

In today’s newsletter:
A chat interface to talk to 200+ data sources!
Package AI/ML Projects with KitOps MCP Server
Implement ReAct Agentic pattern from scratch.
A technique to decide if you should gather more data
A chat interface to talk to 200+ data sources!

We have been testing the new chat interface in MindsDB open source, and it’s impressive.
You can ask plain English questions, and it figures out whether to run SQL or semantic search behind the scenes, then merges the results into a single answer.
It’s built on a semantic + parametric query engine. No coding required!
For instance: “What are users saying about Feature X, and how does that correlate with churn?”
To answer this, it’ll hit your DB for churn metrics and your docs for support themes, all in one go. You can also interact with it using its MCP server.
We'll do a demo on this soon, but in the meantime, you can read about it in the MindsDB GitHub repo →
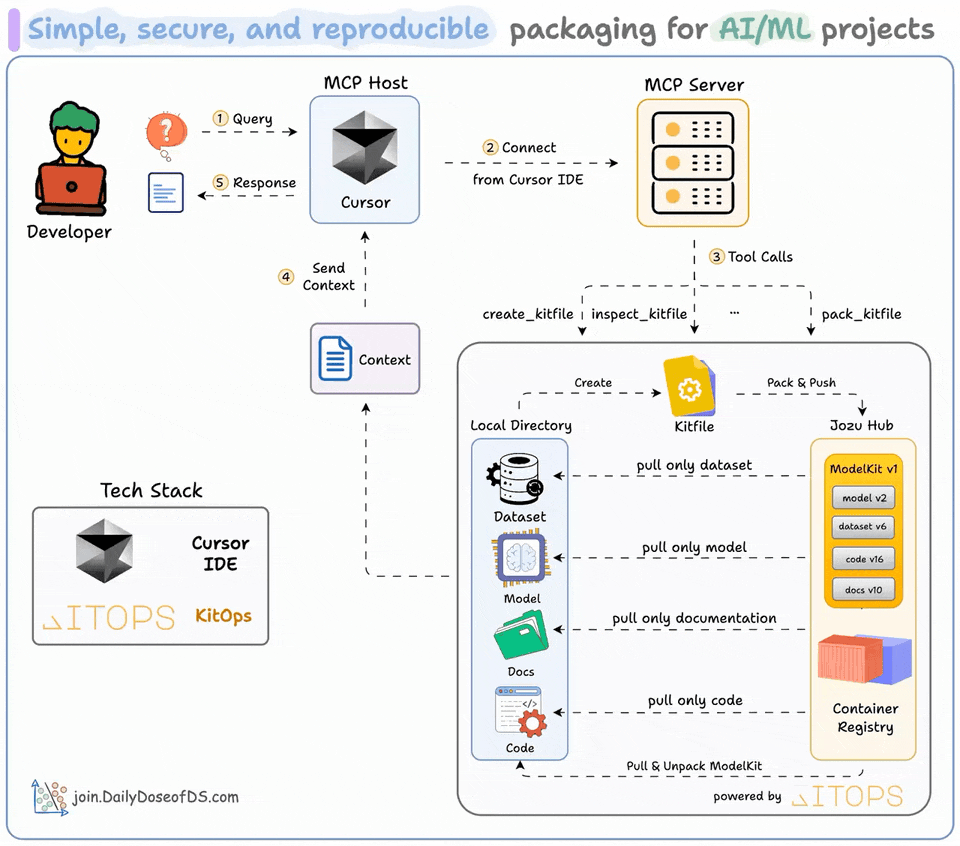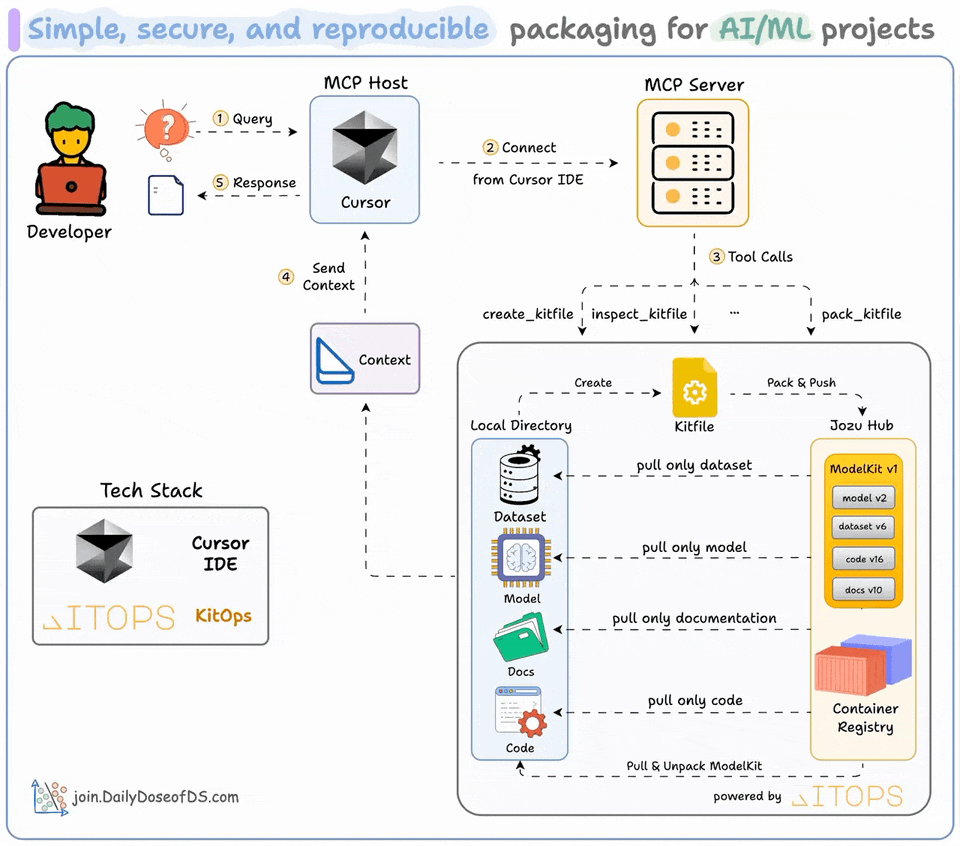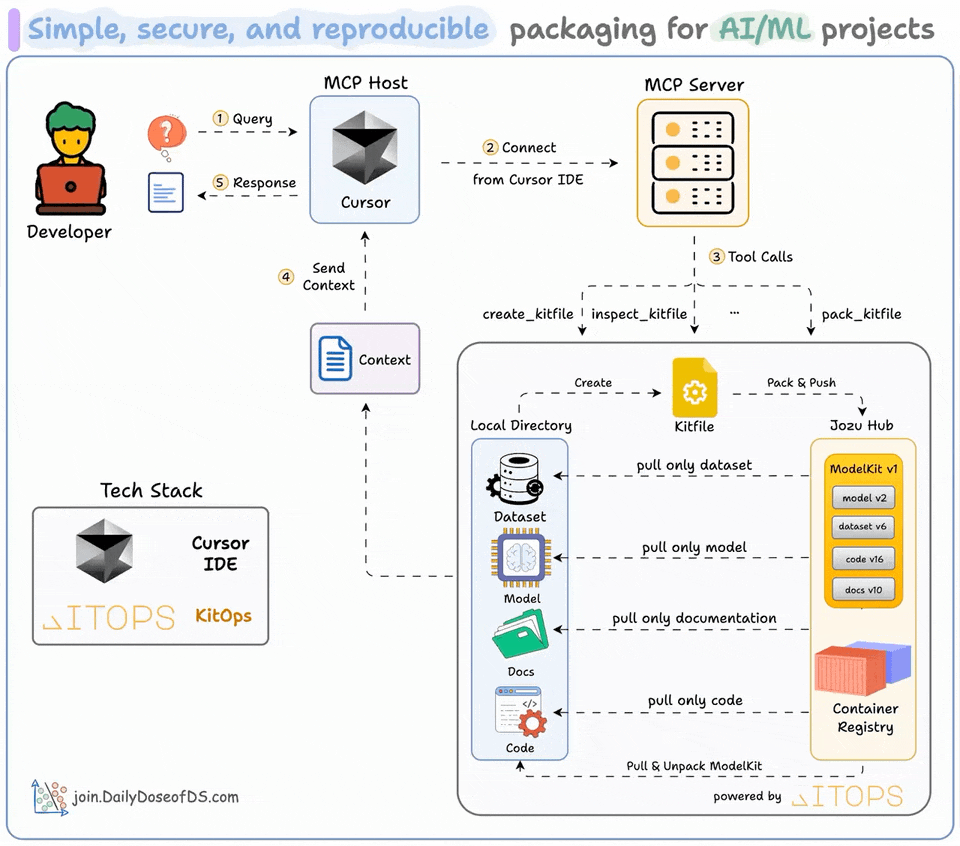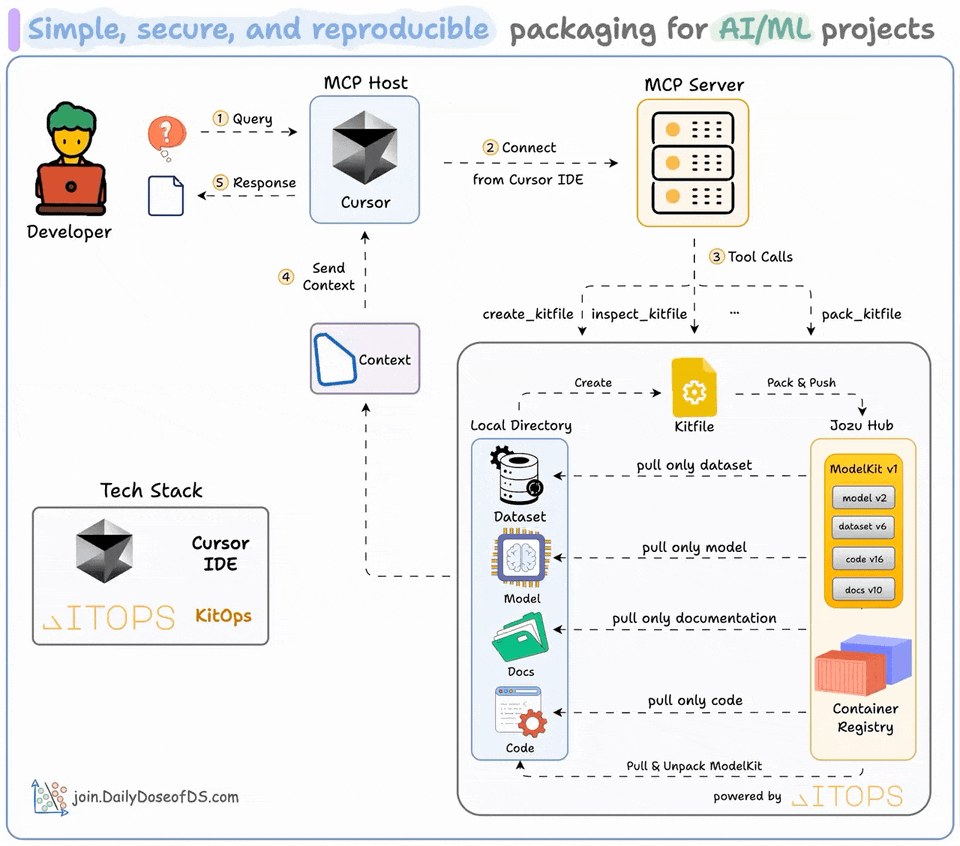
Package AI/ML Projects with KitOps MCP Server
ML projects aren’t just code.
