

A VectorDB built for scale (open-source)!

Milvus is designed to handle vector search at scale.
It can scale horizontally to process tens of thousands of concurrent queries across billions of vectors.
Key features:
Multimodal data storage.
Real-time inserts to keep data fresh.
Fully distributed, k8s native architecture.
Fast search using hardware accelerators.
Hybrid search (BM25, SPLADE, BGE-M3).
Secure by default with TLS & RBAC.
GitHub repo → (don’t forget to star)
Building a Context Engineering Workflow
A few days back, we discussed covering a demo on context engineering.
Today, we'll build a multi-agent research assistant using context engineering principles.
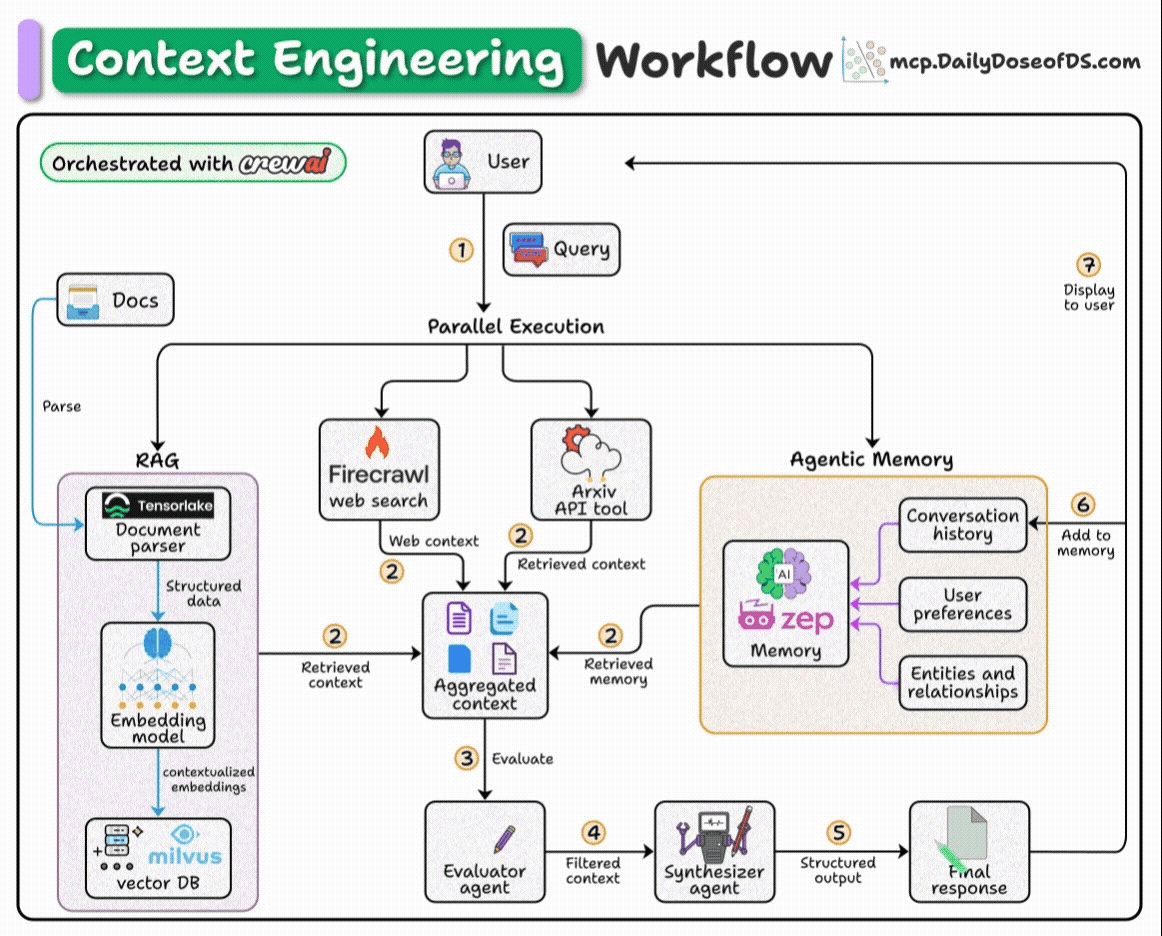
This Agent will gather its context across 4 sources: Documents, Memory, Web search, and Arxiv.
