

Drag-and-drop UI to build AI agent workflows [open-source]!

Sim is a lightweight, user-friendly platform for building AI agent workflows in minutes.
Key features:
Real-time workflow execution
Connects with your favorite tools
Works with local models via Ollama
Intuitive drag-and-drop interface using ReactFlow
Multiple deployment options (NPM, Docker, Dev Containers)
Based on our testing, Sim is a better alternative to n8n with:
An intuitive interface
A much better copilot for faster builds
AI-native workflows for intelligent agents
GitHub repo → (don’t forget to star)
Building Efficient RAG Systems with Binary Quantization
Binary quantization is a simple yet effective technique that makes RAG up to 40x faster & 32x memory efficient!
Perplexity uses it in its search index
Google uses it in Vertex RAG engine
Azure uses it in its search pipeline
We did a demo on this recently but today, let's dive a bit more deeper by building a multi-agent legal assistant that can query 50M+ vectors in <30ms.
Tech stack:
Milvus to self-host vectorDB with BQ
Firecrawl for web search
CrewAI for orchestration
Ollama to serve GPT-OSS
First things first: What exactly is binary quantization?
In this video, we answer this question and provide a really nice analogy to explain why BQ works and how it makes your setup fast and memory efficient.
Here's an overview of how the system works:
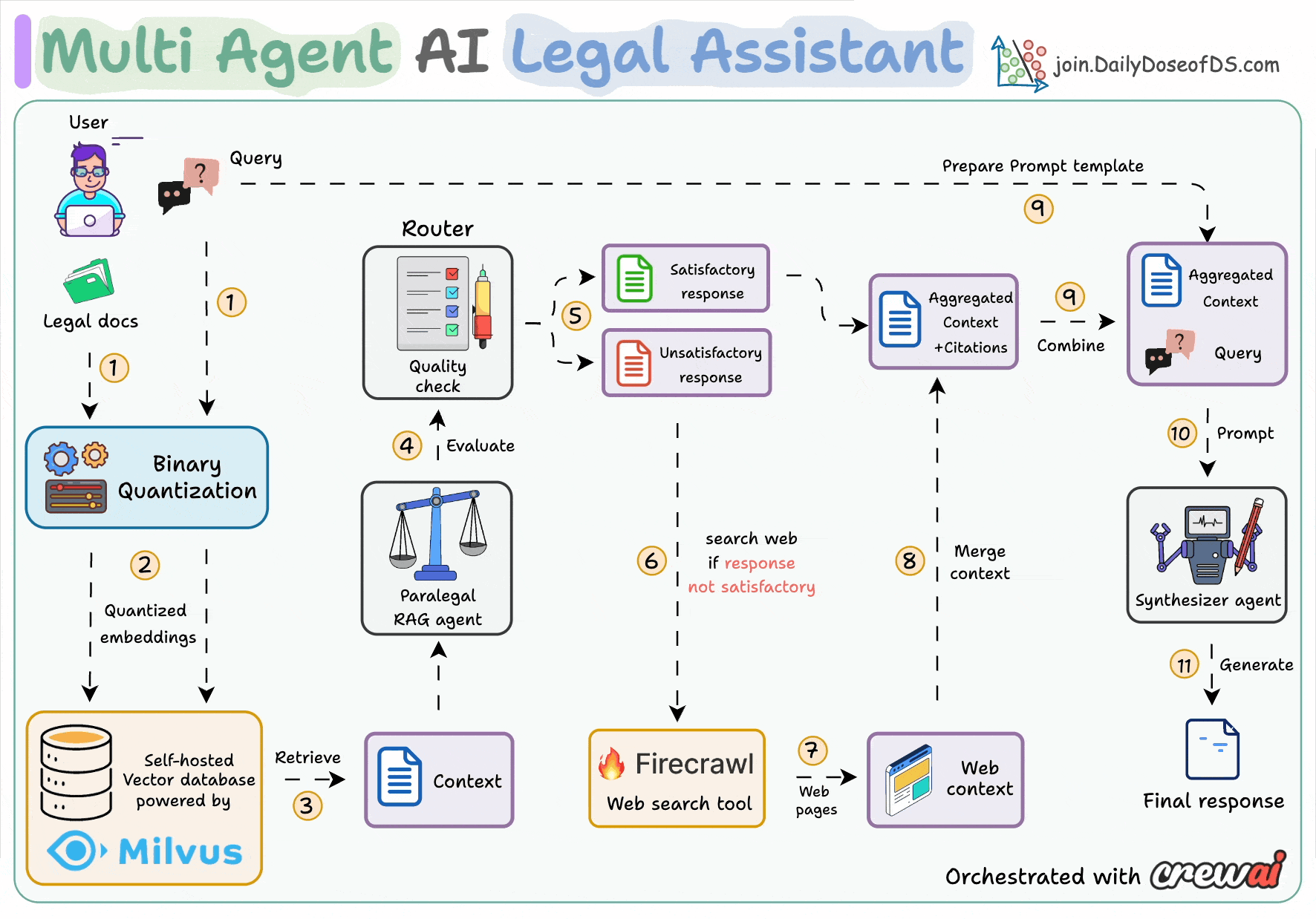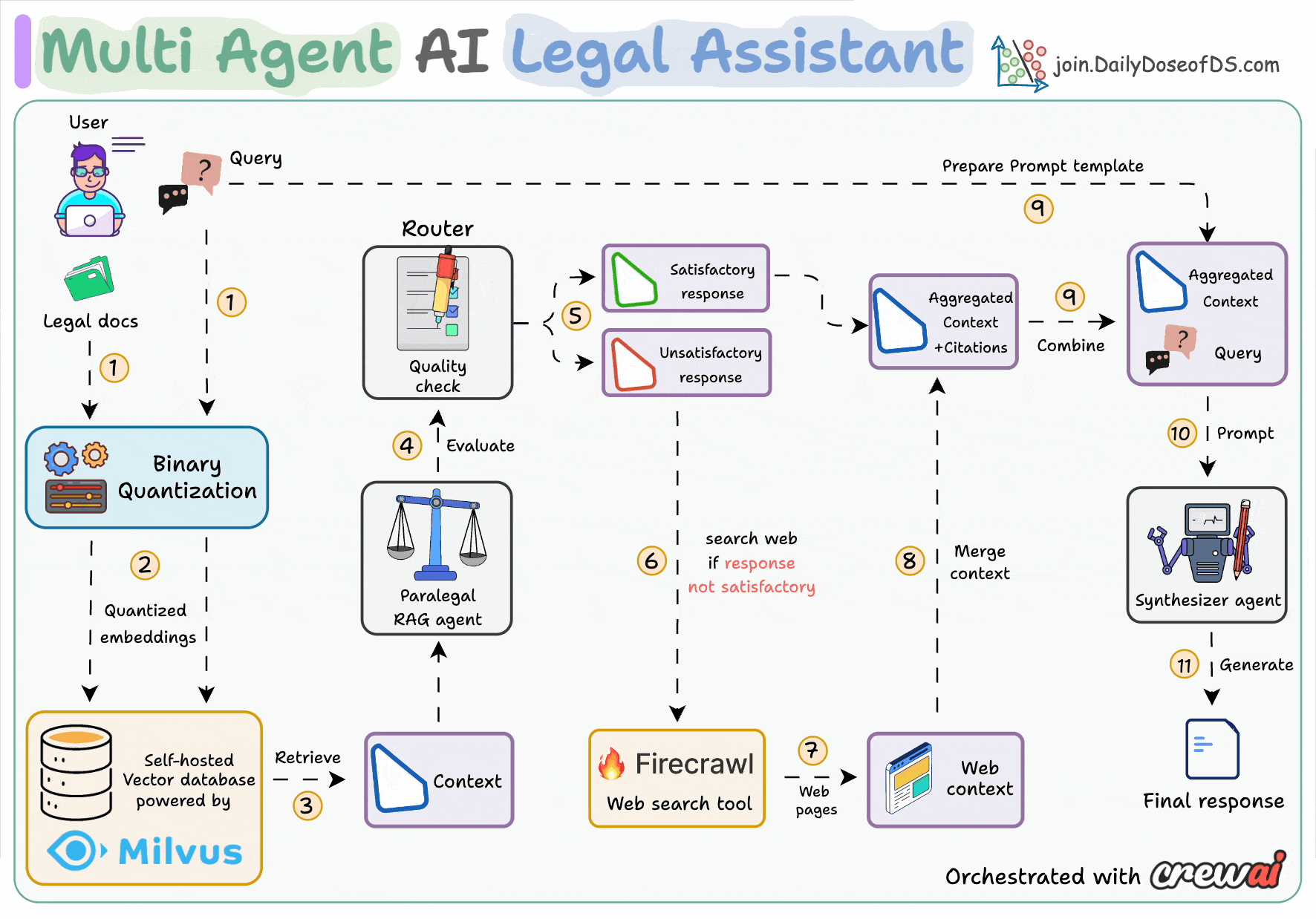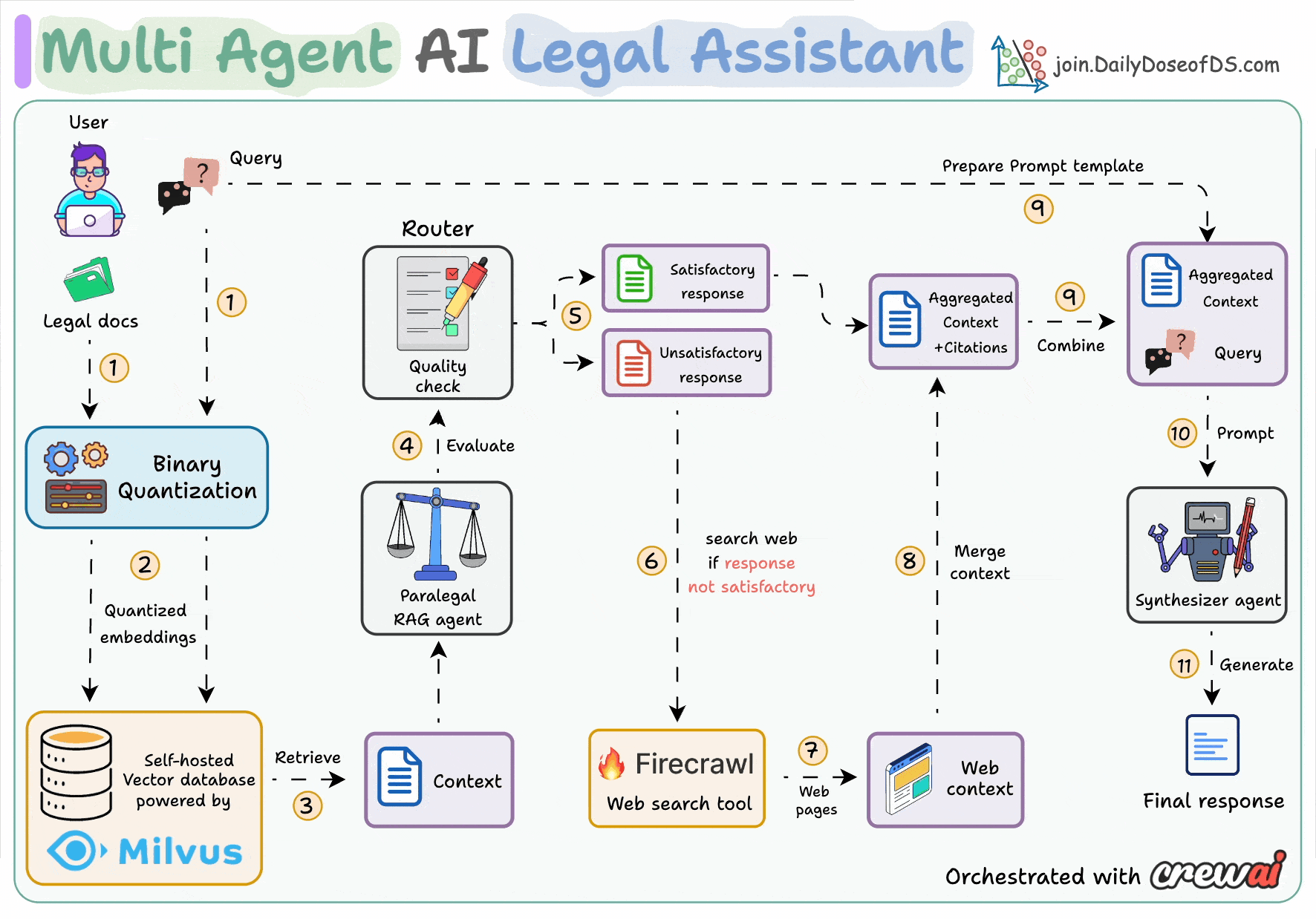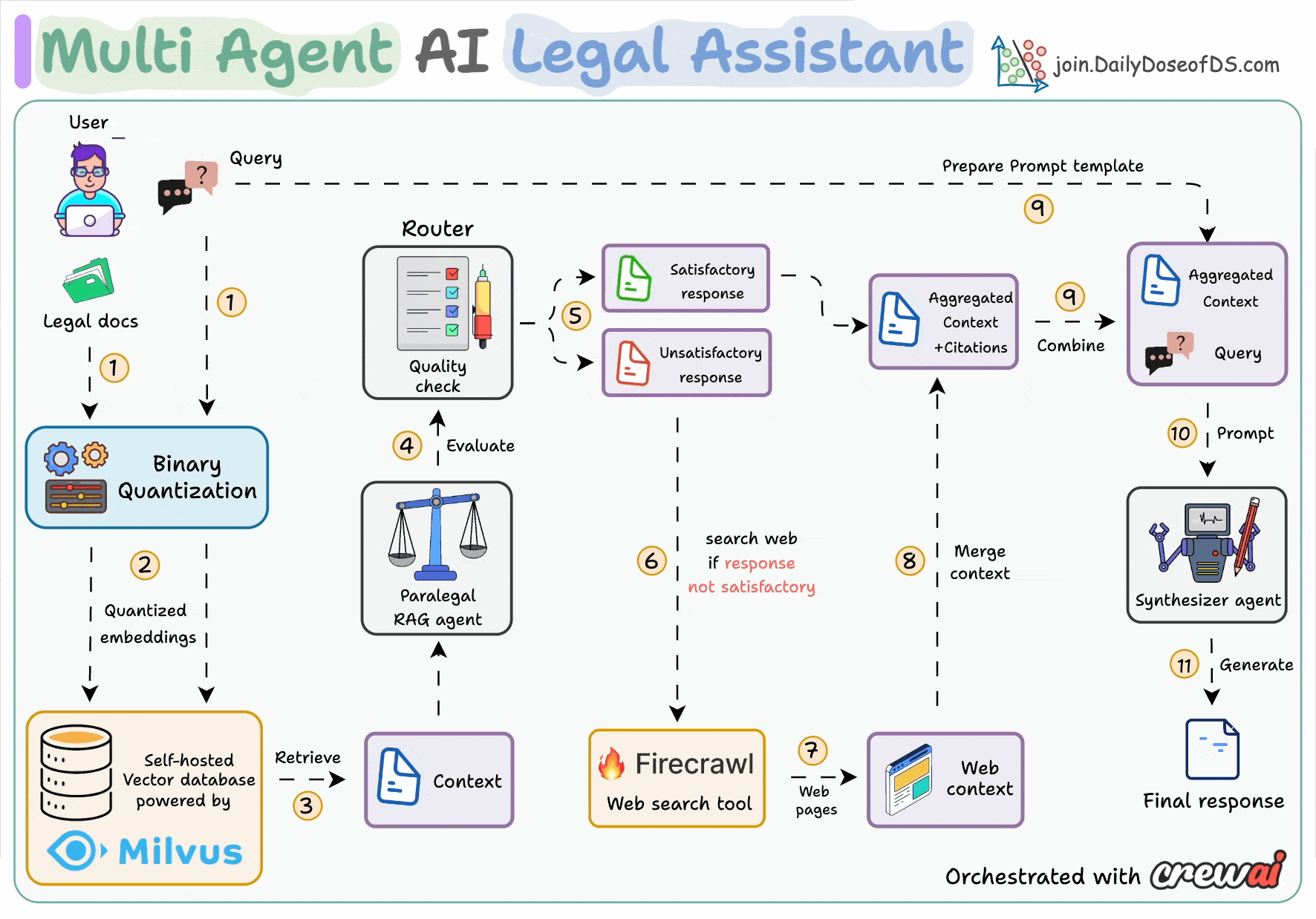
First, do RAG with citations (BQ powered)
