
Enrich Missing Data Analysis with Heatmaps
A lesser-known technique to identify feature missingness.


💼 Want to become an AI Consultant?
The AI consulting market is about to grow by 8X – from $6.9 billion today to $54.7 billion in 2032.
But how does an AI enthusiast become an AI consultant?
How well you answer that question makes the difference between just “having AI ideas” and being handsomely compensated for contributing to an organization’s AI transformation.
Thankfully, you don’t have to go it alone—our friends at Innovating with AI just welcomed 200 new students into The AI Consultancy Project, their new program that trains you to build a business as an AI consultant.
Some of the highlights current students are excited about:
The tools and frameworks to find clients and deliver top-notch services.
A 6-month plan to build a 6-figure AI consulting business.
Students getting their first AI client in as little as 3 days.
And as a Daily Dose of Data Science reader, you have a chance to get early access to the next enrollment cycle.
Click here to request early access to The AI Consultancy Project.
Thanks to Innovating with AI for sponsoring today’s issue.
Missing Data Analysis with Heatmaps
Real-world datasets almost always have missing values.
In most cases, it is unknown to us beforehand why values are missing.
There could be multiple reasons for missing values. Given that we have already covered this in detail in an earlier issue, so here’s a quick recap:
Missing Completely at Random (MCAR): The value is genuinely missing by itself and has no relation to that or any other observation.

Missing at Random (MAR): Data is missing due to another observed variable. For instance, we may observe that the percentage of missing values differs significantly based on other variables.

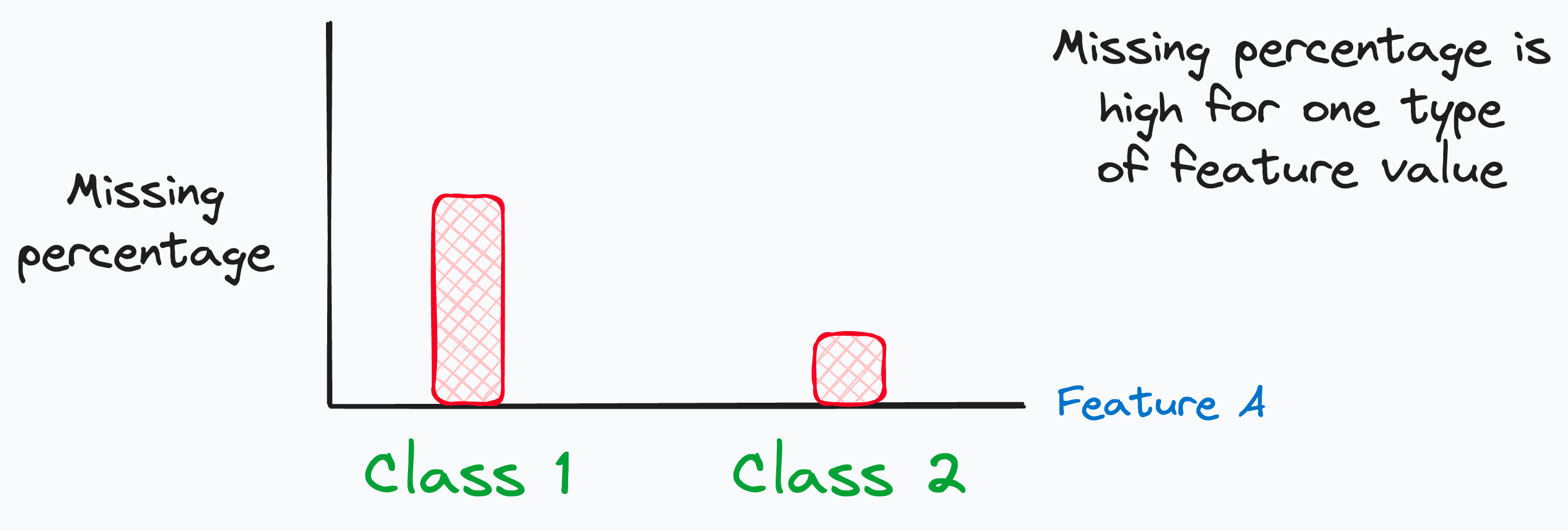
Missing NOT at Random (MNAR): This one is tricky. MNAR occurs when there is a definite pattern in the missing variable. However, it is unrelated to any feature we can observe in our data. In fact, this may depend on an unobserved feature.