Here’s our workflow:
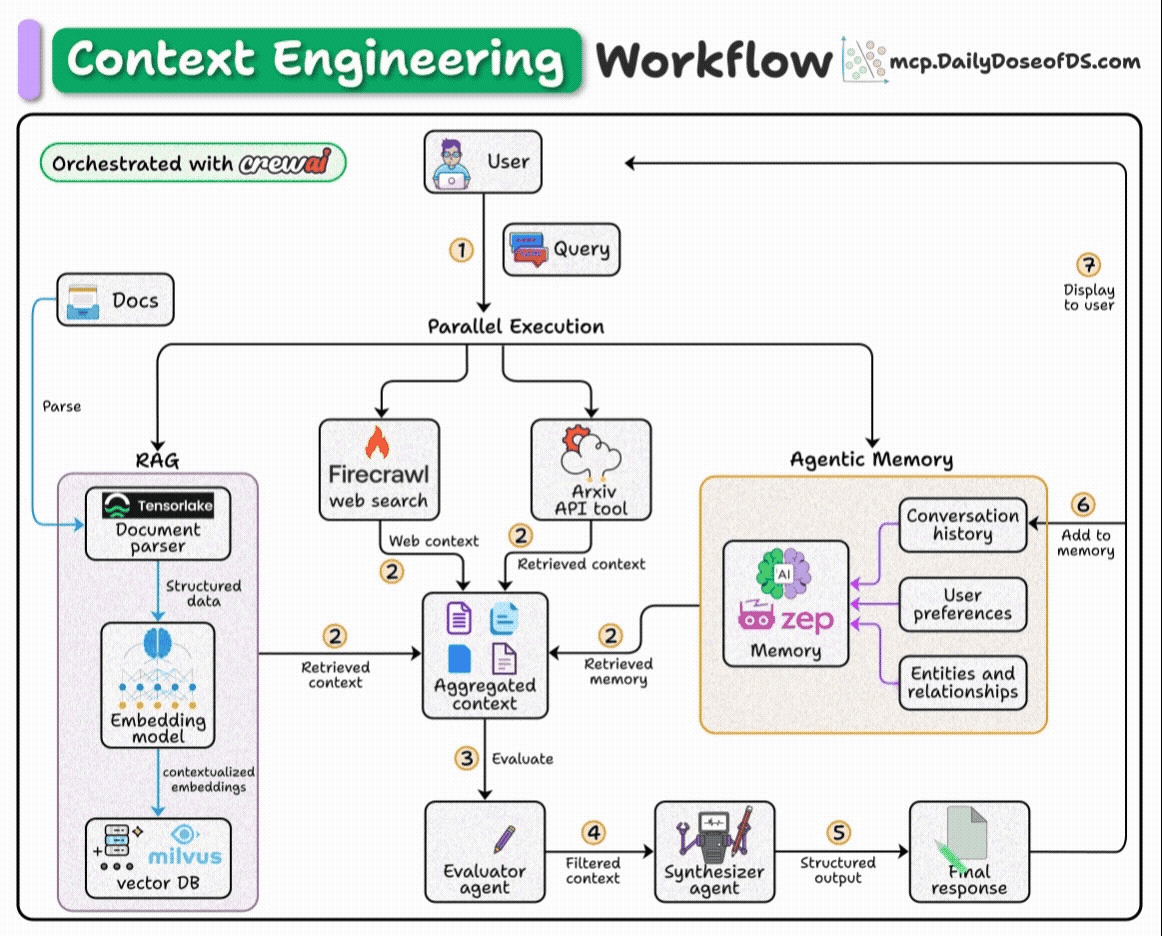
User submits query.
Fetch context from docs, web, arxiv API, and memory.
Pass the aggregated context to an agent for filtering.
Pass the filtered context to another agent to generate a response.
Save the final response to memory.
Tech stack:
Tensorlake to get RAG-ready data from complex docs
CrewAI for orchestration
Let's go!
First, what is context engineering (CE)?
LLMs aren’t mind readers. They can only work with what you give them.
Prompt engineering primarily focuses on “magic words” with an expectation of getting a better response.
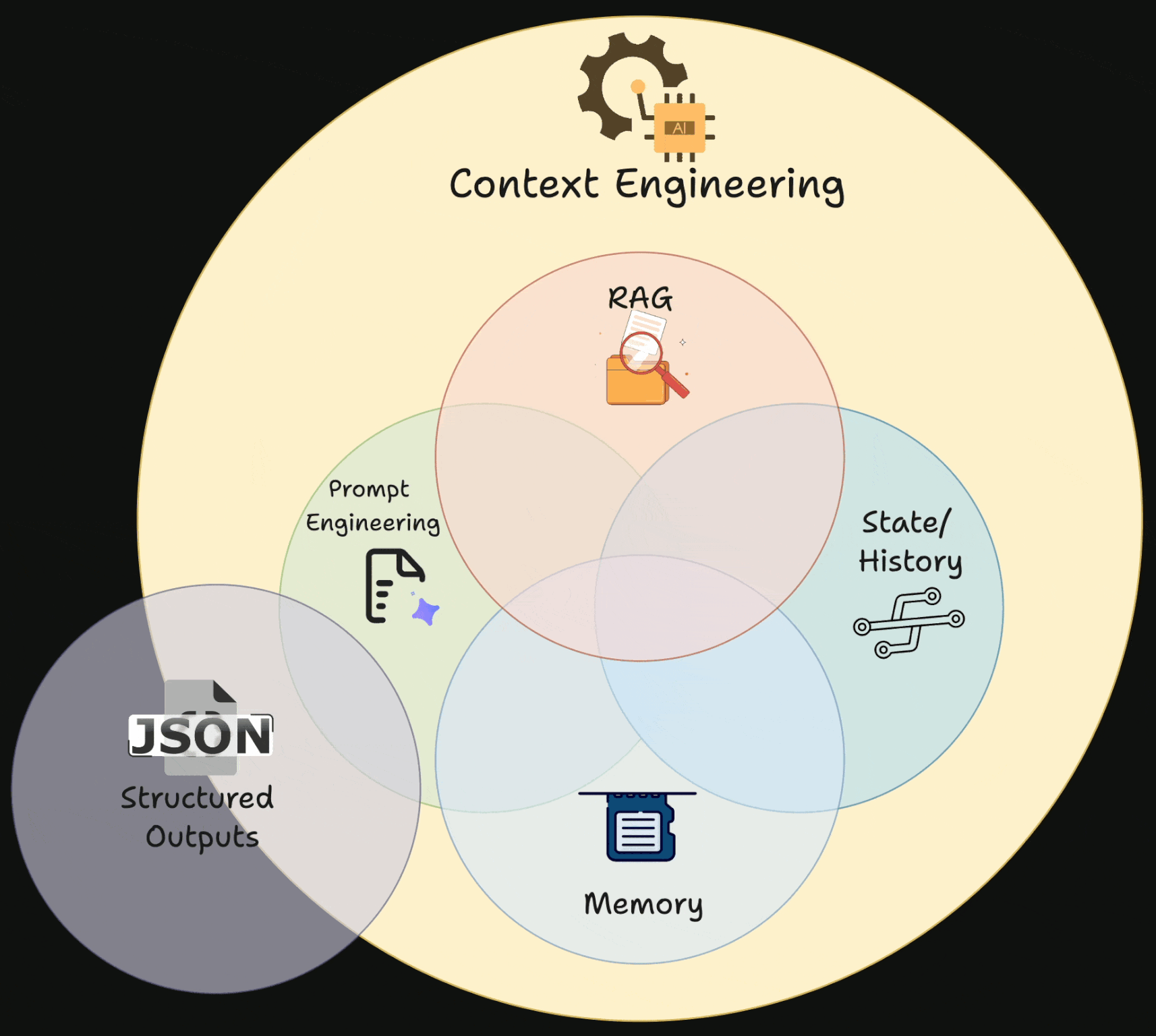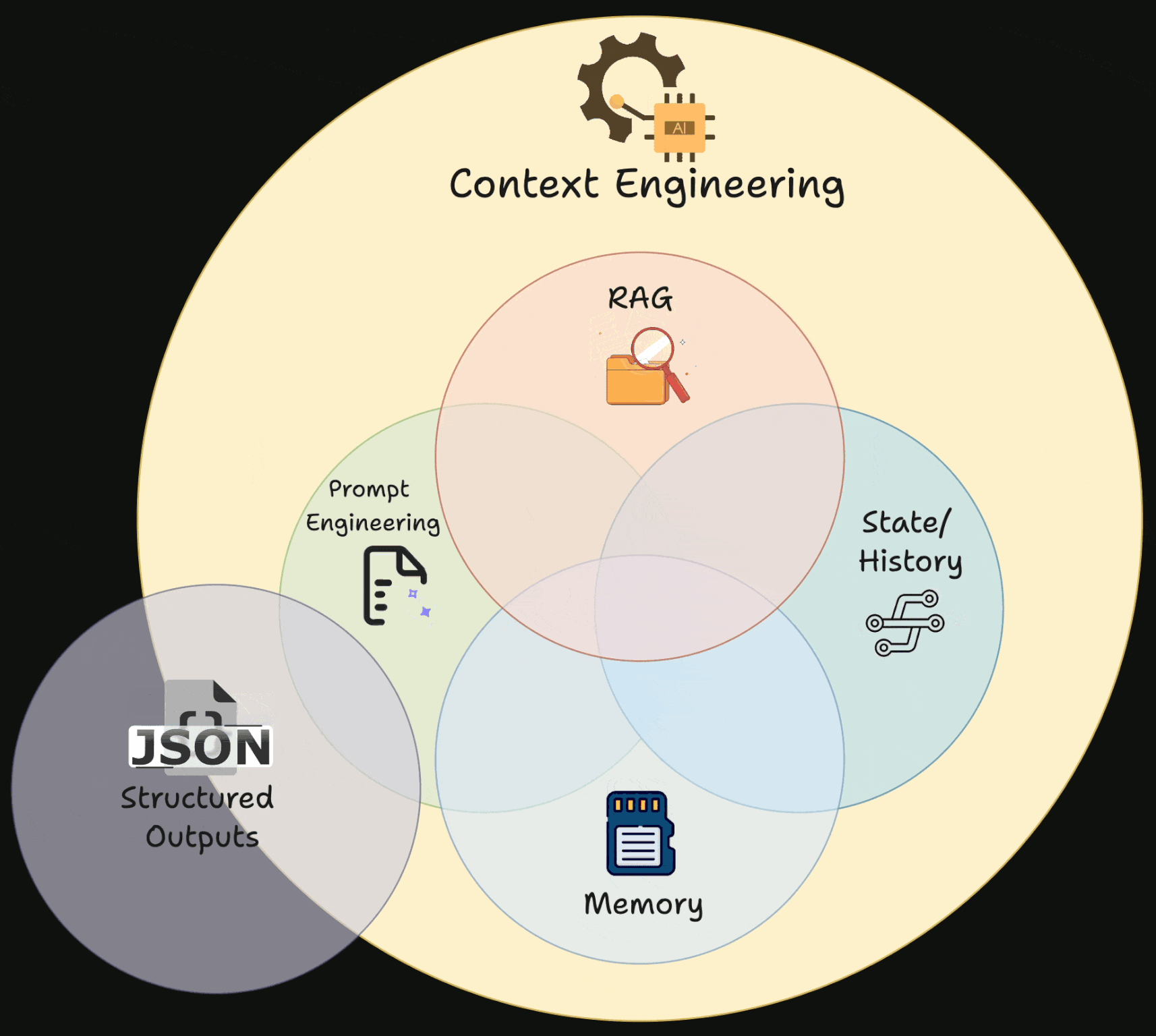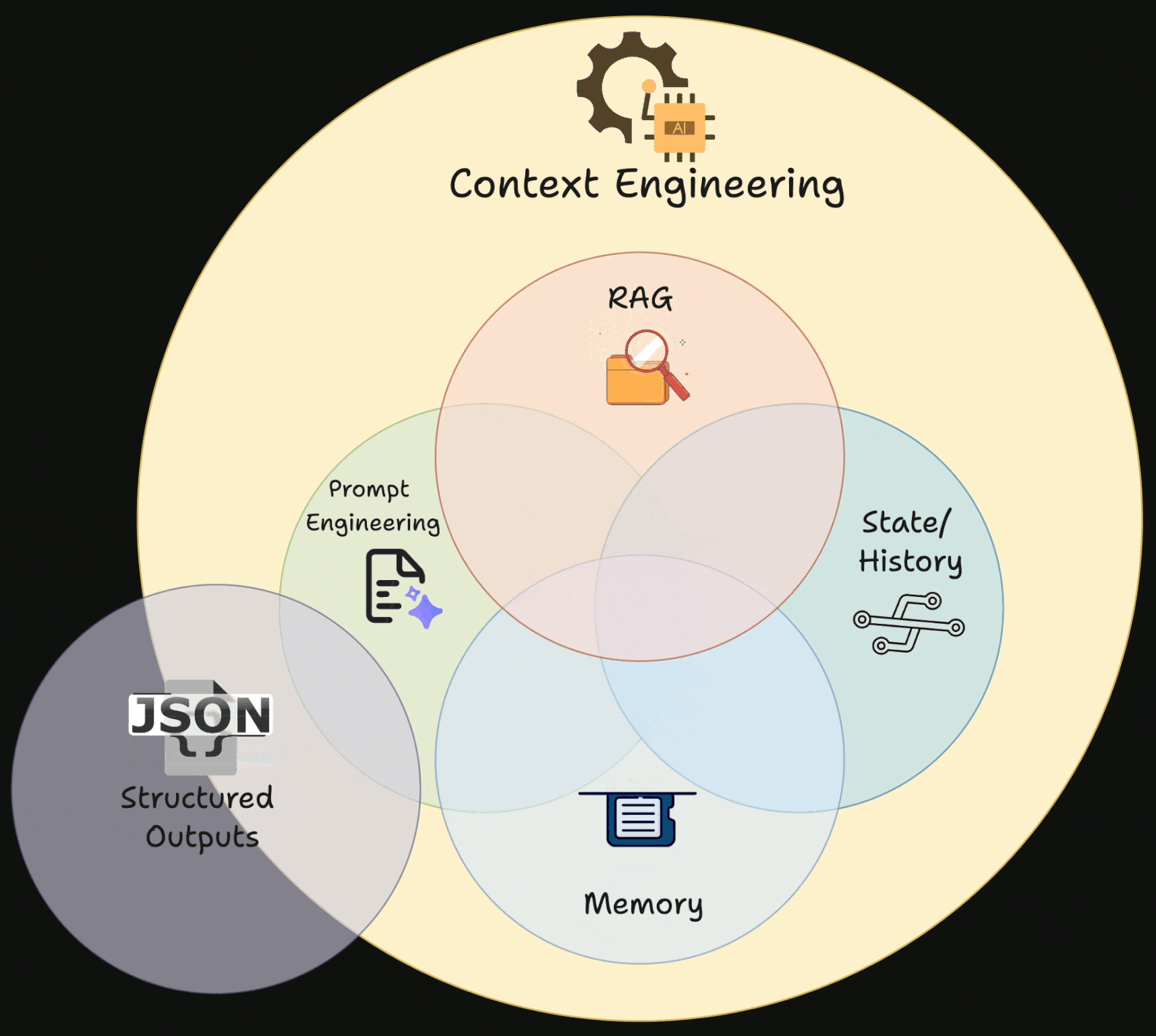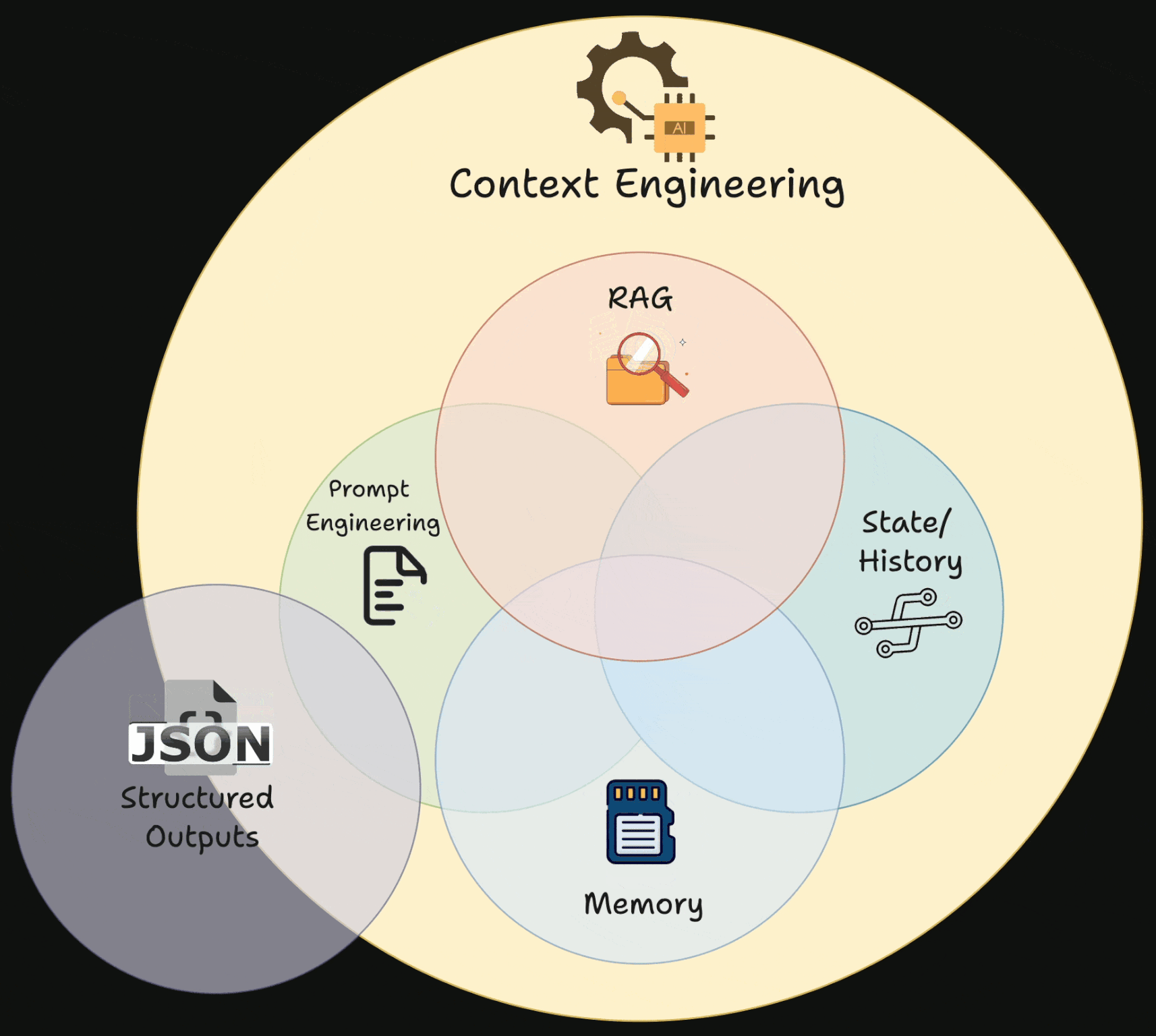
CE involves creating dynamic systems that offer:
The right info
The right tools
In the right format
This ensures the LLM can effectively complete the task.