Evaluate the quality of the generated response
Performs a web search if needed
Aggregate the entire context
Provide the final answer
You can find the code in this Studio →
You can run it without any installations by reproducing our environment below:

Now, let's jump into understanding the code for our workflow!
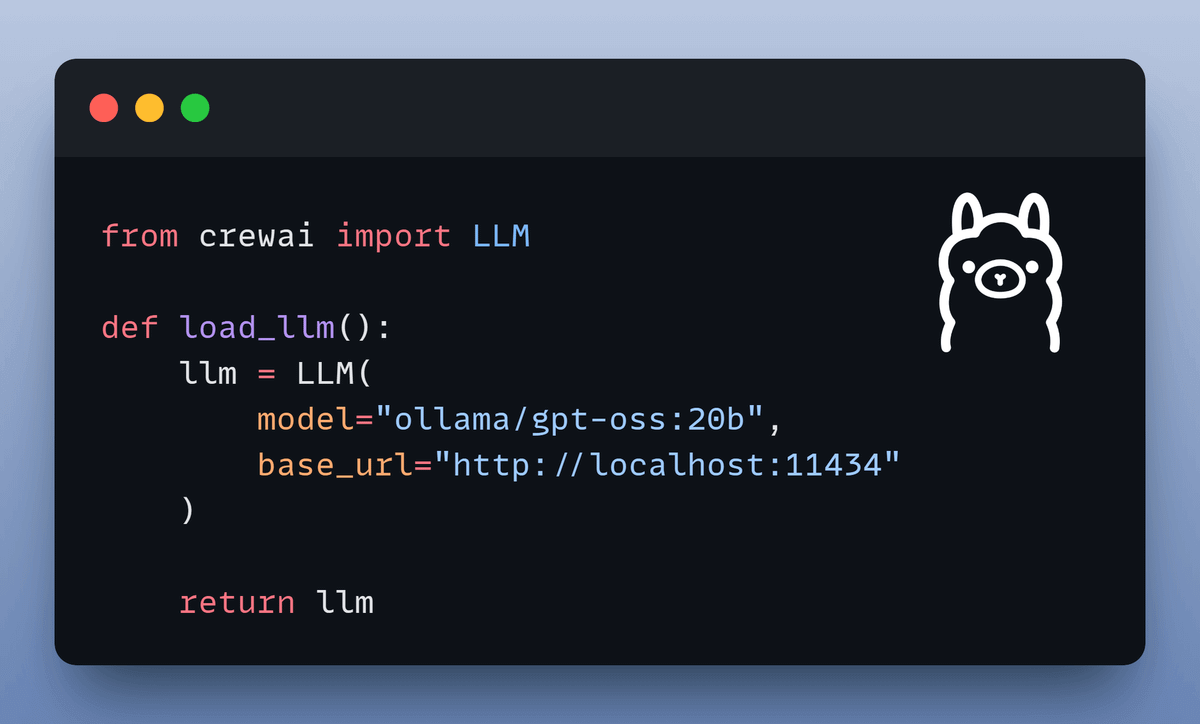
Setup LLM
Let's initialize our local setup by defining our LLM. We will use gpt-oss-20b and serve it locally via Ollama.
From here, we'll follow a top-down approach to understand the code.