They are code + datasets + model weights + parameters + config, and whatnot!
Docker isn’t well-suited to package them since you cannot selectively pull what you need.
And GitHub enforces size limits.
To solve this, we built an MCP server that all AI/ML Engineers will love.
The video attached at the top gives a detailed walk-through.
We created ModelKits (powered by open-source KitOps) to package an AI/ML project (models, datasets, code, and config) into a single, shareable unit.
Think of it as Docker for AI, but smarter.
While Docker containers package applications, ModelKits are purpose-built for AI/ML workflows.
They can be centrally managed and deployed.
Key advantages that we observed:
Lets you selectively unpack kits and skip pulling what you don’t need.
Acts as your private model registry
Gives you one-command deployment
Works with your existing container registry
Lets you create RAG pipelines as well
Has built-in LLM fine-tuning support.
Supports Kubernetes/KServe config generation
We have wrapped up KitOps CLI and their Python SDK in an MCP server, and the video at the top gives a detailed walkthrough of how you can use it.
Here are all the relevant links:
Implement ReAct Agentic Pattern from Scratch
Consider the output of a multi-agent system below:
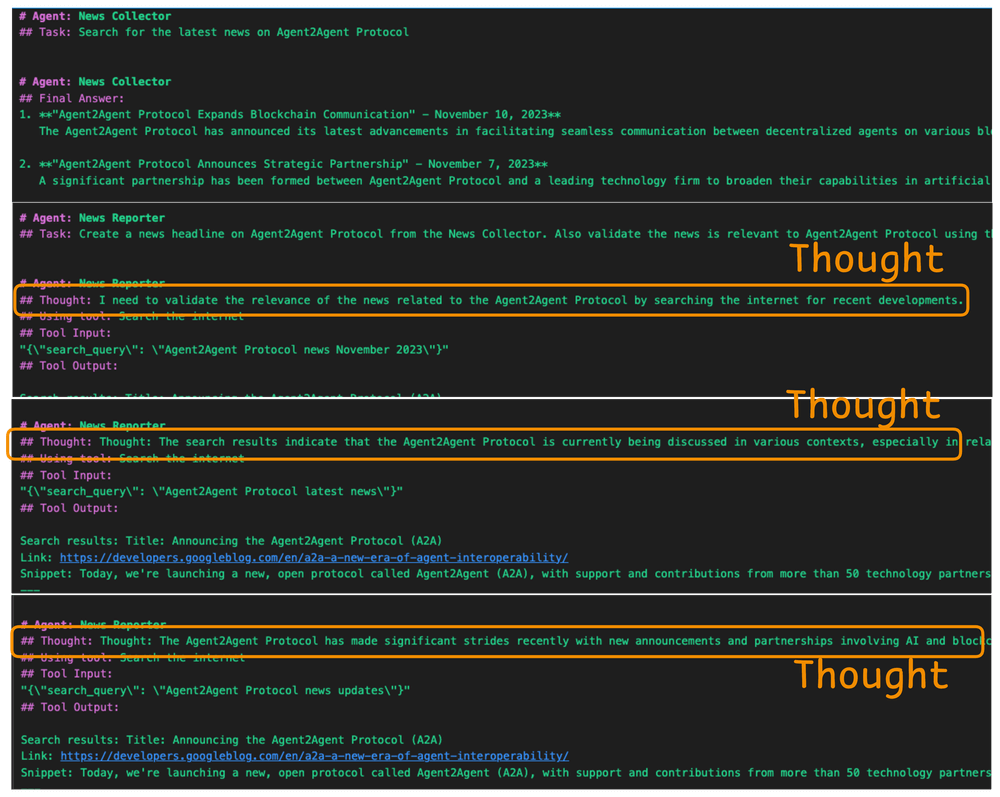
As shown above, the Agent is going through a series of thought activities before producing a response.