Crew flow
We'll follow a top-down approach to understand the code.
Here's an outline of what our flow looks like:
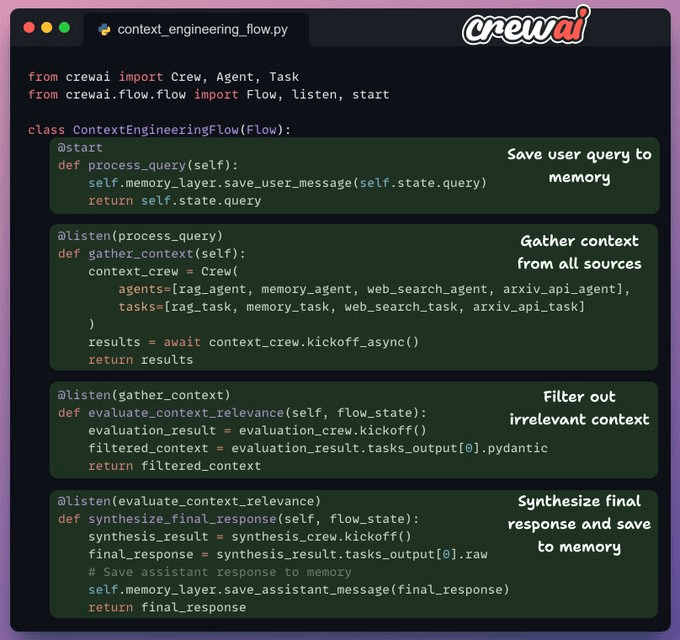
Note that this is one of many blueprints to implement a context engineering workflow. Your pipeline will likely vary based on the use case.