Our workflow does 5 things:
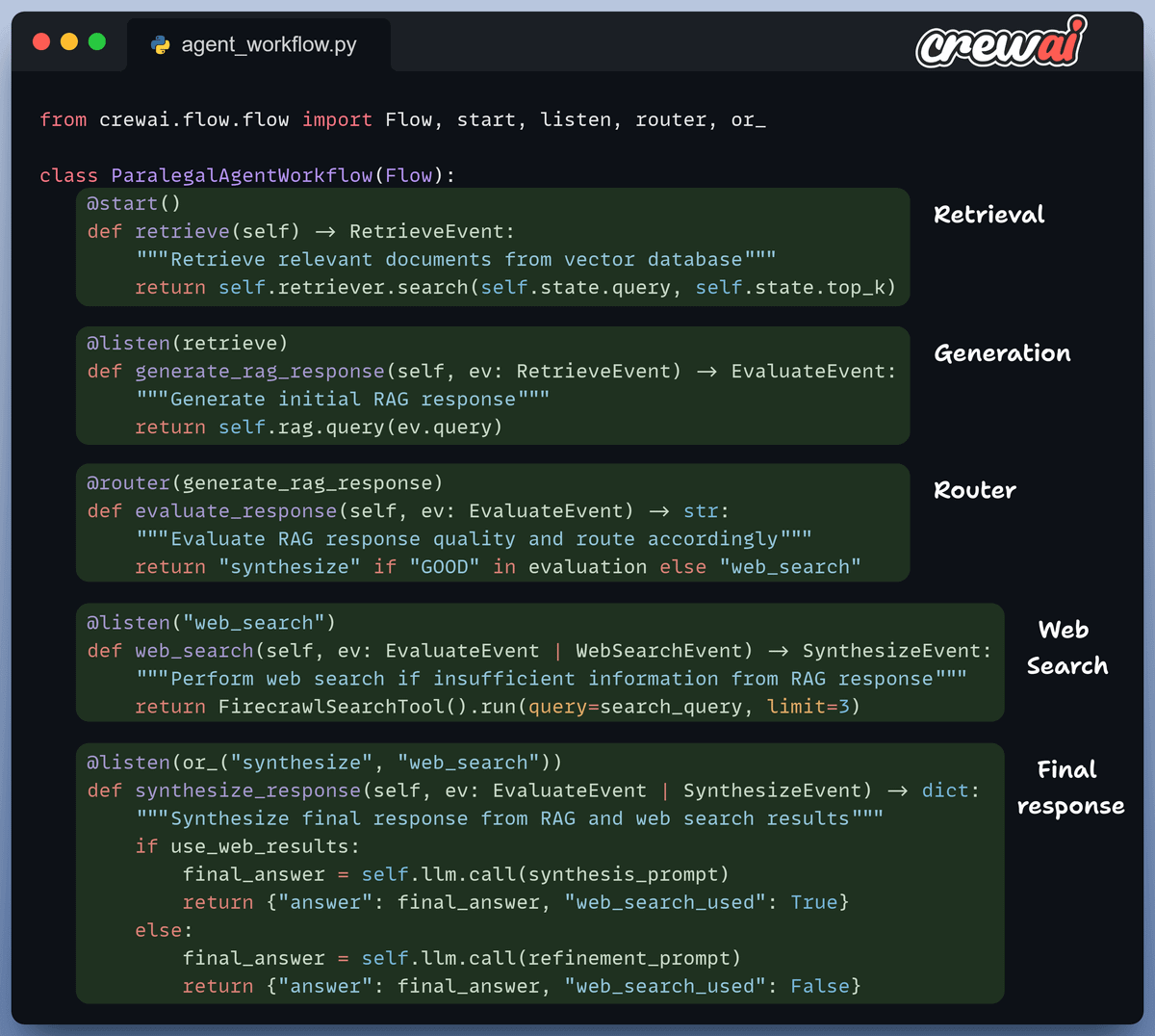
Takes user query & retrieves context
Generates initial response
Router evaluates response quality
Routes to web search if RAG fails
Synthesizes final response
Now, let's break down our flow and analyze each component one by one.
