

95% Agents die before production. The remaining 5% do this.
An AI chatbot’s accuracy is useless if users keep escalating their issue to a human.
That’s why user-facing AI systems also need to optimize for “containment”, i.e., how often the Agent resolves the issue without escalation.
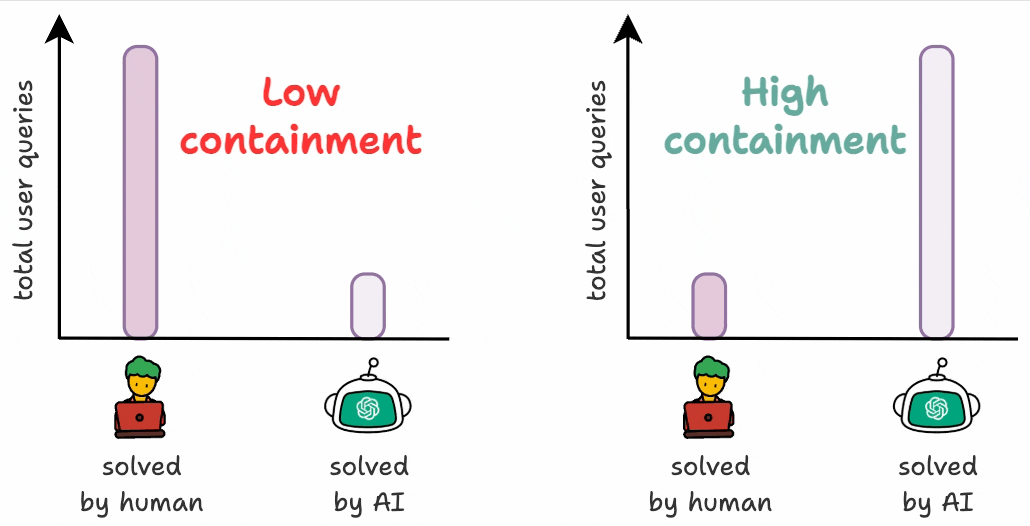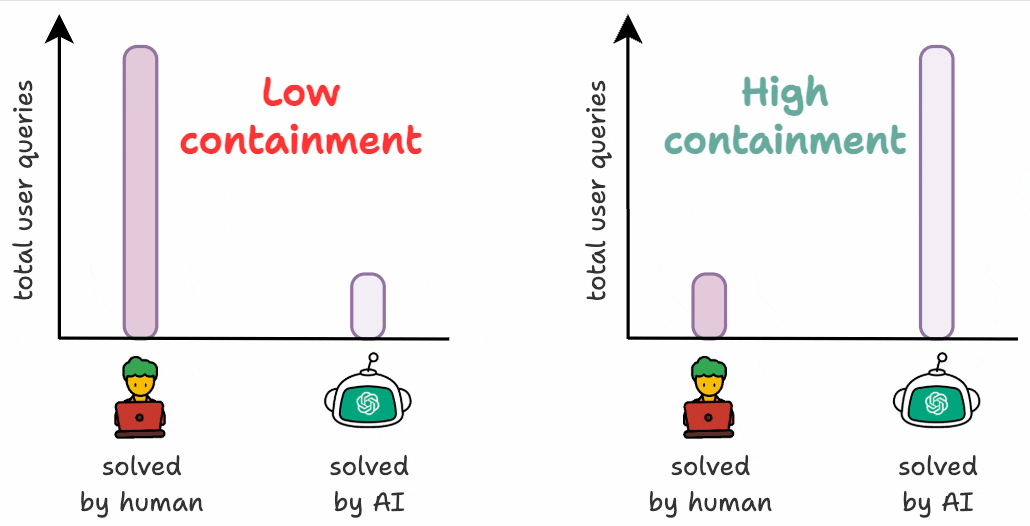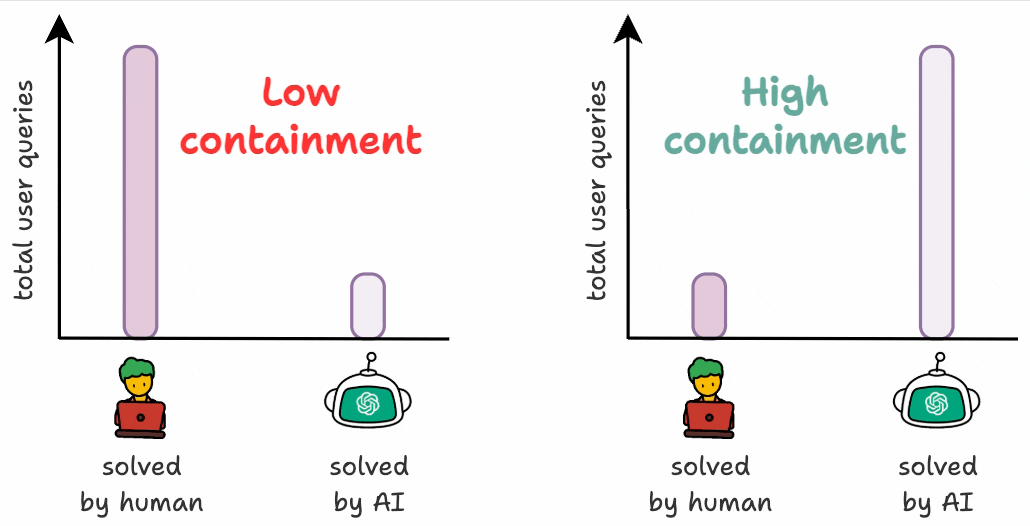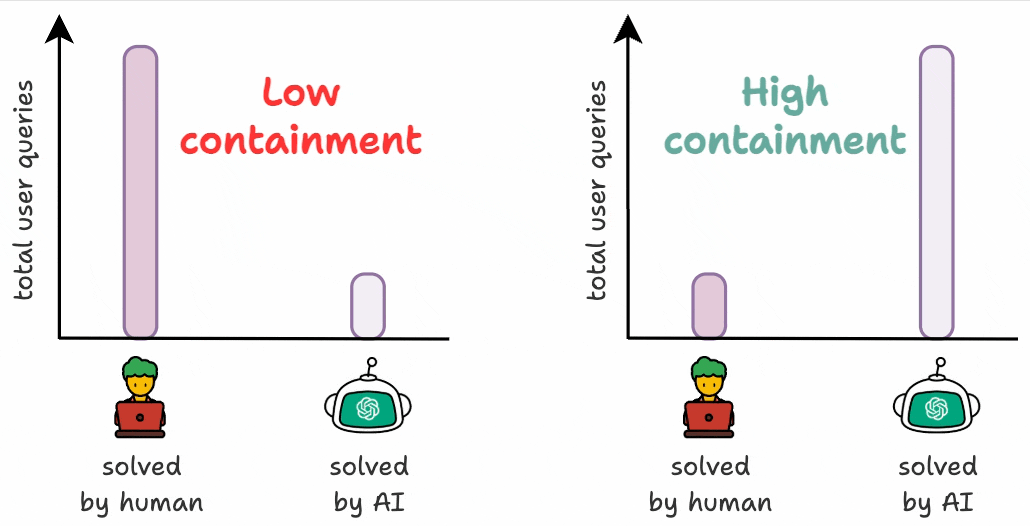
Here are some tactical ways to build user-facing Agents, inspired by Parlant (an open-source framework that lets you build Agents with control).