This is ReAct pattern in action!
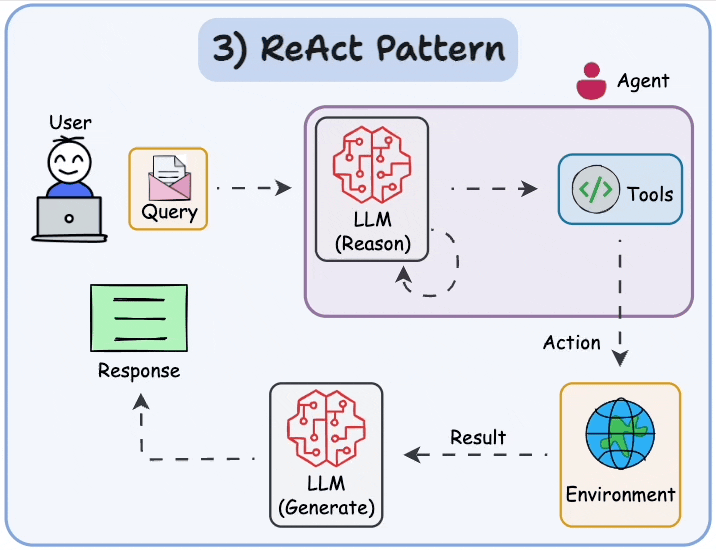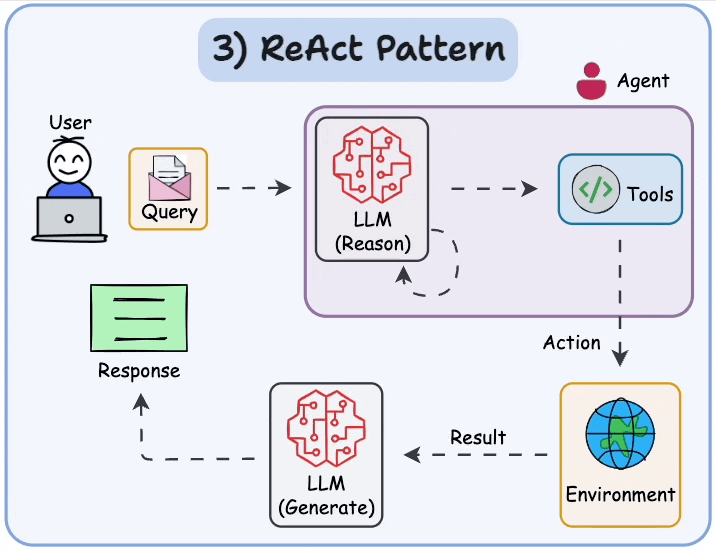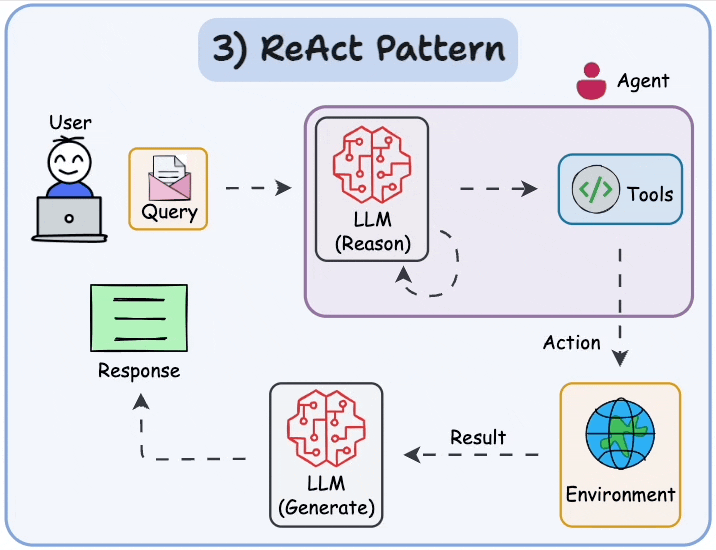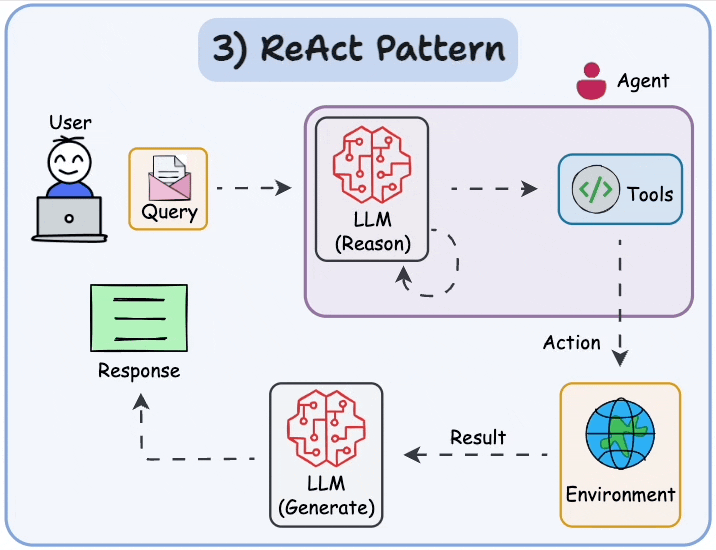
More specifically, under the hood, many frameworks use the ReAct (Reasoning and Acting) pattern to think through problems and use tools to act on the world.