Please read this issue for more details: 3 Types of Missing Values.
Identifying the reason for missingness can be extremely useful for further analysis, imputation, and modeling.
Today, let’s understand how we can enrich our missing value analysis with heatmaps.
Consider we have a daily sales dataset of a store that has the following information:

Day and Date
Store opening and closing time
Number of customers
Total sales
Account balance at open and close time
We can clearly see some missing values, but the reason is unknown to us.
Here, when doing EDA, many folks compute the column-wise missing frequency as follows:
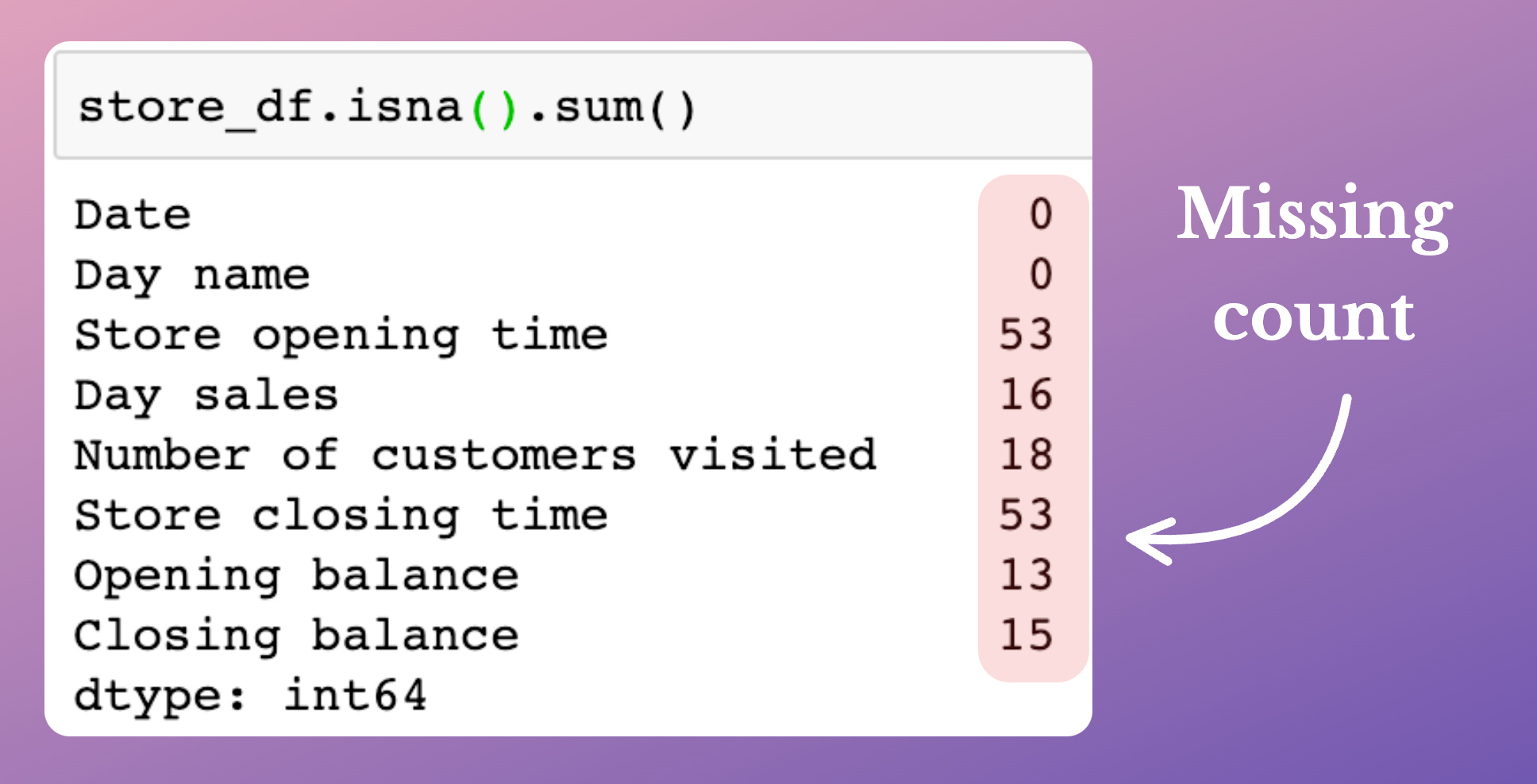
The above table just highlights the number of missing values in each column.
More specifically, we get to know that:
Missing values are relatively high in two columns compared to others.
Missing values in the opening and closing time columns are the same (53).
That’s the only info it provides.
However, the problem with this approach is that it hides many important details about missing values, such as:
Their specific location in the dataset.
Periodicity of missing values (if any).
Missing value correlation across columns, etc.
…which can be extremely useful to understand the reason for missingness.
To put it another way, the above table is more like summary statistics, which rarely depict the true picture.
Why?
We have already discussed this a few times before in this newsletter, such as here and here, and below are the visuals from these posts:

So here’s how I often enrich my missing value analysis with heatmaps.
Compare the missing value table we discussed above with the following heatmap of missing values:
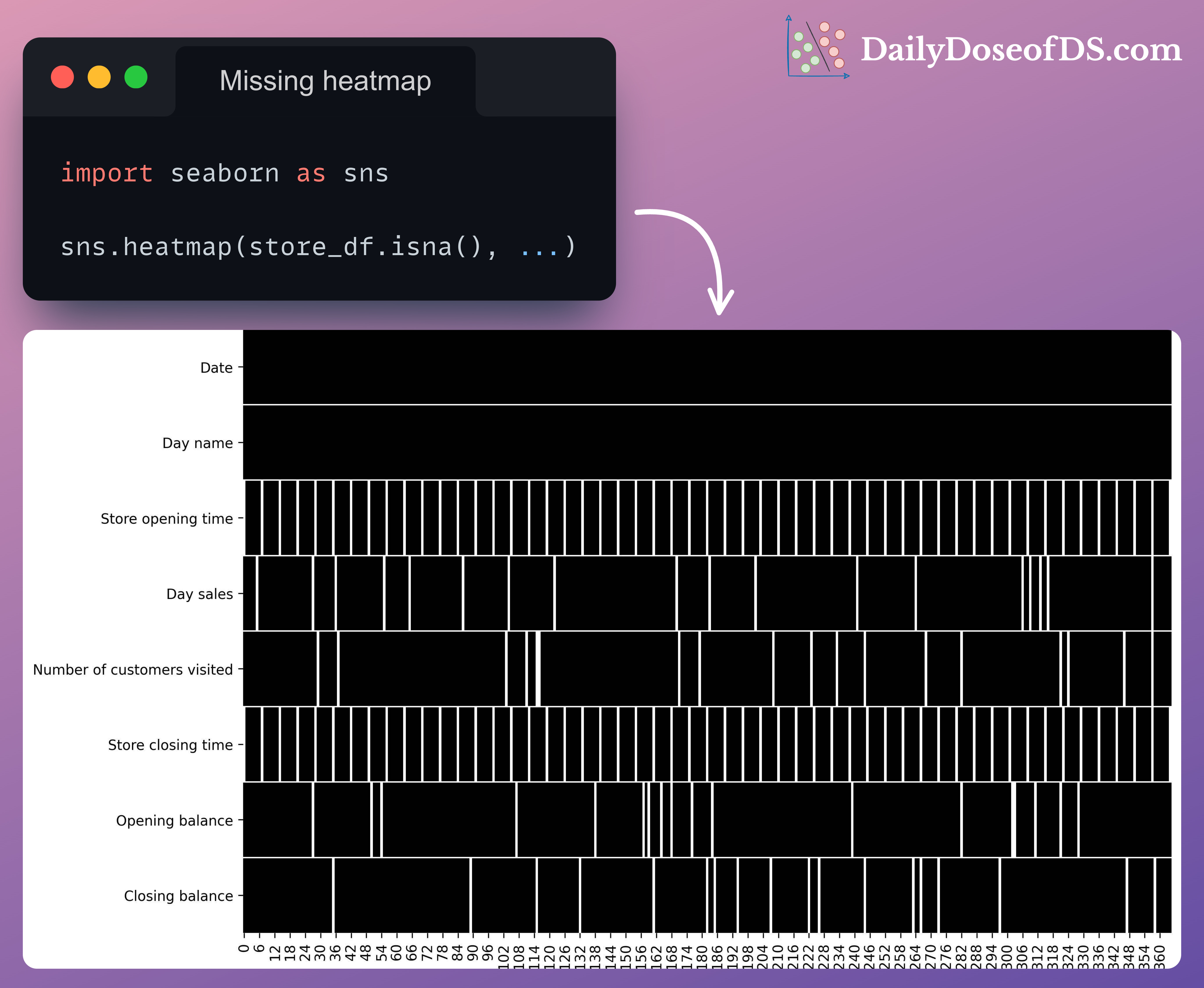
The white vertical lines depict the location of missing values in a specific column.
Now, it is immediately clear that:
Values are periodically missing in the opening and closing time columns.
Missing values are correlated in the opening and closing time columns.
The missing values in other columns appear to be (not necessarily though) missing completely at random.
Further analysis of the opening time lets us discover that the store always remains closed on Sundays:

Now, we know why the opening and closing times are missing in our dataset.
This information can be beneficial during its imputation.
This specific situation is “Missing at Random (MAR).”
Essentially, as we saw above, the missingness is driven by the value of another observed column.
Now that we know the reason, we can use relevant techniques to impute these values if needed.
For MAR specifically, techniques like kNN imputation, Miss Forest, etc., are quite effective. We covered them here:

Wasn’t that helpful over naive “missing-value-frequency” analysis?
👉 Over to you: What are some other ways to improve missing data analysis?
For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 100,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
This is very good way to know why there are missing value in a dataset with multiple variables. But how do we do this in the case of time series data where we only have time/day and the corresponding data? Can you explain how to tackle missing data in time series data?