LLMs lose focus due to huge system prompts. Prevent this by pairing every rule with a condition (when it applies) and an action (what to do), and let the engine pull only the relevant subset per turn.
In high-risk cases, even the worst 0.001% matters. Parlant guards the two terminals that usually cause this:
Tool calls: Scope when tools are even considered by running structured reasoning.
User messages: Allows users to reply from a set of responses only. You can still keep it conversational by providing several variants.
Flows are brittle. Instead, build Journeys. They are state machines that allow the Agent to skip, backtrack, and even run multiple journeys in parallel (e.g., “card fraud report” & “lock card”).
We have built several Agents and have realized that building Agents is primarily about engineering and automating “behaviour” at scale. So you cannot vibe-prompt your Agent and just expect it to work.
Parlant gives you the structure to build customer-facing agents that behave exactly as instructed.
We will cover this in a hands-on demo soon.
Find the GitHub repo here → (don’t forget to star it)
Build a Reasoning LLM using GRPO
Group Relative Policy Optimization is a reinforcement learning method that fine-tunes LLMs for math and reasoning tasks using deterministic reward functions, eliminating the need for labeled data.
Here's a brief overview of GRPO:
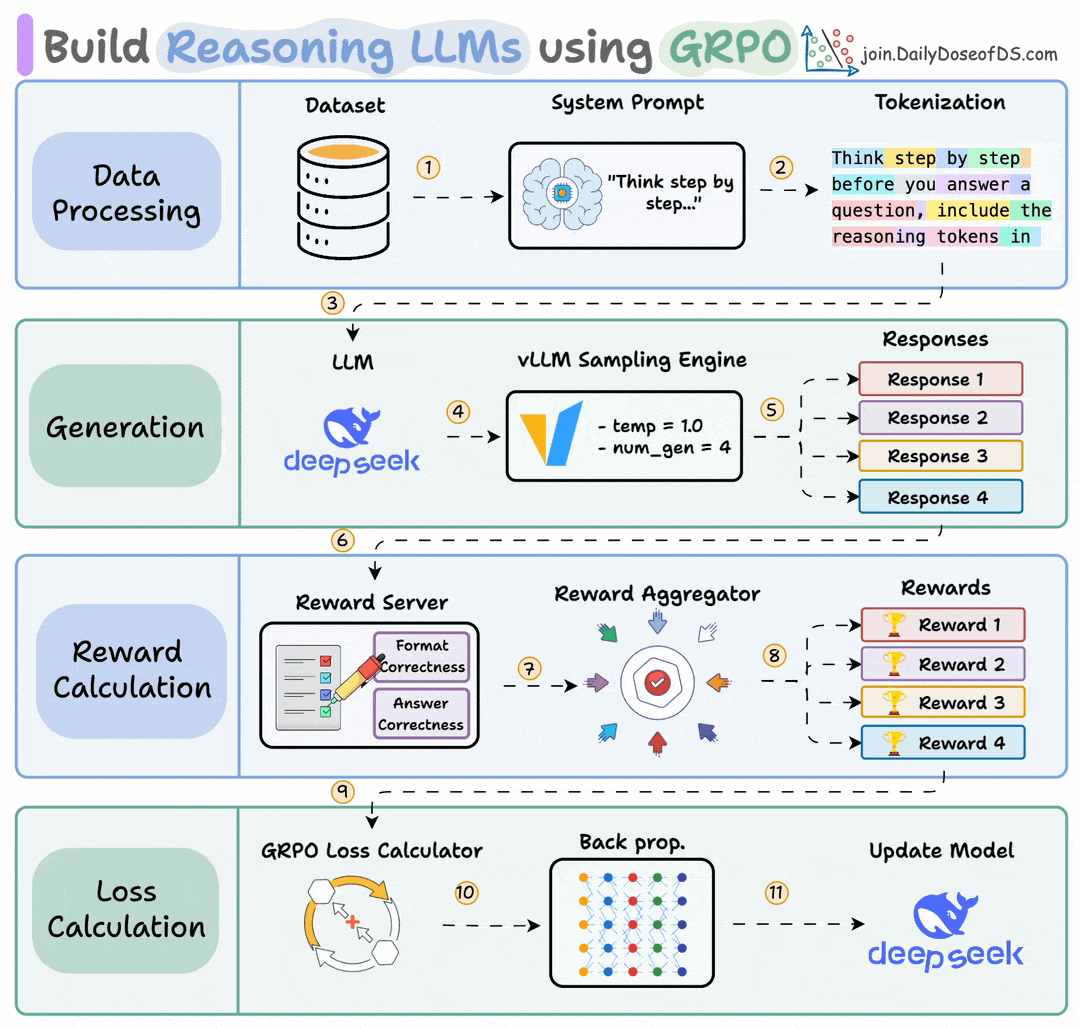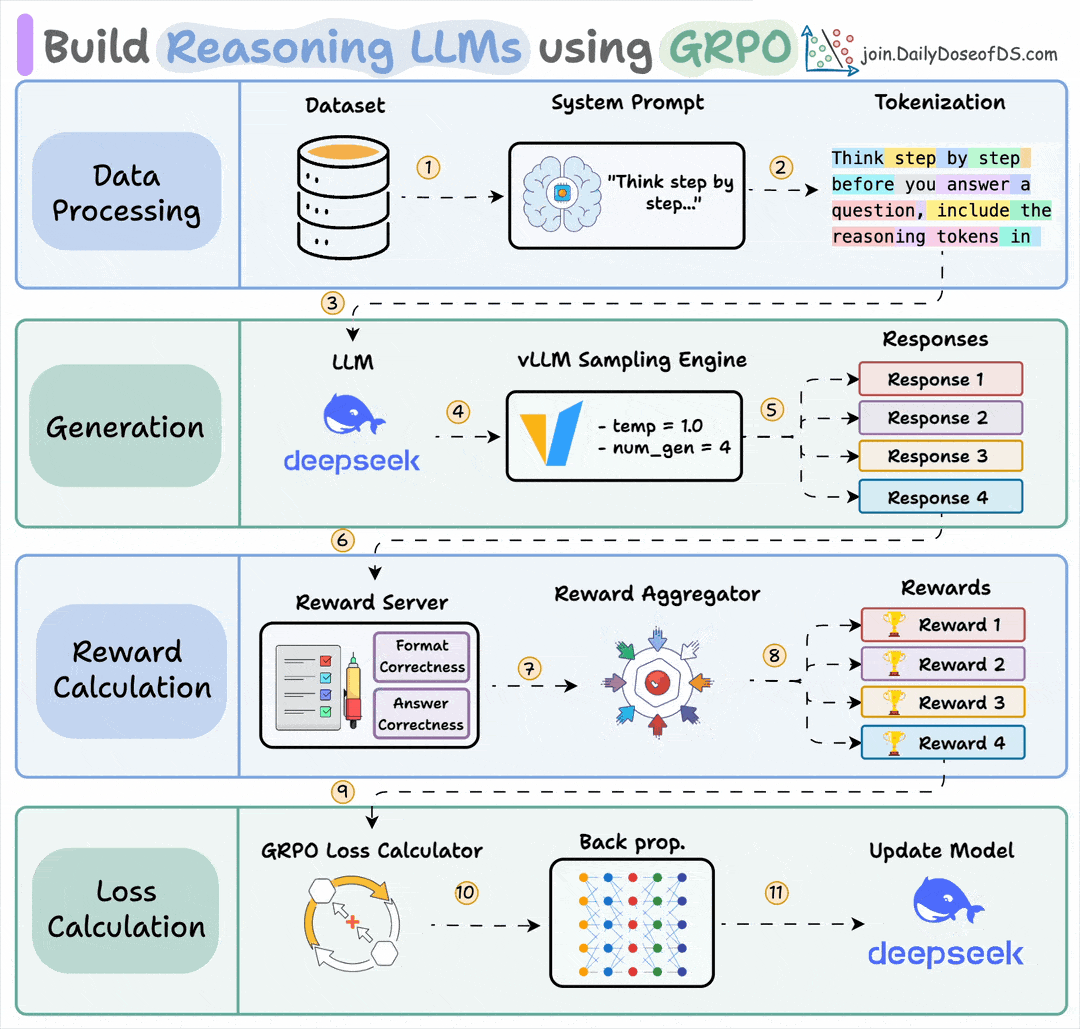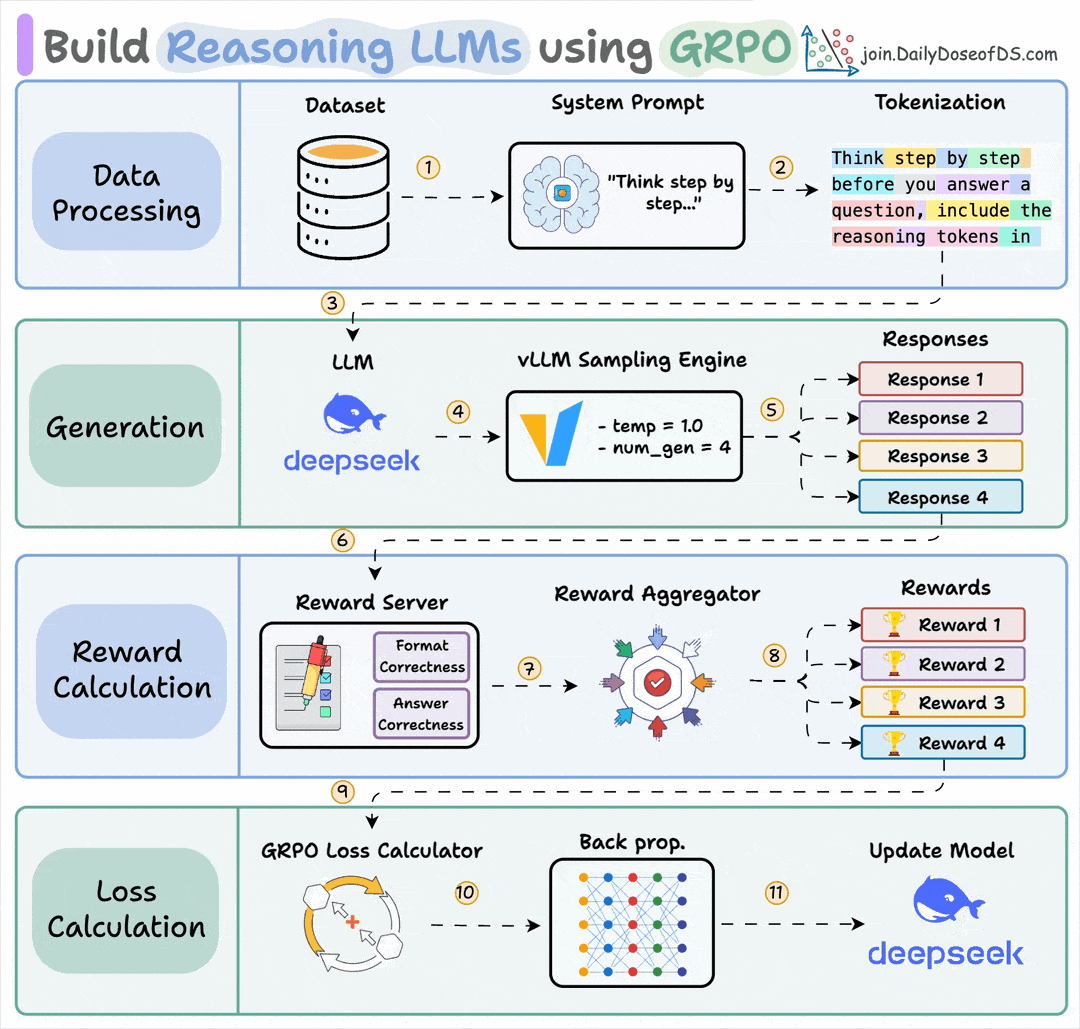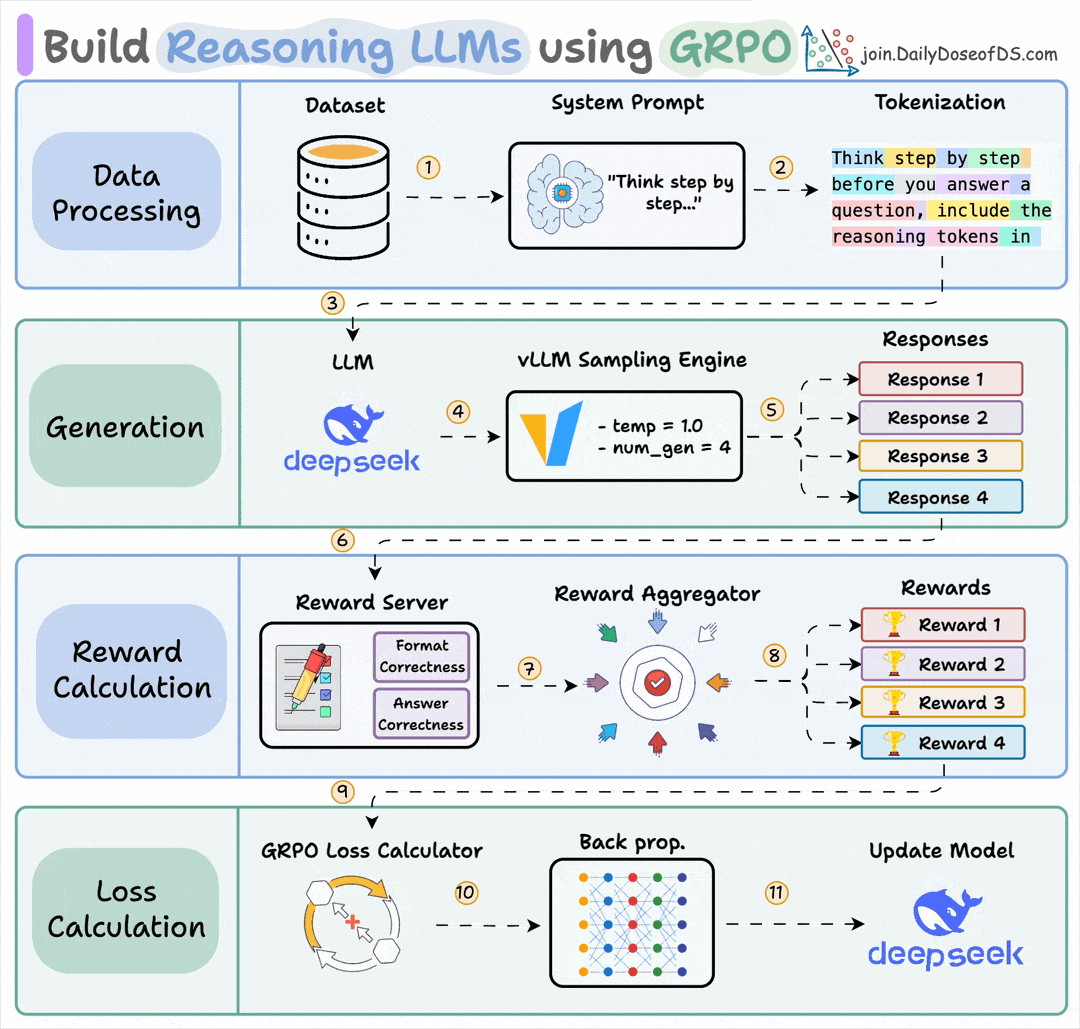
Start with a dataset and add a reasoning-focused system prompt (e.g., “Think step by step…”).
The LLM generates multiple candidate responses using a sampling engine.
Each response is assigned rewards, which are aggregated to produce a score for every generated response.
A GRPO loss function uses these rewards to calculate gradients, backpropagation updates the LLM, and the model improves its reasoning ability over time.
Let’s dive into the code to see how we can use GRPO to turn any model into a reasoning powerhouse without any labeled data or human intervention.
