions through tools, like browsing the web, running code, etc.
In short, it thinks, remembers, and acts.
Here's an overview of the system we're building!

User sends a query
Assistant runs a web search via MCP
Query + results go to Memory Manager
Memory Manager stores context in Graphiti
Response agent crafts the final answer
You can find the entire code in this GitHub repo →
Create eval metrics for LLM Apps in pure English
Standard metrics are usually not that helpful since LLMs can produce varying outputs while conveying the same message.
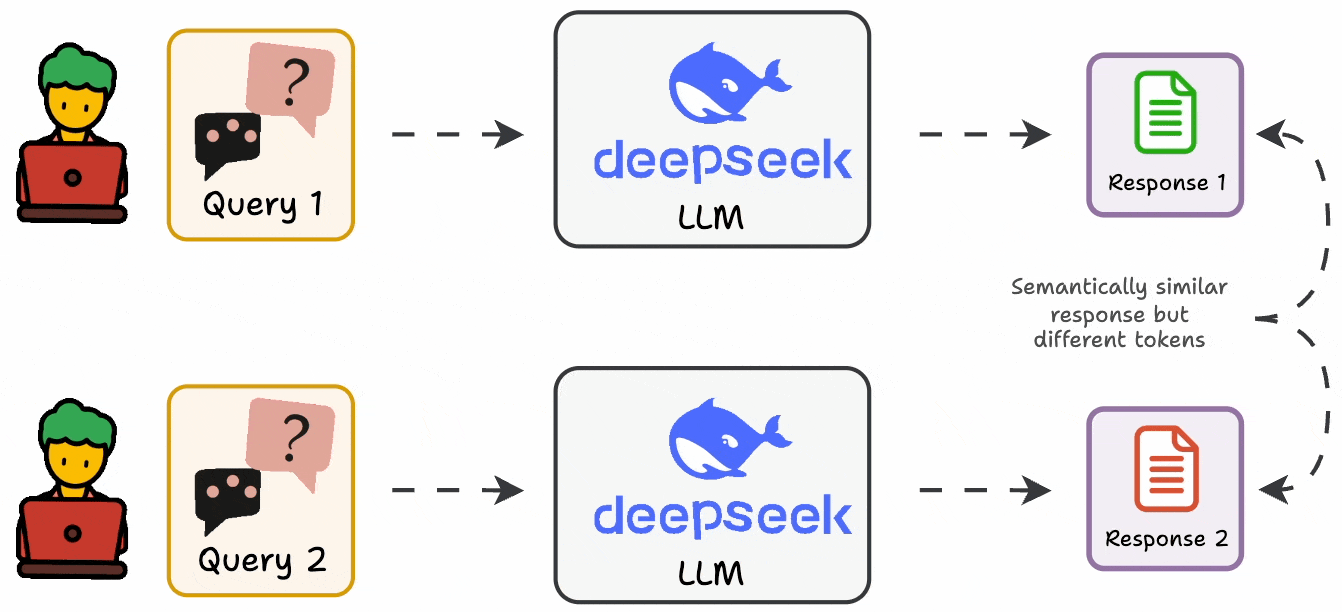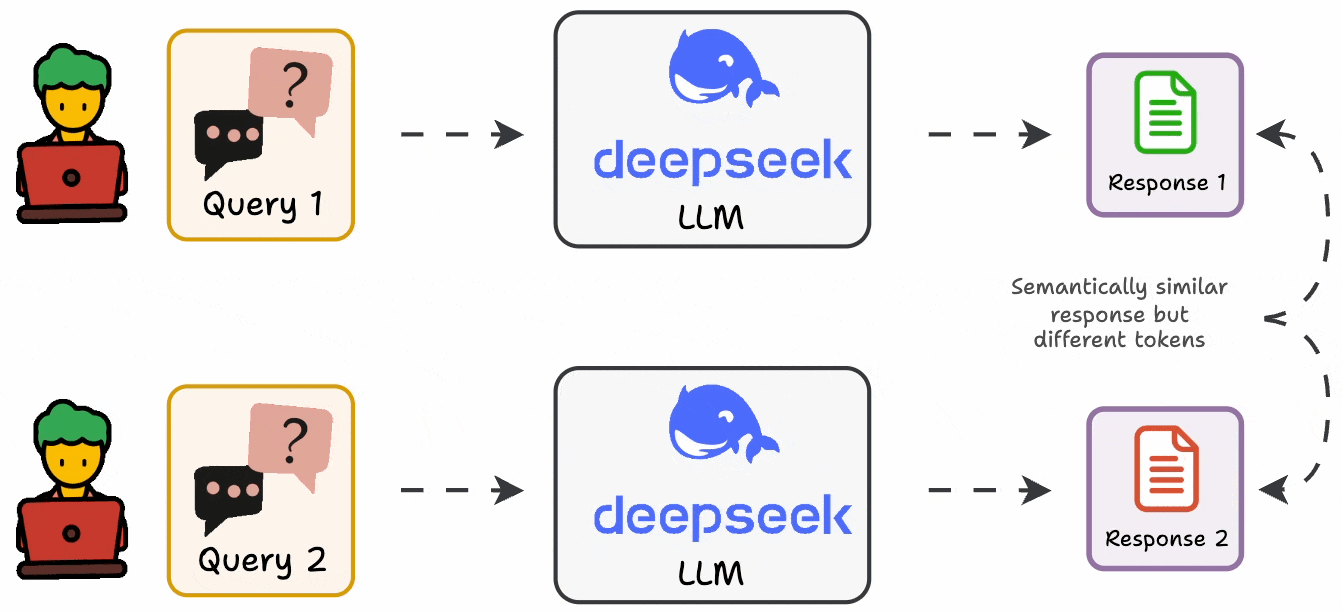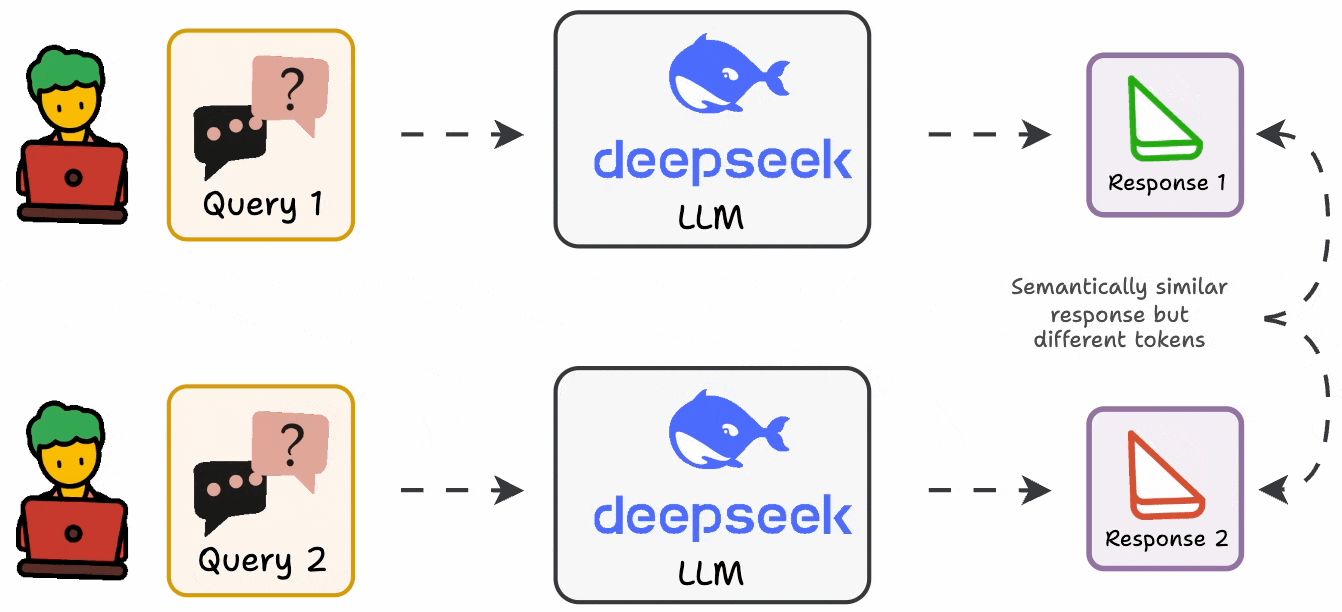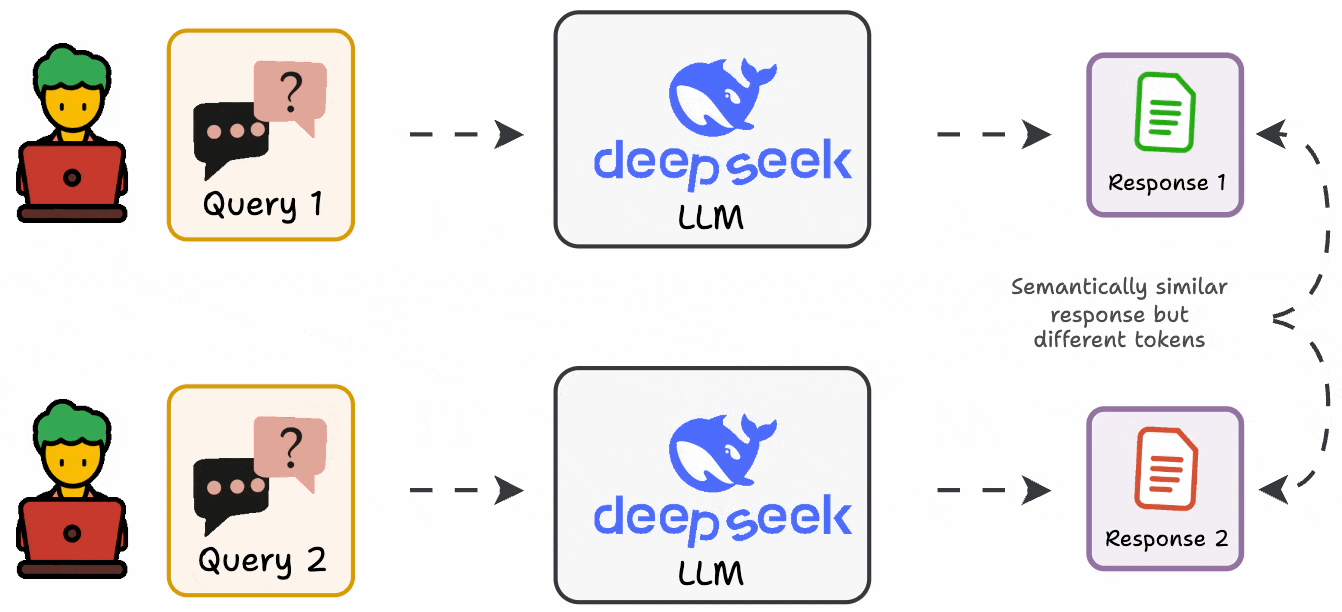
In fact, in many cases, it is also difficult to formalize an evaluation metric as a deterministic code.
G-Eval is a task-agnostic LLM as a Judge metric in Opik that solves this.
The concept of LLM-as-a-judge involves using LLMs to evaluate and score various tasks and applications.
It allows you to specify a set of criteria for your metric (in English), after which it will use a Chain of Thought prompting technique to create evaluation steps and return a score.
Let’s look at a demo below.
First, import the GEval class and define a metric in natural language:

Done!
Next, invoke the score method to generate a score and a reason for that score. Below, we have a related context and output, which leads to a high score:

However, with unrelated context and output, we get a low score as expected:

Under the hood, G-Eval first uses the task introduction and evaluation criteria to outline an evaluation step.
Next, these evaluation steps are combined with the task to return a single score.
That said, you can easily self-host Opik, so your data stays where you want.
It integrates with nearly all popular frameworks, including CrewAI, LlamaIndex, LangChain, and HayStack.
If you want to dive further, we also published a practical guide on Opik to help you integrate evaluation and observability into your LLM apps (with implementation).
It has open access to all readers.
Start here: A Practical Guide to Integrate Evaluation and Observability into LLM Apps.
Agent communication protocol (ACP)

After MCP, A2A, & AG-UI, there's another Agent protocol.
ACP (Agent Communication Protocol) is a standardized, RESTful interface for Agents to discover and coordinate with other Agents, regardless of their framework.
So, essentially, just like A2A, it lets Agents communicate with Agents.
Here's how it works:
Build your Agents and host them on ACP servers.
The ACP server will receive requests from the ACP Client and forward them to the Agent.
ACP Client itself can be an Agent to intelligently route requests to the Agents (just like MCP Client does to tools).
How is ACP different from A2A?
ACP is built for local-first, low-latency communication.
A2A is optimized for web-native, cross-vendor interoperability
ACP uses structured RESTful interfaces.
A2A supports more flexible, natural interactions.
ACP excels in controlled, edge, or team-specific setups.
A2A shines in broader cloud-based collaboration
We shall cover ACP with implementation this week.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