Prepare data for RAG
We use Tensorlake to convert the document into RAG-ready markdown chunks for each section.
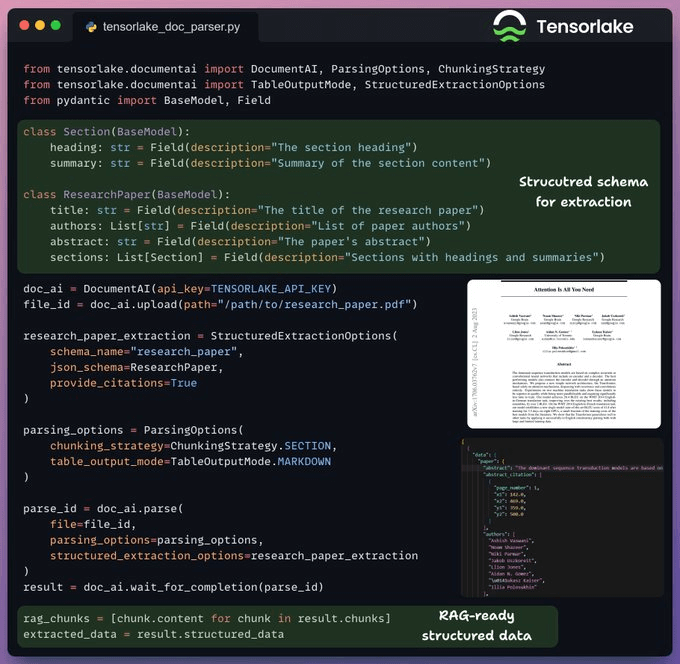
The extracted data can be directly embedded and stored in a vector DB without further processing.
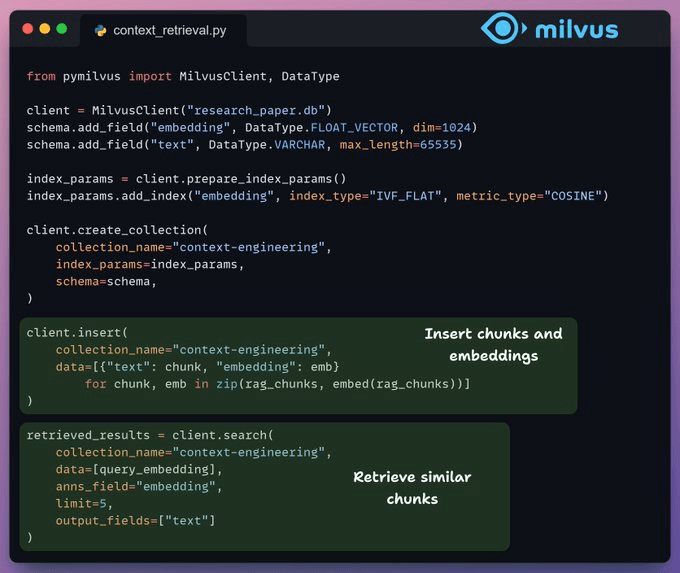
Indexing and retrieval
Now that we have RAG-ready chunks along with the metadata, it's time to store them in a self-hosted Milvus vector database.
We retrieve the top-k most similar chunks to our query:
Build memory layer
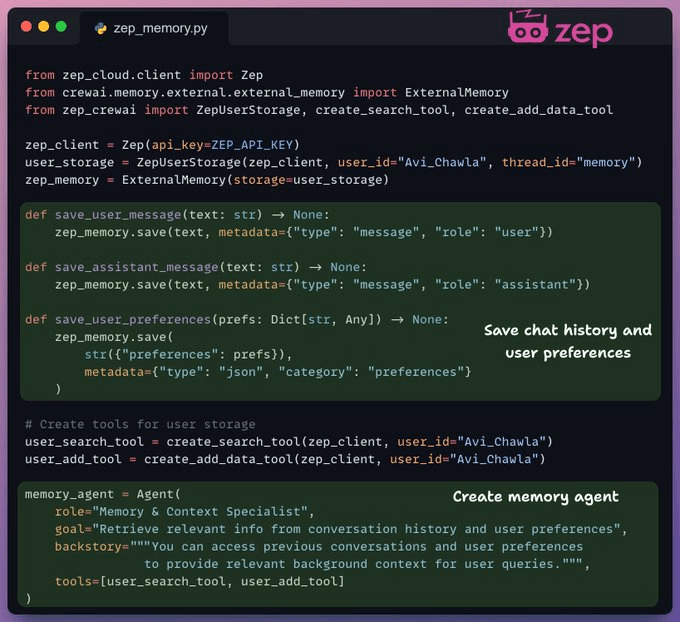
Zep acts as the core memory layer of our workflow. It creates temporal knowledge graphs to organize and retrieve context for each interaction.
We use it to store and retrieve context from chat history and user data.