We’ll use:
UnslothAI for efficient fine-tuning.
HuggingFace TRL to apply GRPO.
The code is available here: Build a reasoning LLM from scratch using GRPO. You can run it without any installations by reproducing our environment below:

Let’s begin!
Load the model
We start by loading Qwen3-4B-Base and its tokenizer using Unsloth.
You can use any other open-weight LLM here.

Define LoRA config
We'll use LoRA to avoid fine-tuning the entire model weights. In this code, we use Unsloth's PEFT by specifying:
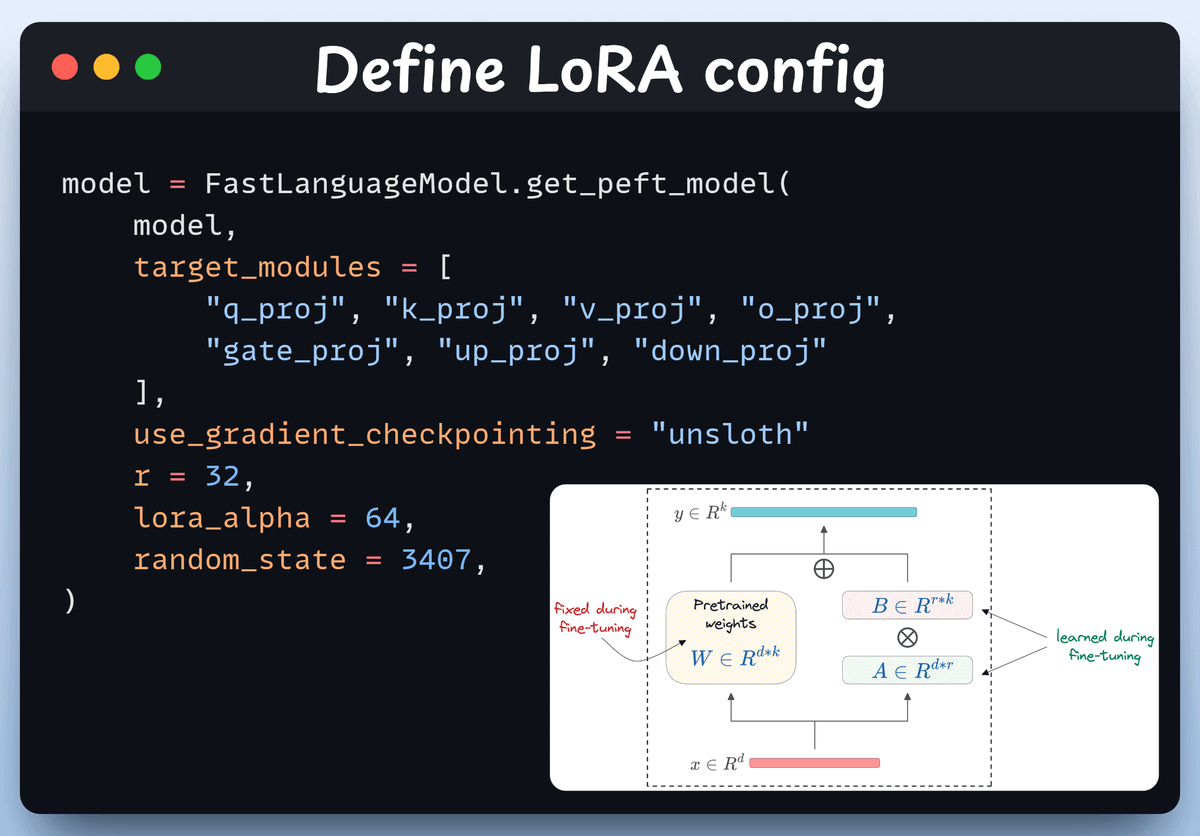
The model
LoRA low-rank (r)
Modules for fine-tuning, etc.
