

Get RAG-ready data from any unstructured doc!
Every AI company we have talked to is literally trying to solve this problem!
How to build a RAG system that’s:
hallucination-free
citation-backed
works on complex real-world docs
Here’s how you can do this in just a few lines of code:
Tensorlake lets you extract custom-defined structured data from any unstructured doc in just 3 steps:
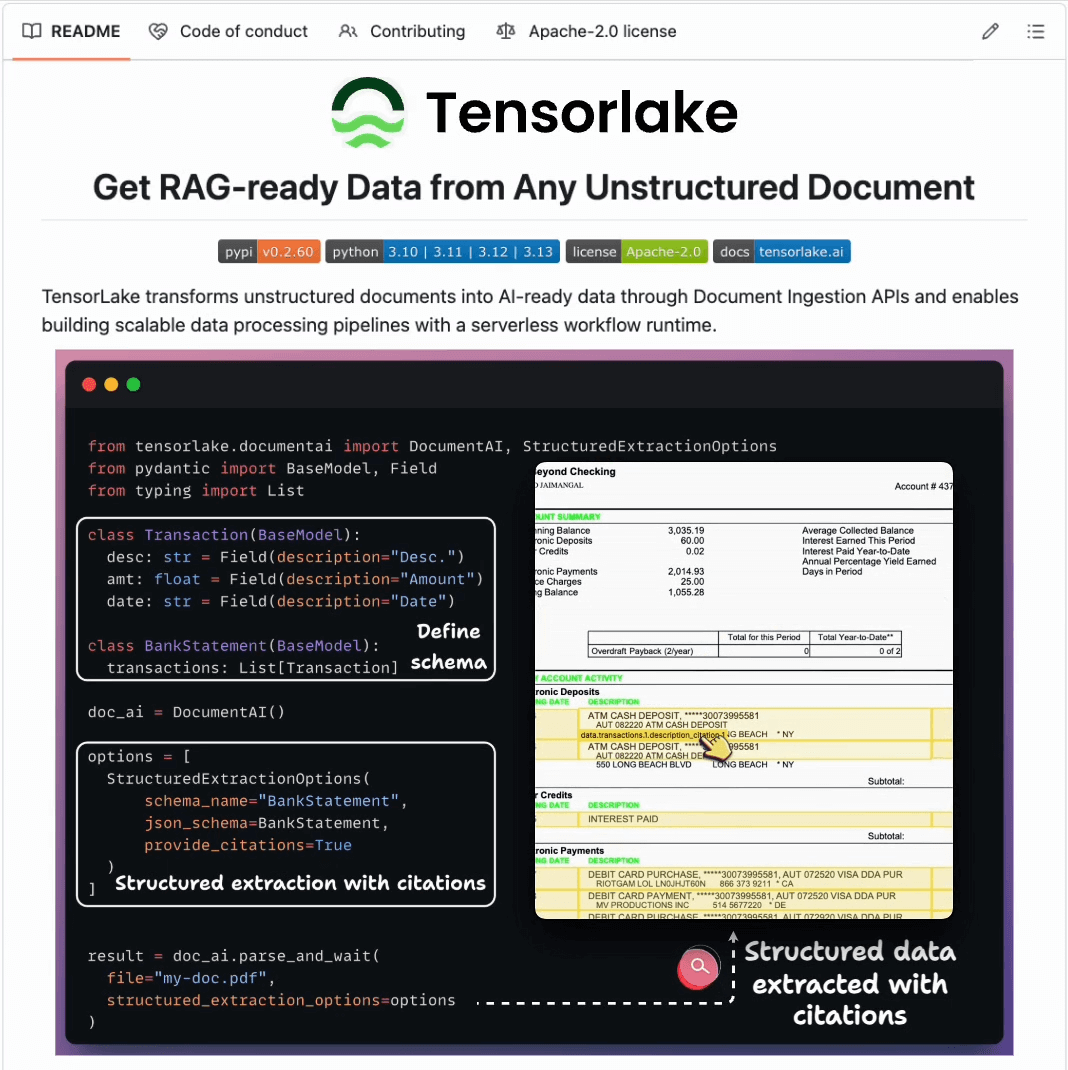
Define schema
Enable citations
Extract
This returns RAG-ready data with precise citations and bounding boxes, which you can feed to your LLM to generate citation-backed and auditable responses.
Find the Tensorlake GitHub repo here → (don’t forget to star it)
Another MCP Moment by Anthropic?
Anthropic just released Claude Skills.
And it might be bigger than MCP:
I’ve been testing skills for the past 3-4 days, and they’re solving a problem most people don’t talk about: agents just keep forgetting everything.
In this video at the top, we have shared everything we have learned so far.