This enhances an LLM agent’s ability to handle complex tasks and decisions by combining chain-of-thought reasoning with external tool use.
We have also seen this being asked in several LLM interview questions.
You can learn how to implement it from scratch here →
It covers:
The entire ReAct loop pattern (Thought → Action → Observation → Answer), which powers intelligent decision-making in many agentic systems.
How to structure a system prompt that teaches the LLM to think step-by-step and call tools deterministically.
How to implement a lightweight agent class that keeps track of conversations and interfaces with the LLM.
A fully manual ReAct loop for transparency and debugging.
A fully automated
agent_loop()controller that parses the agent’s reasoning and executes tools behind the scenes.
Should you gather more data?
At times, no matter how much you try, the model performance barely improves:
Feature engineering gives a marginal improvement.
Trying different models does not produce satisfactory results either.
and more…
This is usually an indicator that we don’t have enough data to work with.
But since gathering new data can be a time-consuming and tedious process...
...here's a technique to determine whether more data will help:
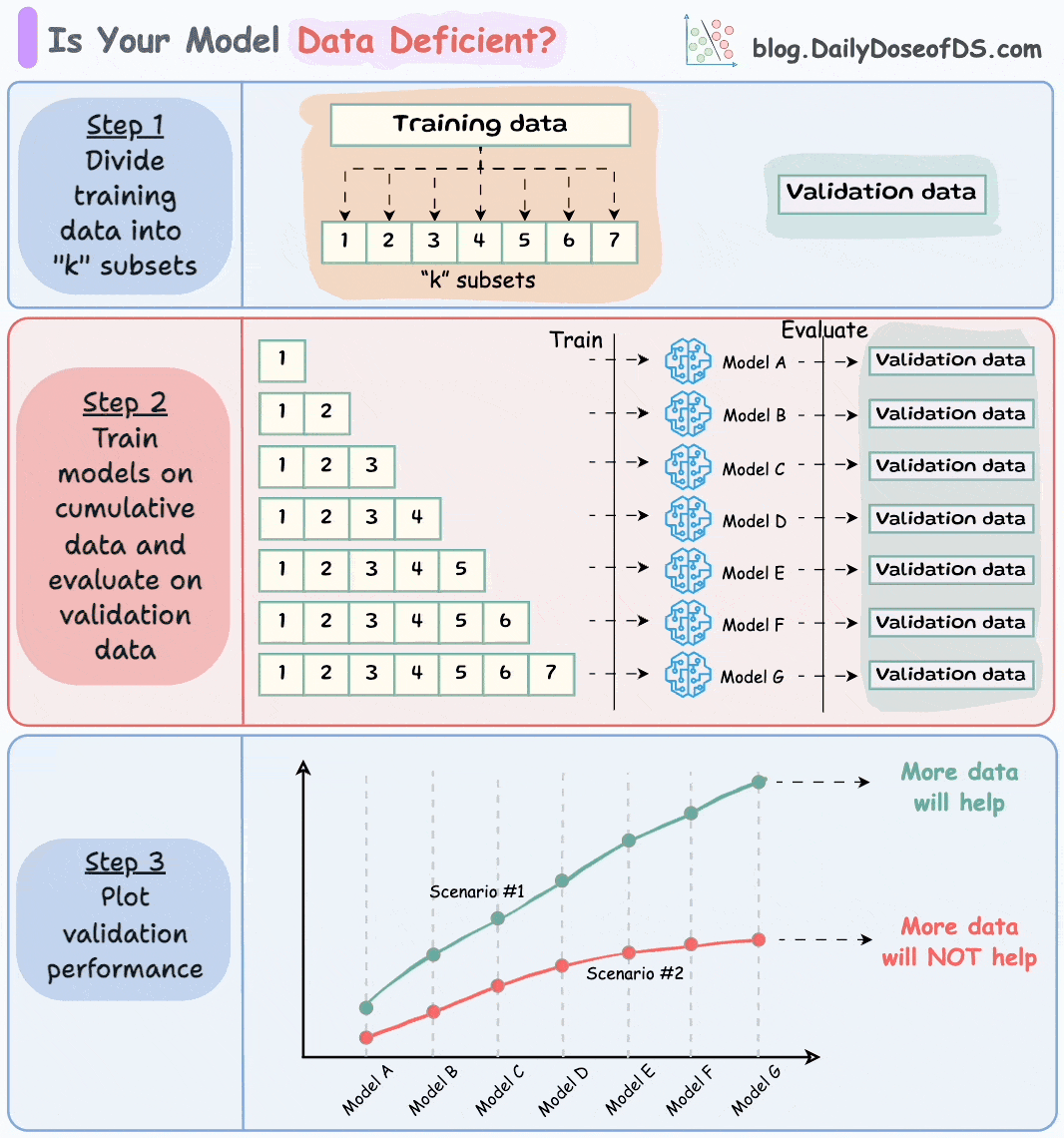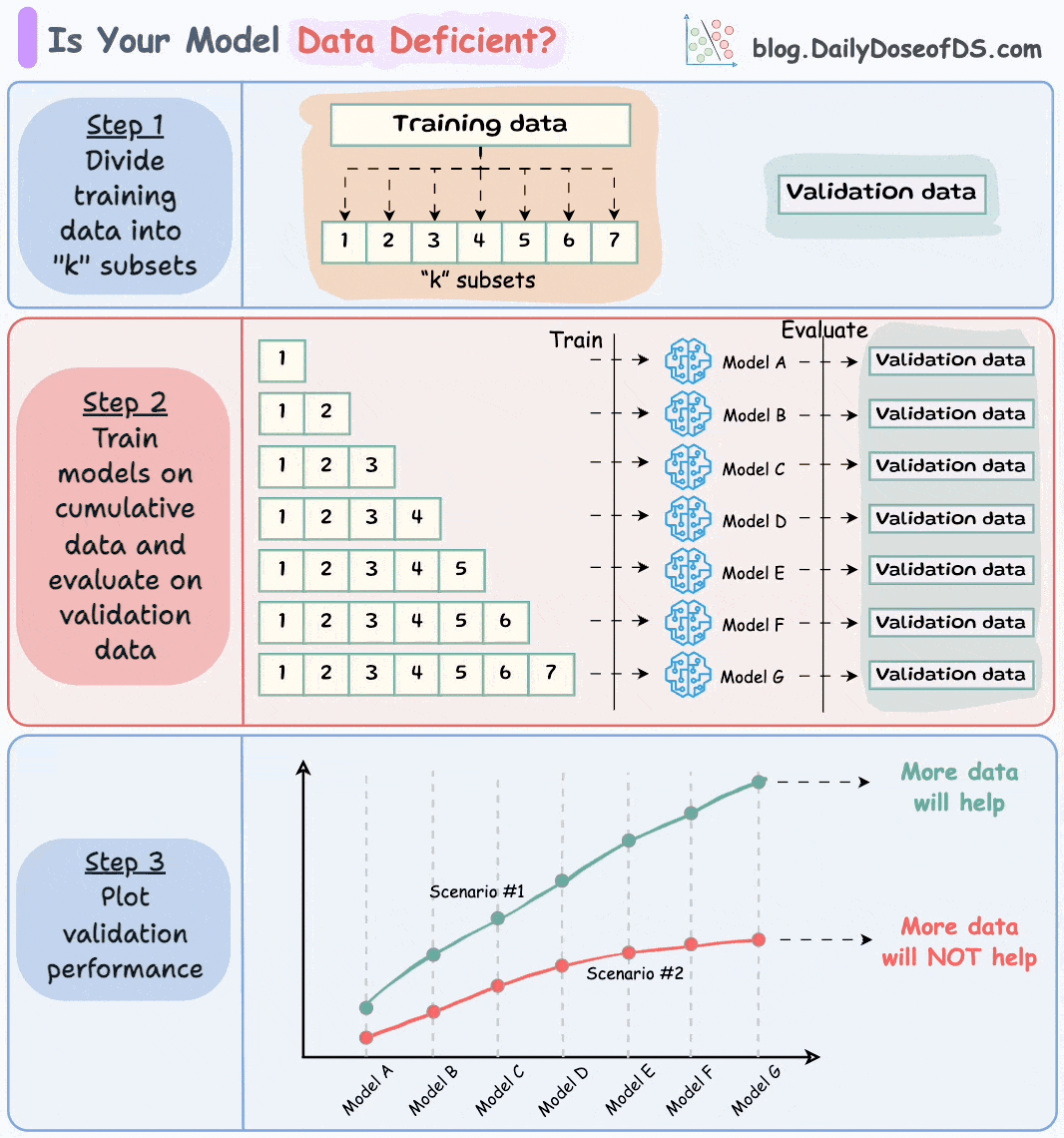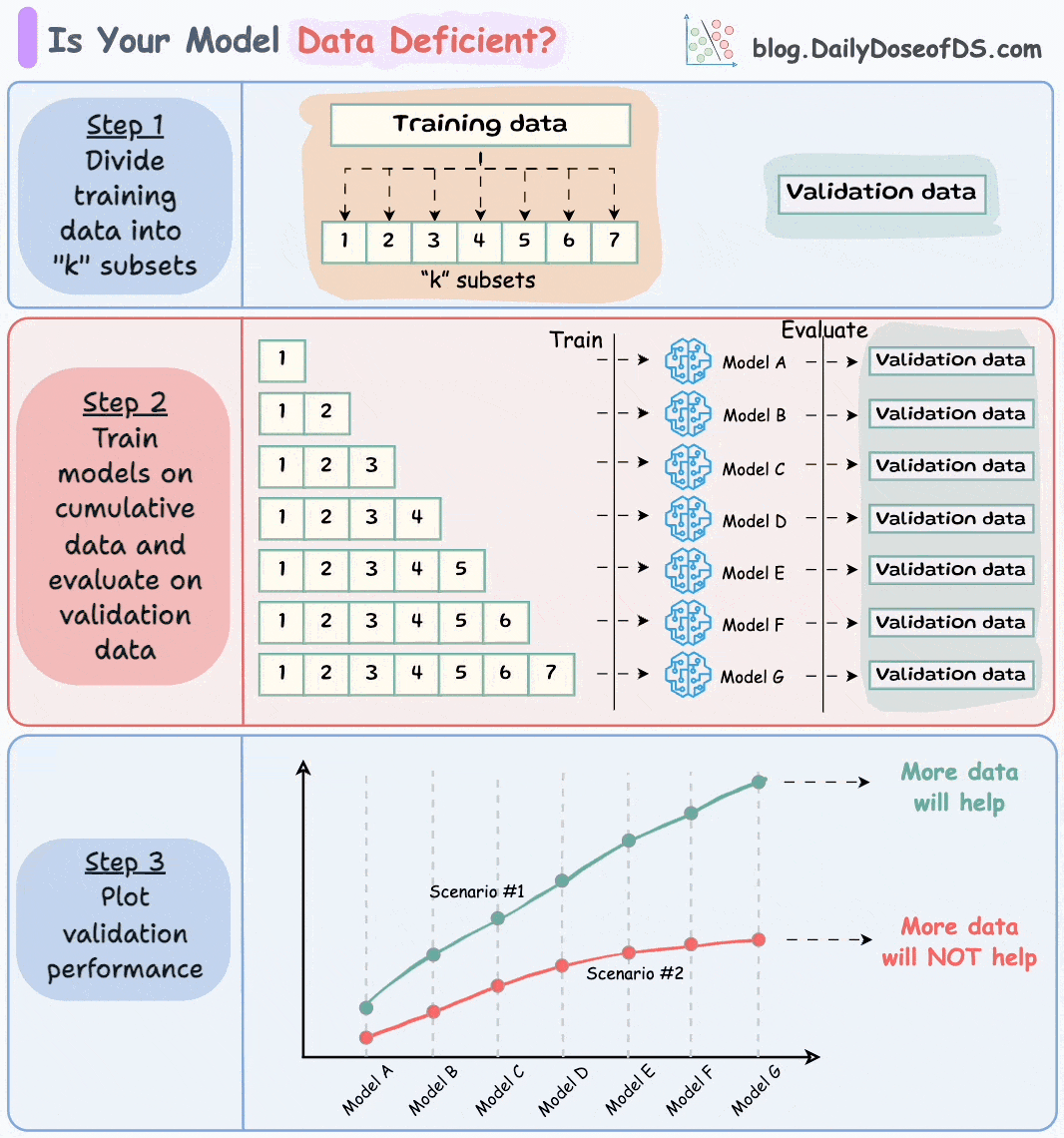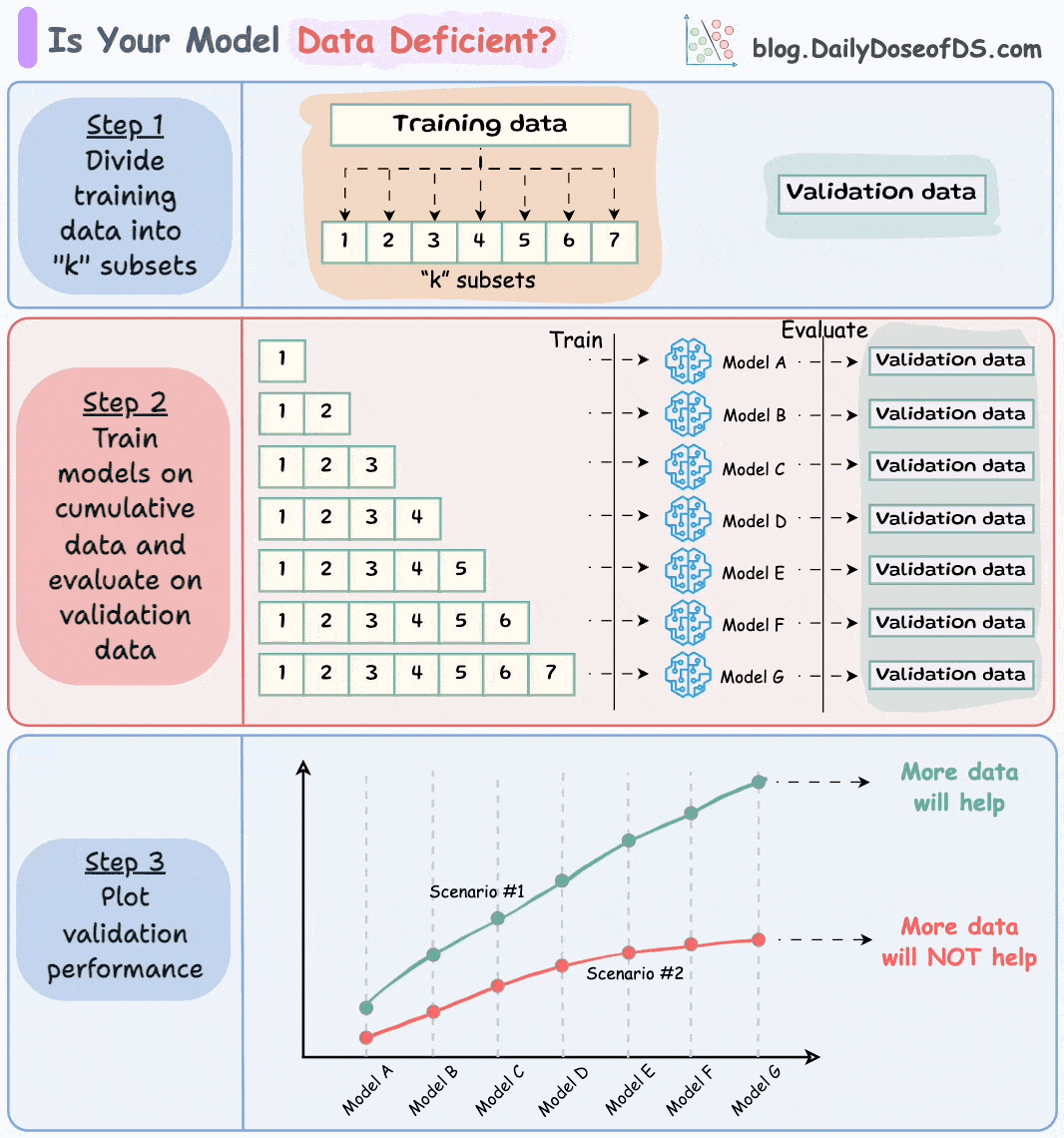
Divide the dataset into “k” equal parts. Usually, 7 to 12 parts are fine.