Vector Indexing
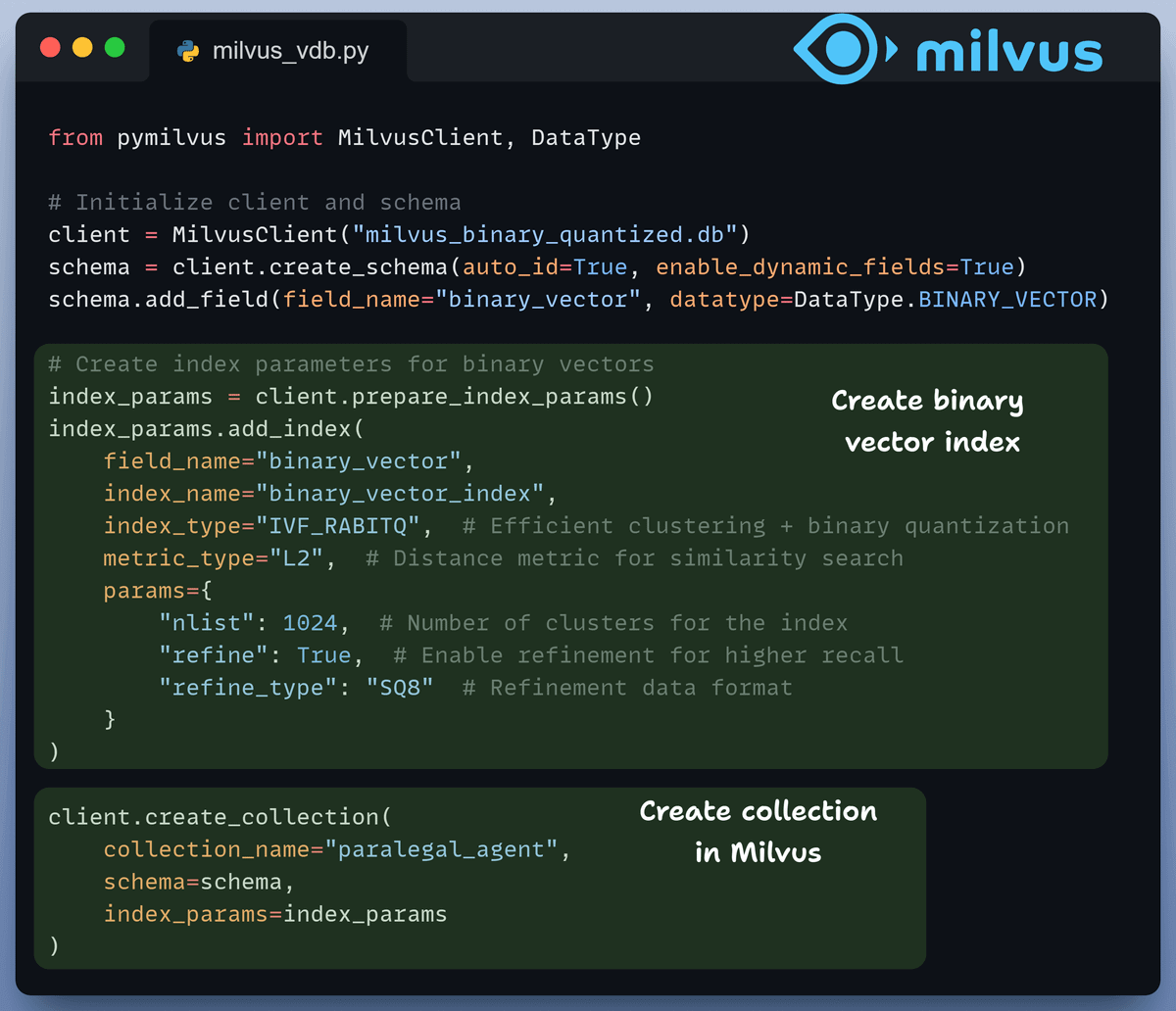
We generate embeddings for our docs and index them in a Milvus vector database for efficient retrieval.
This results in a 32x reduction in memory and storage costs + faster search:
Retrieval
In the retrieval stage, we:

Initialize search with a binary query.
Specify the number of clusters to search.
Apply reranking to enhance retrieval accuracy.