Create the dataset
We load the Open R1 Math dataset (a math problem dataset) and format it for reasoning.
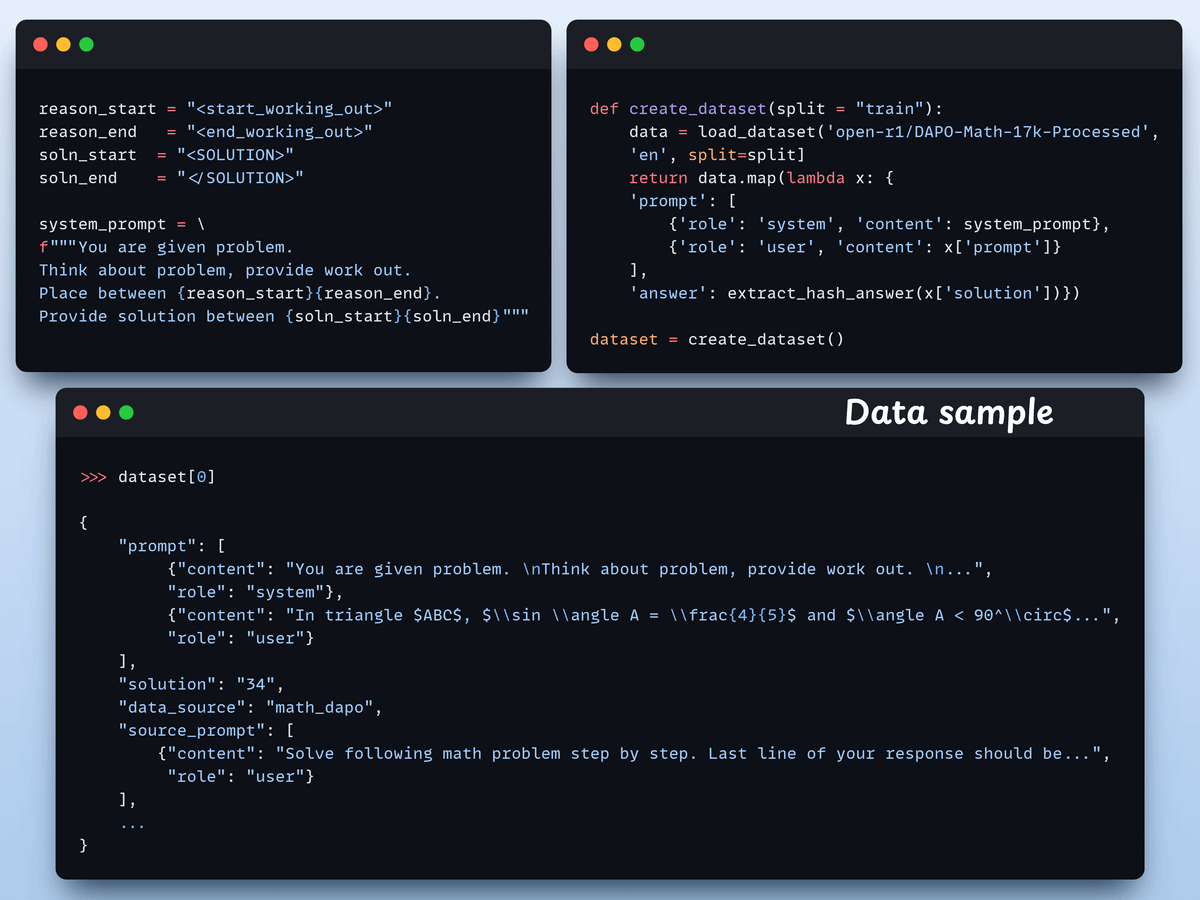
Each sample includes:
A system prompt enforcing structured reasoning
A question from the dataset
The answer in the required format
Define reward functions
In GRPO, we use deterministic functions to validate the response and assign a reward. No manual labelling required!
The reward functions:

Match format exactly
Match format approximately
Check the answer
Check numbers
Use GRPO and start training
Now that we have the dataset and reward functions ready, it's time to apply GRPO.
HuggingFace TRL provides everything we described in the GRPO diagram, out of the box, in the form of the GRPOConfig and GRPOTrainer.