Train models cumulatively on the above subsets and measure the performance on the validation set:

Train a model on the first subset only.
Train a model on the first two subsets only.
And so on…
Plotting the validation performance will produce one of these two lines:
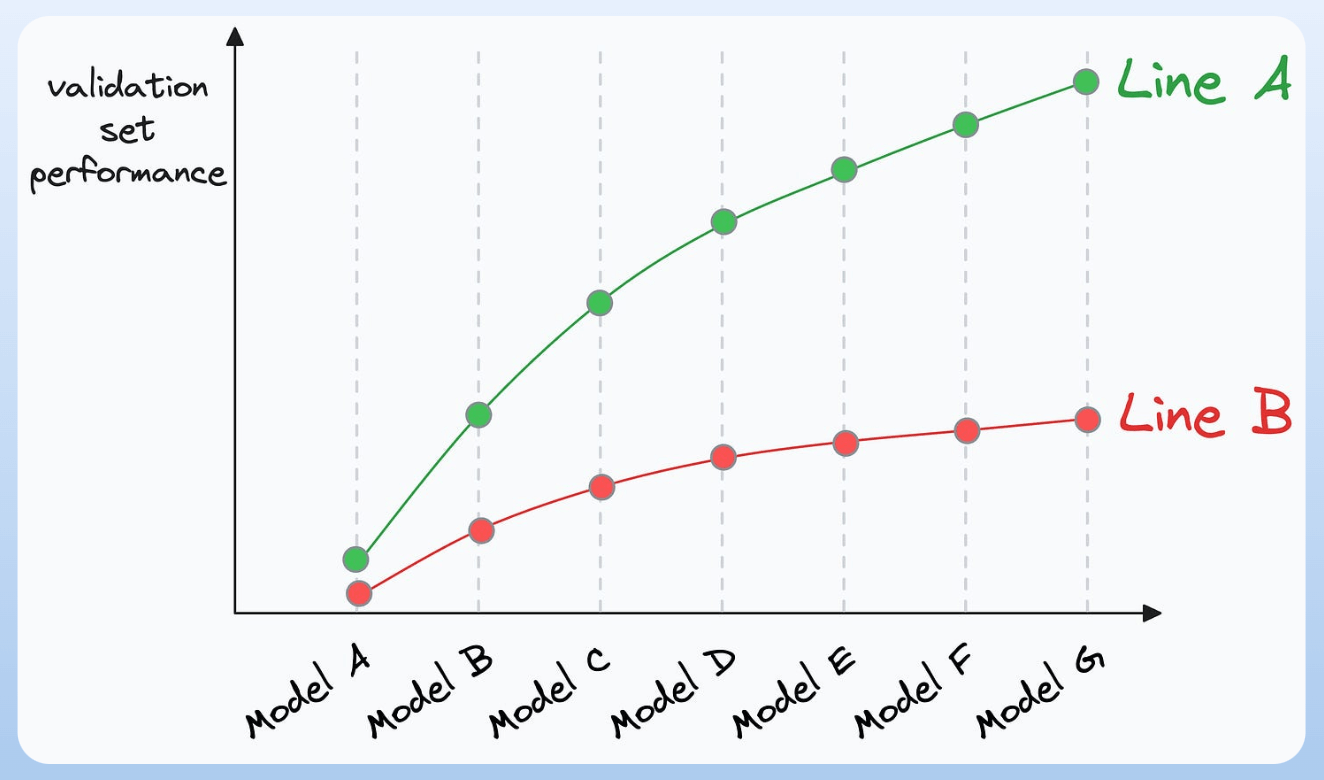
Line A conveys that adding more data will likely increase the model's performance.
Line B conveys that the model's performance has already saturated. Adding more data will most likely not result in any considerable gains.
This way, you can ascertain whether gathering data will help.
Thanks for reading!