Retrieve the top 5 most similar chunks.
Add retrieved chunks to the context.
Generation
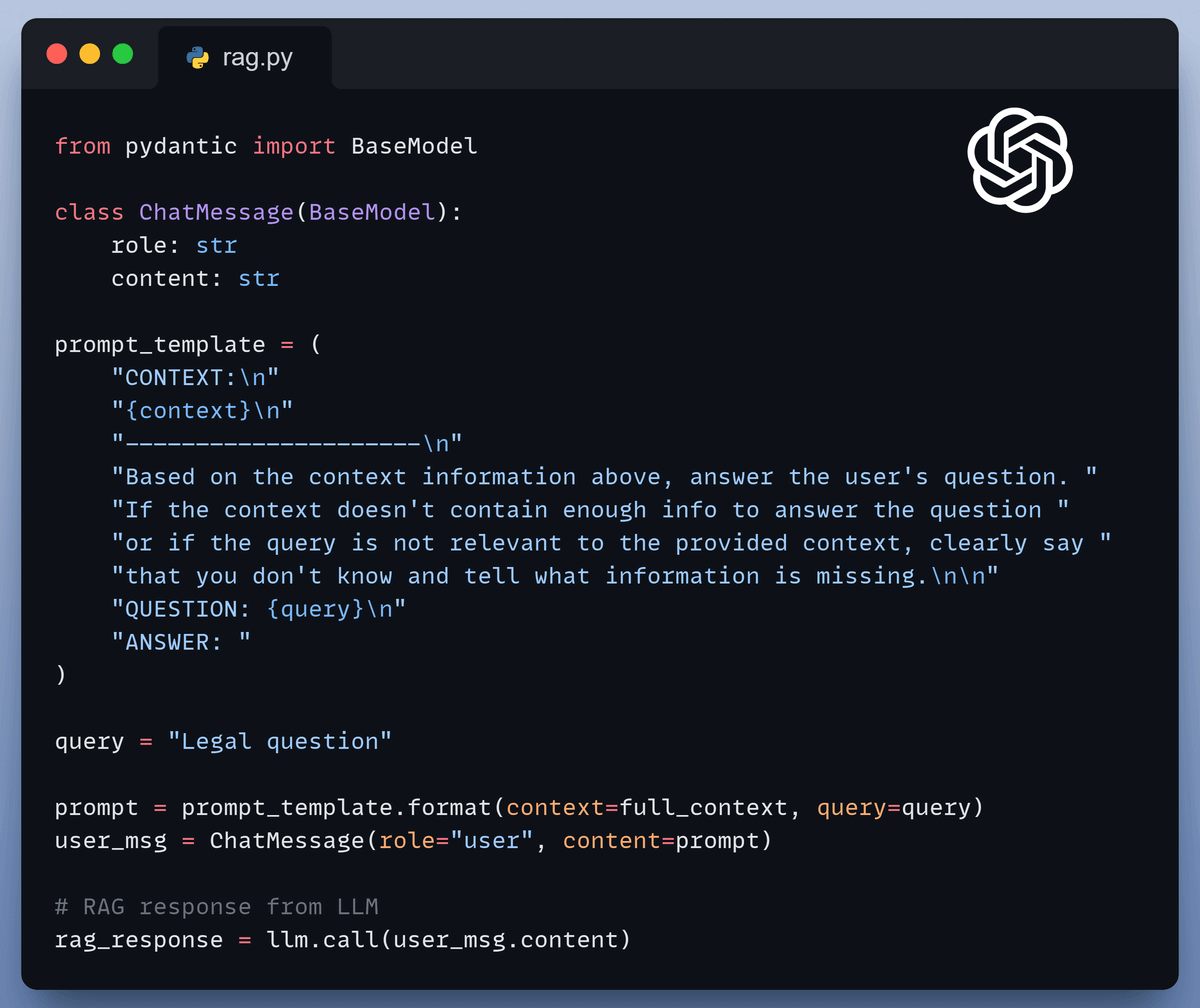
Finally, we kick off our RAG pipeline with both the query and the retrieved context in our prompt and pass it to the LLM.
This generates our initial response.
Router
Based on our prompt instructions, the router evaluates the generated response and intelligently routes:
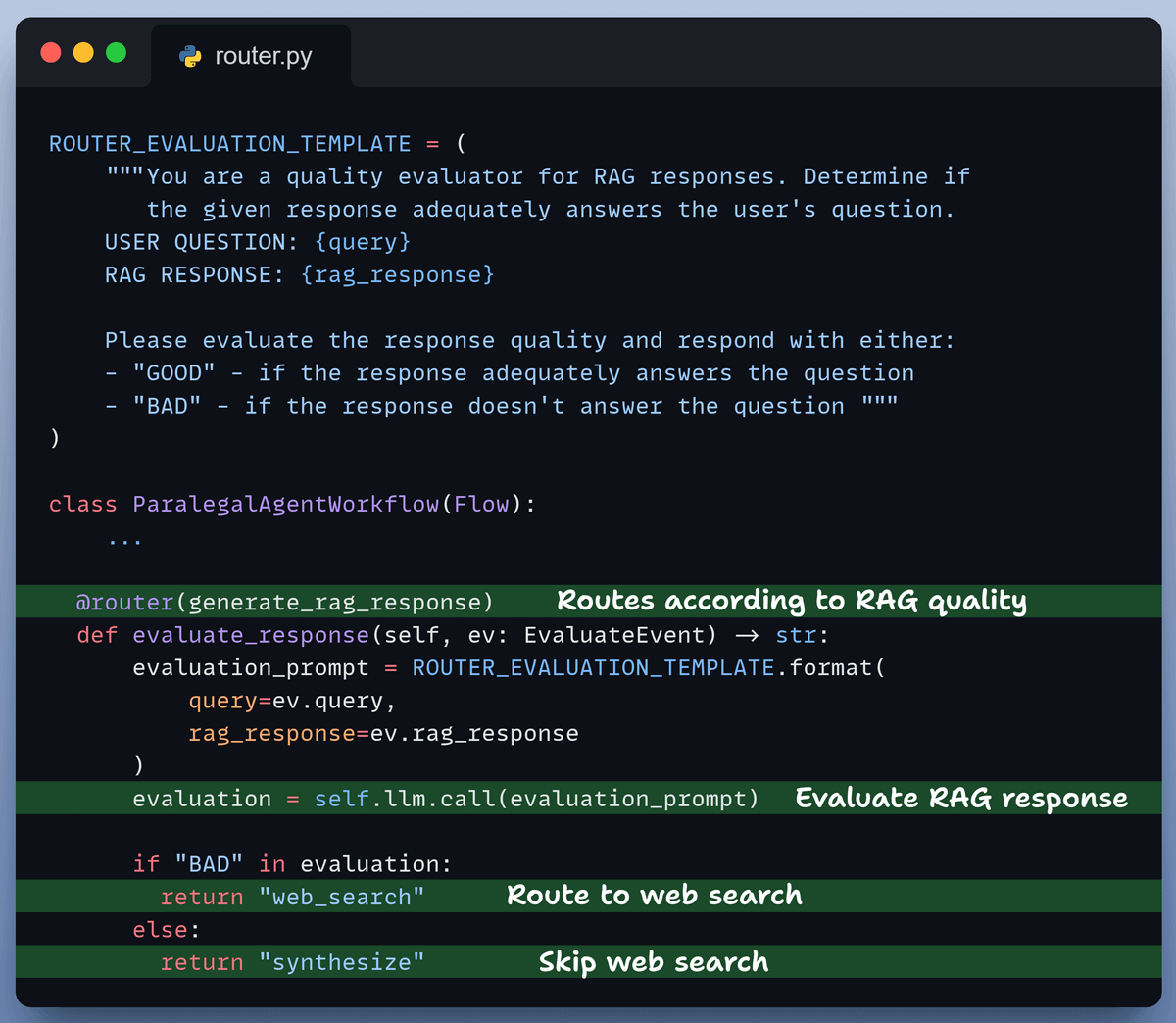