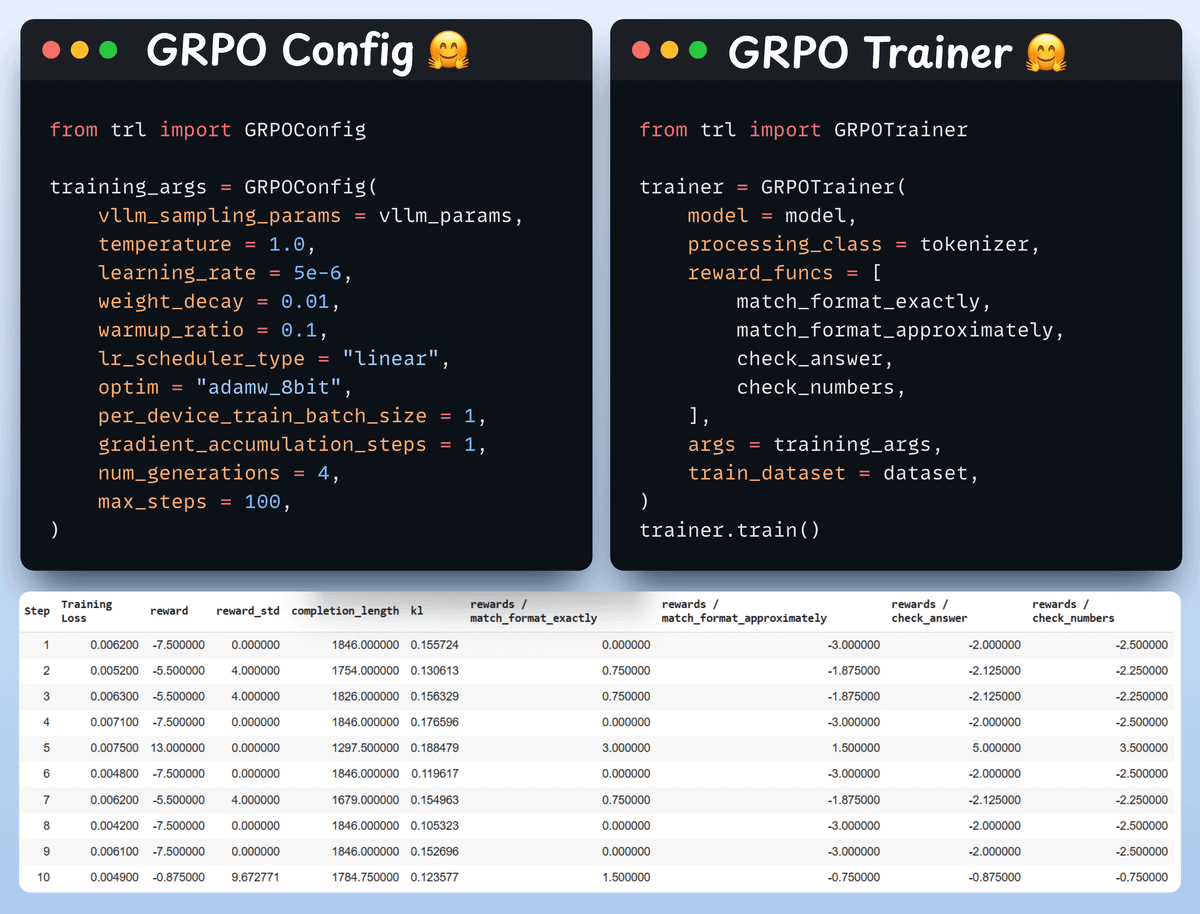
Comparison
Again, we can see how GRPO turned a base model into a reasoning powerhouse.
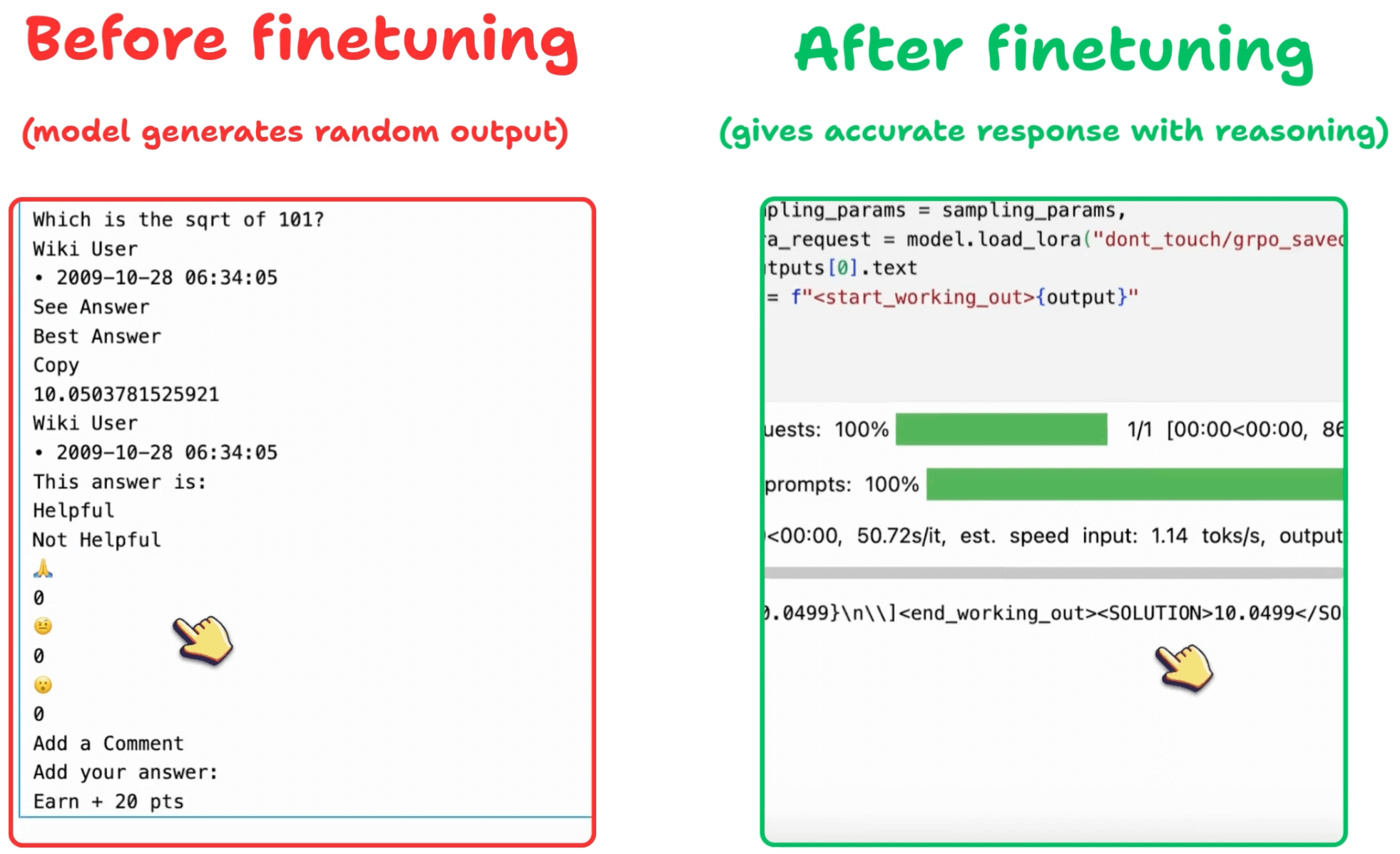
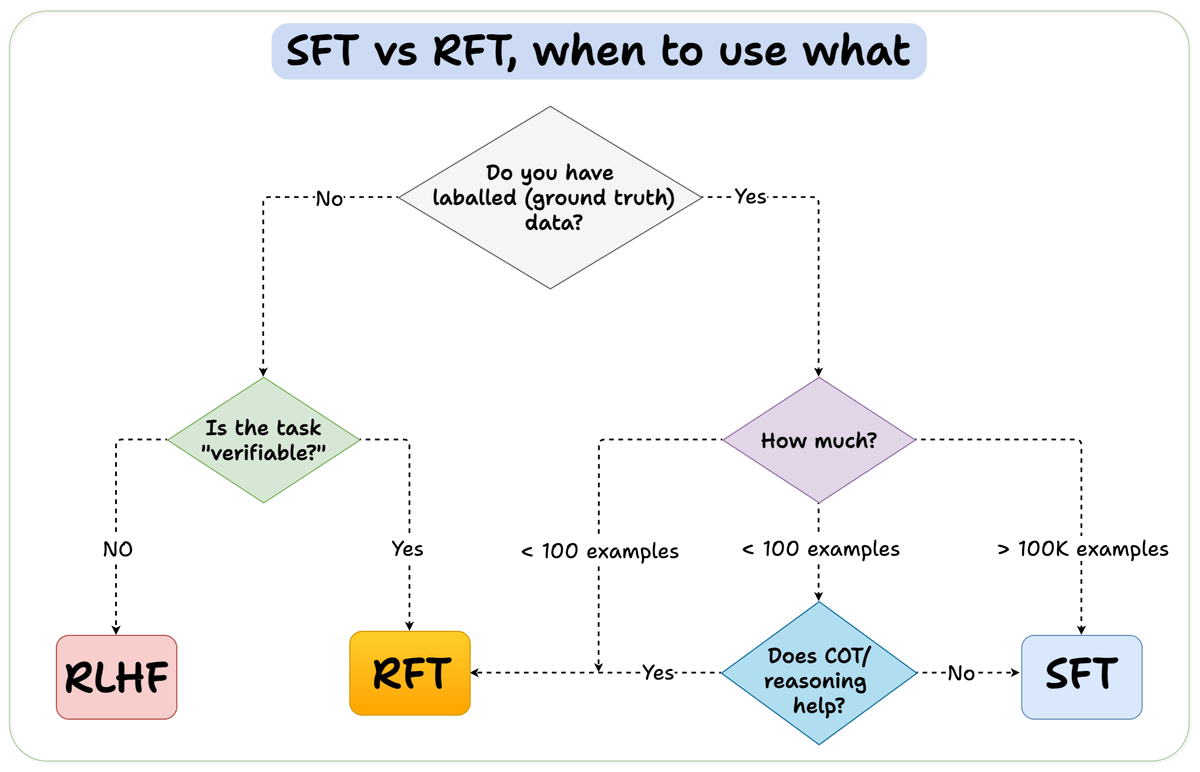
Before we conclude, let’s address an important question:
When should you use reinforcement fine-tuning (RFT) versus supervised fine-tuning (SFT)?
We created this diagram to provide an answer:
Finally, we'll leave you with an overview of the GRPO process.
Let us know what other techniques you have used for fine-tuning LLMs.
The code is available here: Build a reasoning LLM from scratch using GRPO. You can run it without any installations by reproducing our environment below:
Thanks for reading!
