
A Point of Caution When Using One-Hot Encoding
One-Hot encoding introduces a problem.

One-hot encoding introduces a problem in the dataset.

More specifically, when we use it, we unknowingly introduce perfect multicollinearity.
Multicollinearity arises when two (or more) features are highly correlated OR two (or more) features can predict another feature:

In our case, as the sum of one-hot encoded features is always 1, it leads to perfect multicollinearity, and it can be problematic for models that don’t perform well under such conditions.

This problem is often called the Dummy Variable Trap.
Talking specifically about linear regression, for instance, it is bad because:
In some way, our data has a redundant feature.
Regression coefficients aren’t reliable in the presence of multicollinearity, etc.
That said, the solution is pretty simple.
Drop any arbitrary feature from the one-hot encoded features.
This instantly mitigates multicollinearity and breaks the linear relationship that existed before, as depicted below:

The above way of categorical data encoding is also known as dummy encoding, and it helps us eliminate the perfect multicollinearity introduced by one-hot encoding.
The visual below neatly summarizes this entire post:

Further reading
If you want to learn about more categorical data encoding techniques, here’s the visual from a recent post in this newsletter: 7 Categorical Data Encoding Techniques.
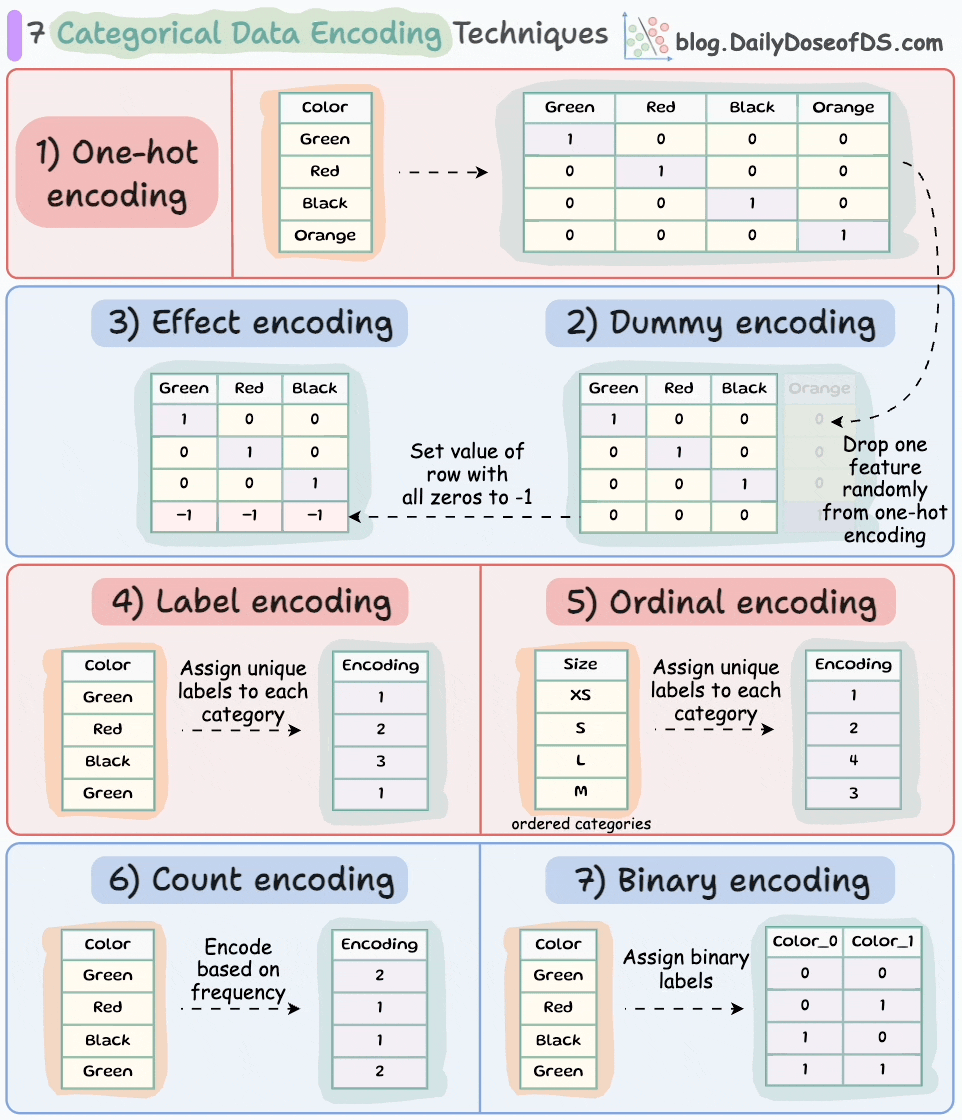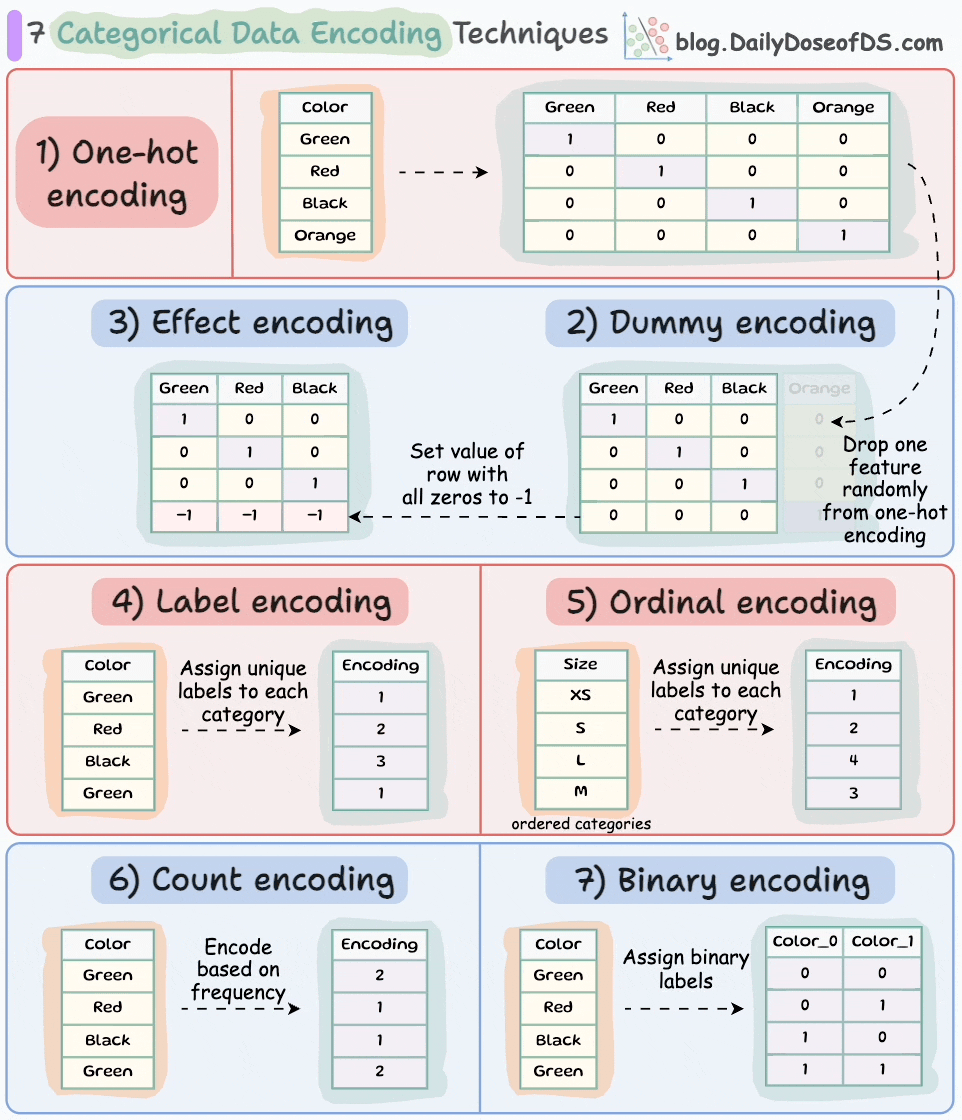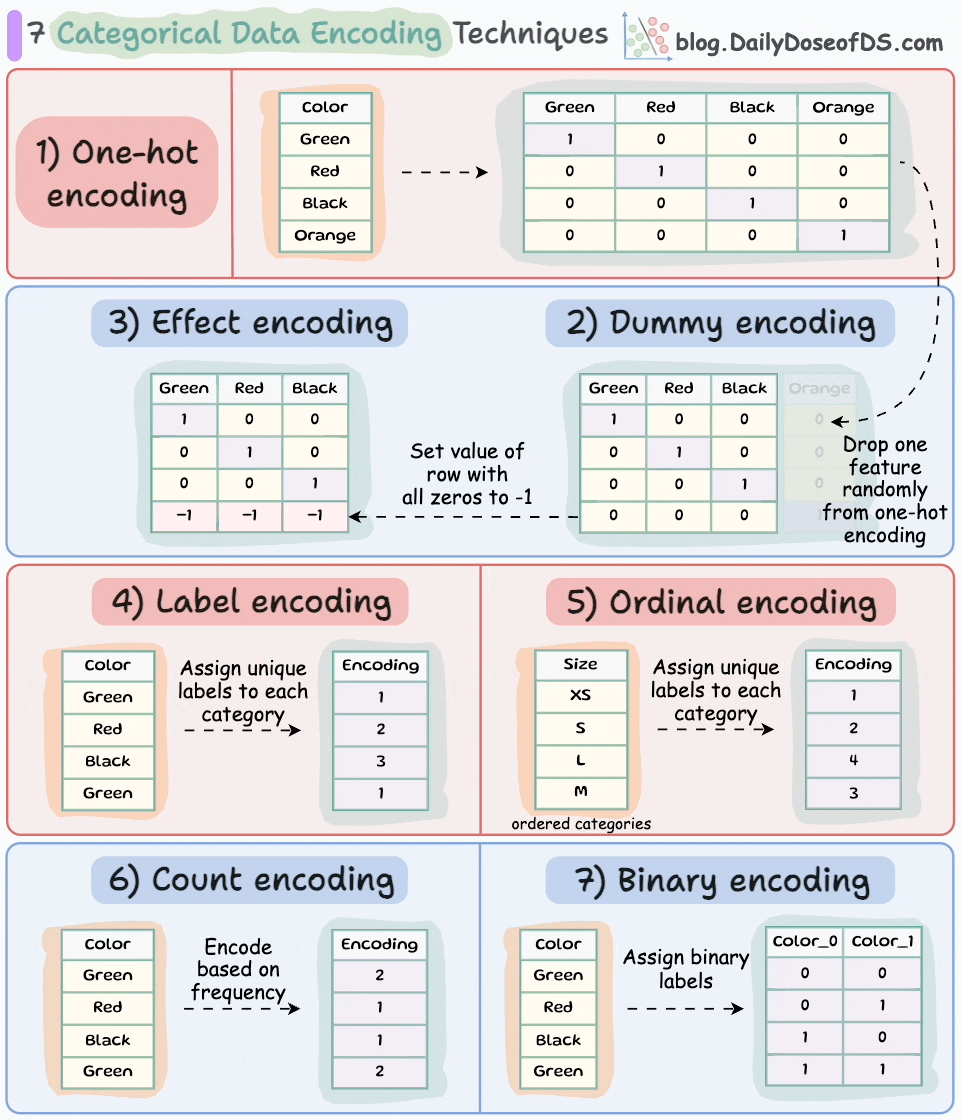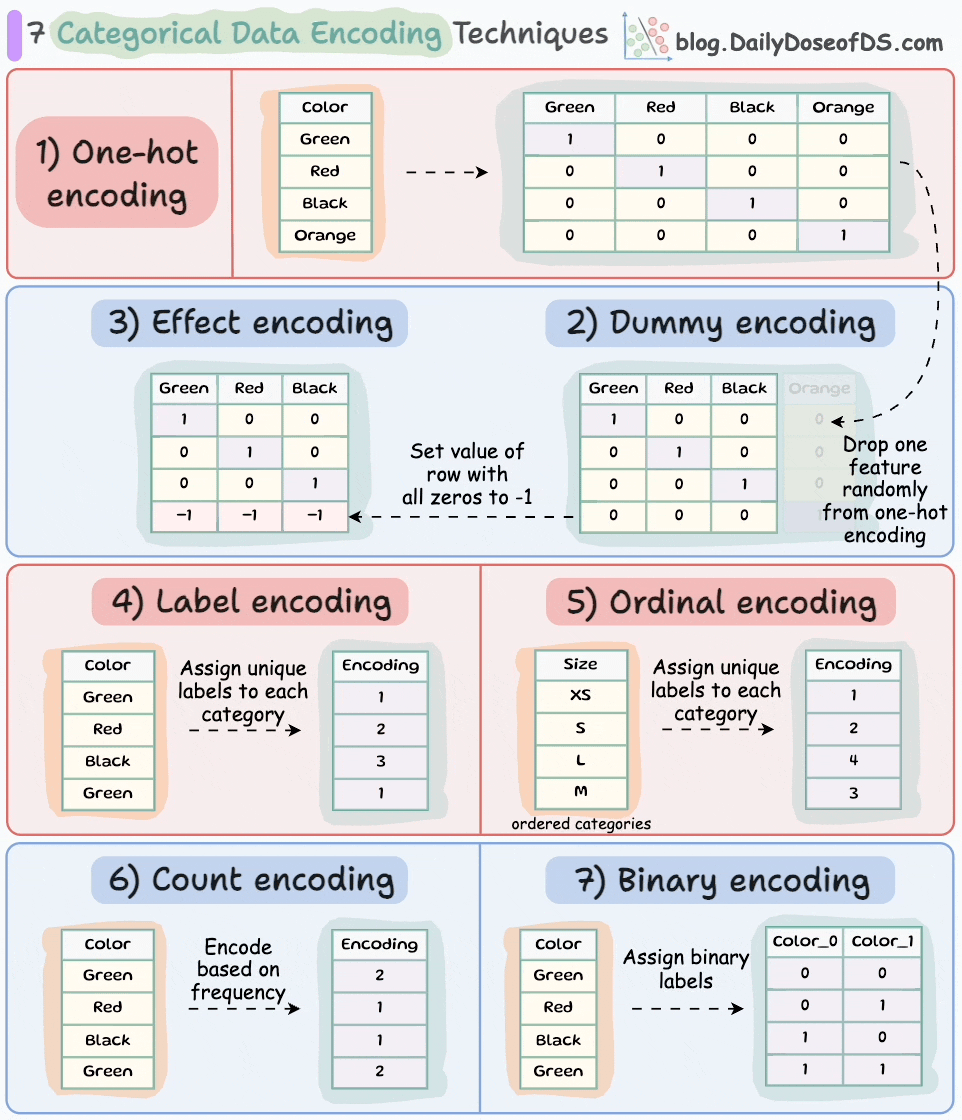
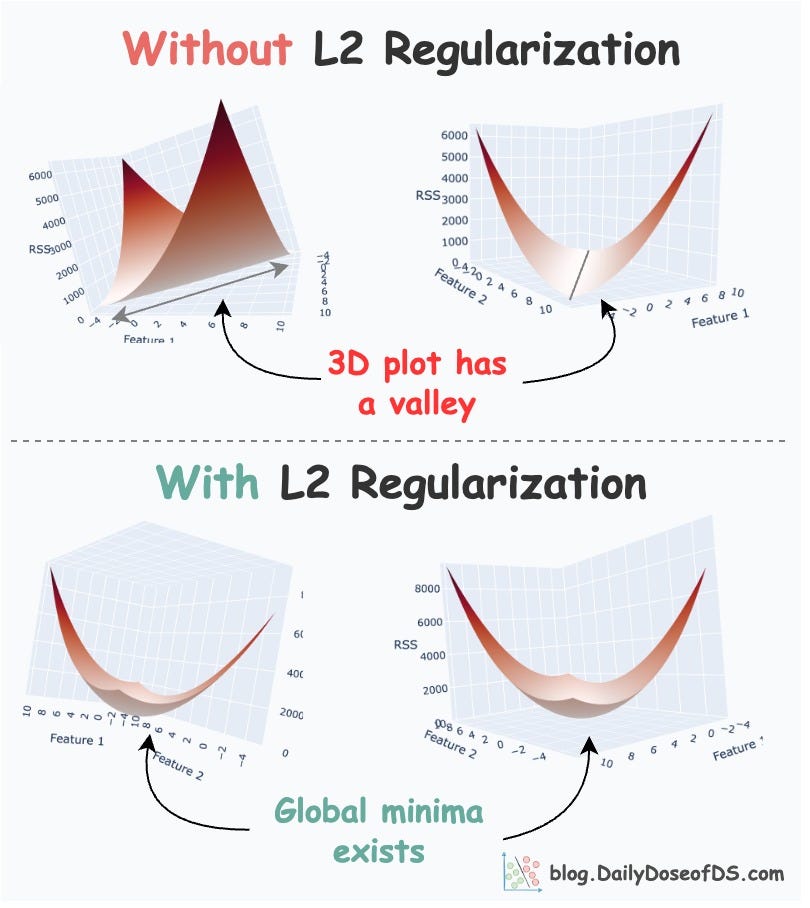
What’s more, do you know that L2 regularization is also a great remedy for multicollinearity. We covered this topic in another issue here: A Lesser-known Advantage of Using L2 Regularization,
👉 Over to you: What are some other problems with one-hot encoding?
For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 100,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
I wouldn't drop any of the features when using a tree-based model, as a tree would have a hard time identifying the members of the class that is dropped.
Nice post Avi. That why I see it's a common practice now a days to just drop a column after implementing one hot encoding.
But I still feel one hot encoding creates lot of sparse columns.
Also I was looking at your paid subscription newletter. It would be good if you made plan for Indian audience as well, and price it accordingly. Keep up the good work