Firecrawl web search
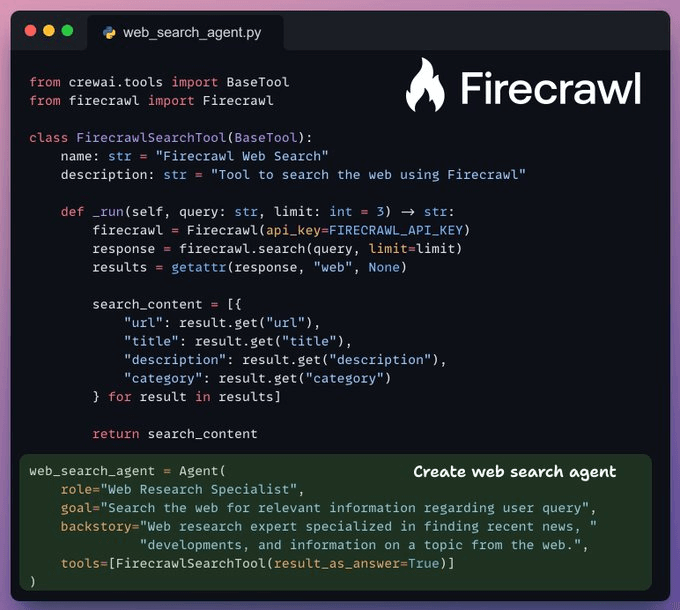
We use Firecrawl web search to fetch the latest news and developments related to the user query.
Firecrawl's v2 endpoint provides 10x faster scraping, semantic crawling, and image search, turning any website into LLM-ready data.
ArXiv API search
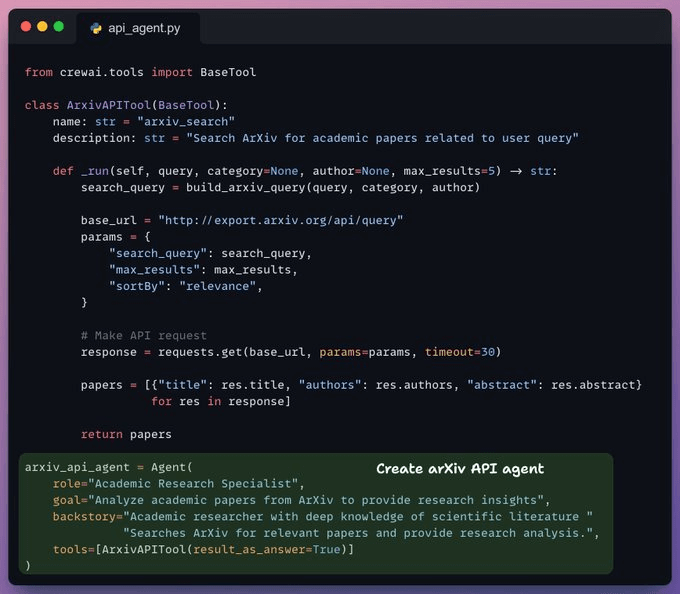
To further support research queries, we use the arXiv API to retrieve relevant results from their data repository based on the user query.
Filter context
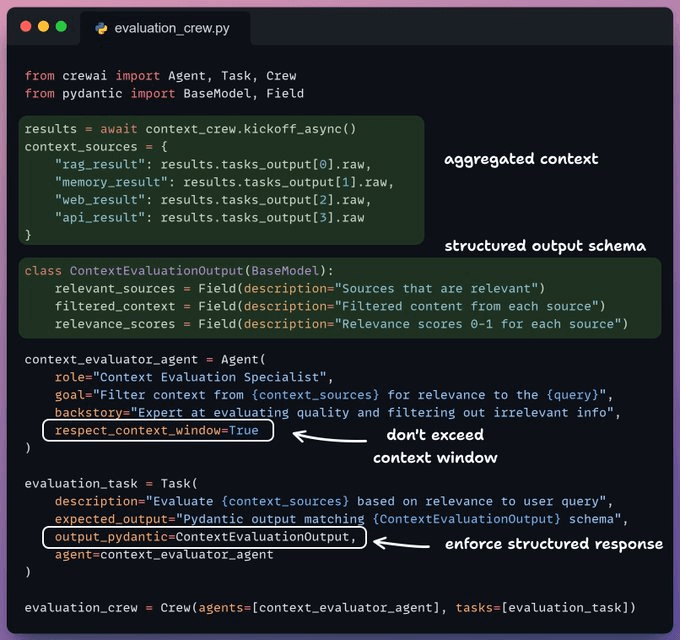
Now, we pass our combined context to the context evaluation agent that filters out irrelevant context.
This filtered context is then passed to the synthesizer agent that generates the final response.
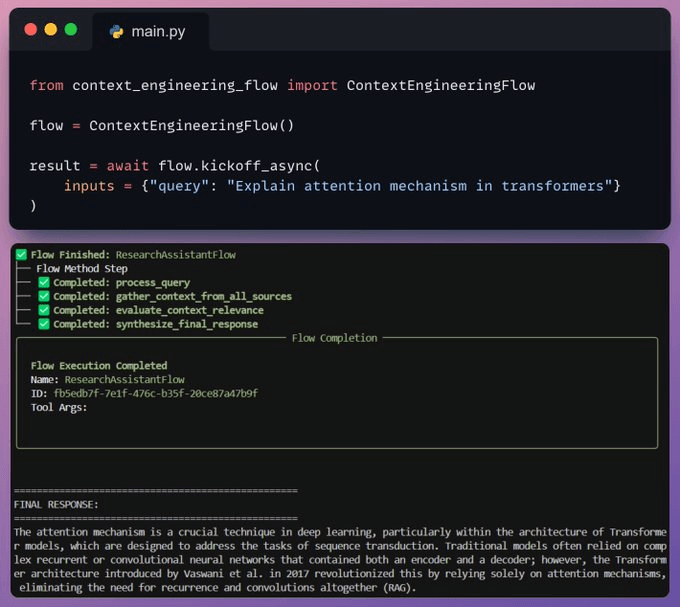
Kick off the workflow
Finally, we kick off our context engineering workflow with a query.