It covers:
The core idea (skills as SOPs for agents)
Anatomy of a skill
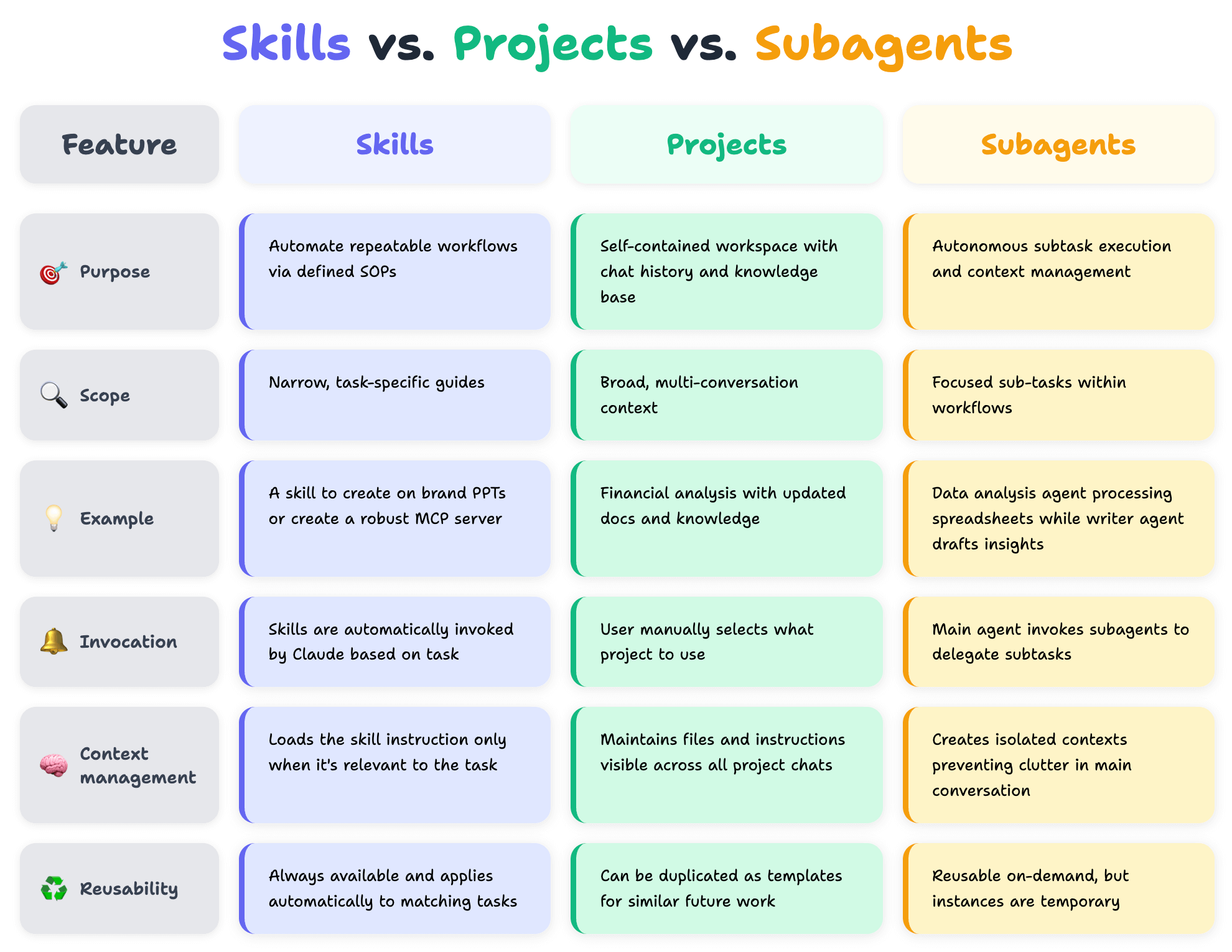
Skills vs. MCP vs. Projects vs. Subagents
Building your own skills
Hands-on example
Skills are the early signs of continual learning that Karpathy also talked about in his recent podcast.
The video has everything you need to know!
That said, talking of the MCP moment, we covered everything you need to know about MCPs in the MCP crash course.
Part 1 covered MCP fundamentals, the architecture, context management, etc. →
Part 2 covered core capabilities, JSON-RPC communication, etc. →
Part 4 built a full-fledged MCP workflow using tools, resources, and prompts →
Part 5 taught how to integrate Sampling into MCP workflows →
Part 6 covered testing, security, and sandboxing in MCP Workflows →
Part 7 covered testing, security, and sandboxing in MCP Workflows →
Part 8 integrated MCPs with the most widely used agentic frameworks: LangGraph, LlamaIndex, CrewAI, and PydanticAI →
Part 9 covered using LangGraph MCP workflows to build a comprehensive real-world use case→
Thanks for watching.