Based on the query, we notice that the RAG tool, powered by Tensorlake, was the most relevant source for the LLM to generate a response.
We also translated this workflow into a streamlit app that:
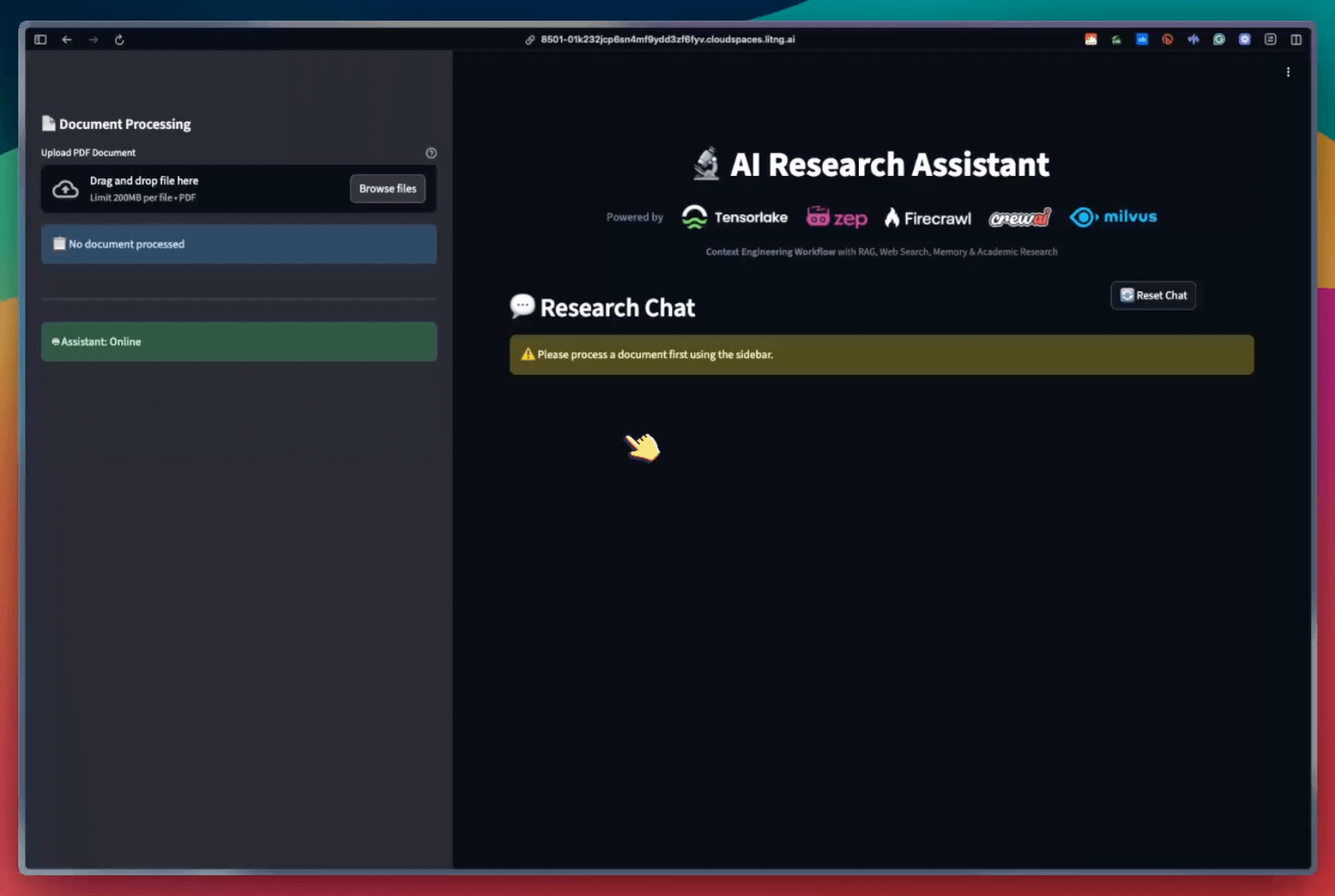
Provides citations with links and metadata.
Provides insights into relevant sources.
That said, the workflow explained in the thread is one of the many blueprints. Your implementation can vary.
In the project, we used:
Tensorlake:
It lets you transform any unstructured doc into AI-ready data.
Zep:
It lets you build human-like memory for your Agents.
Firecrawl:
It lets you power LLM apps with clean data from the web.
Milvus:
It gives a high-performance vector DB for scalable vector search.
Thanks for reading!