to perform a web search in case RAG response is not satisfactory
to skip web search and refine the RAG response otherwise
Firecrawl Web Search
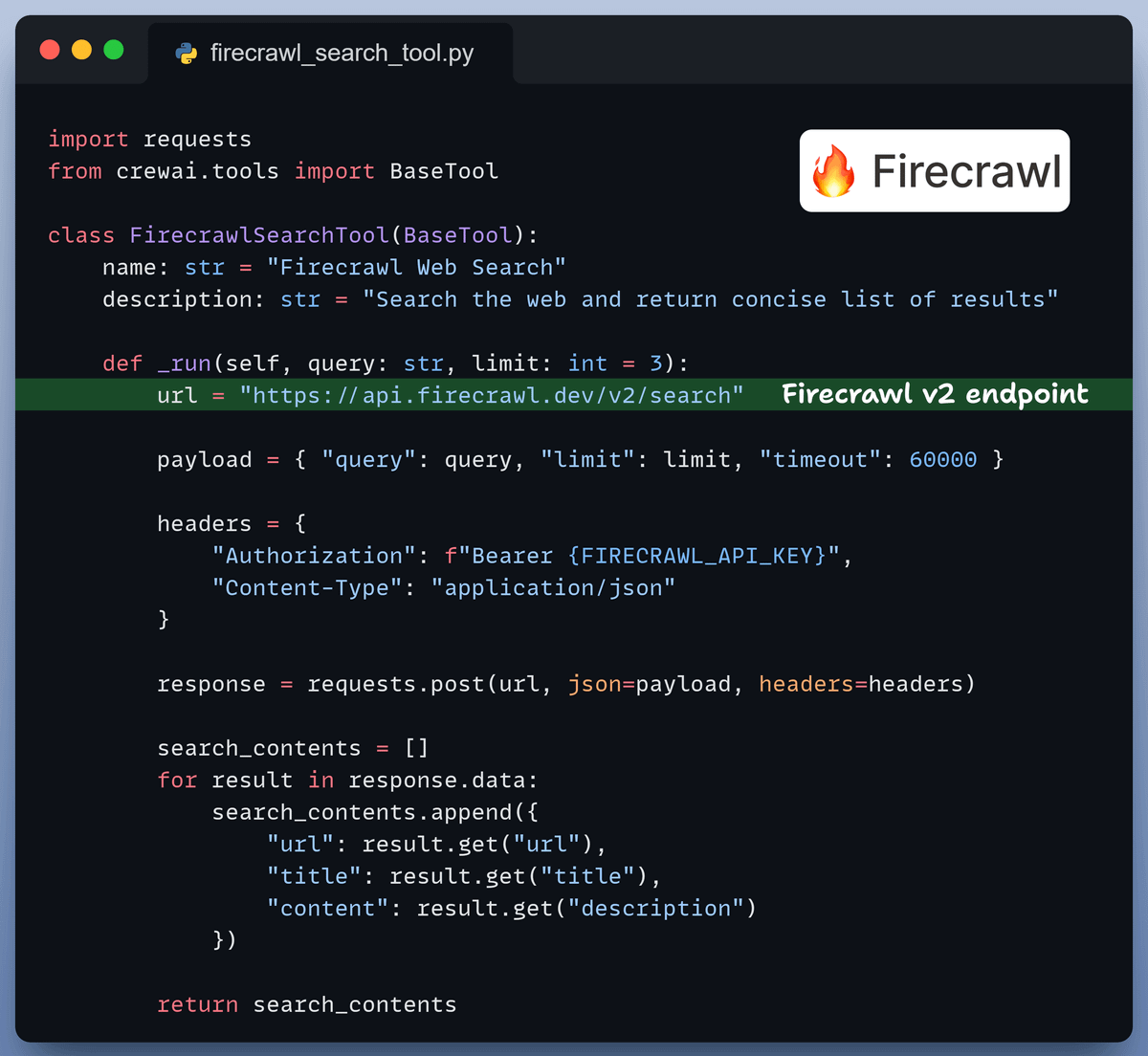
We enhance our agentic workflow with Firecrawl's web search capabilities to retrieve up-to-date and the latest information from the web.
This enables our agent to get accurate information on a topic even if it is not present in our docs.
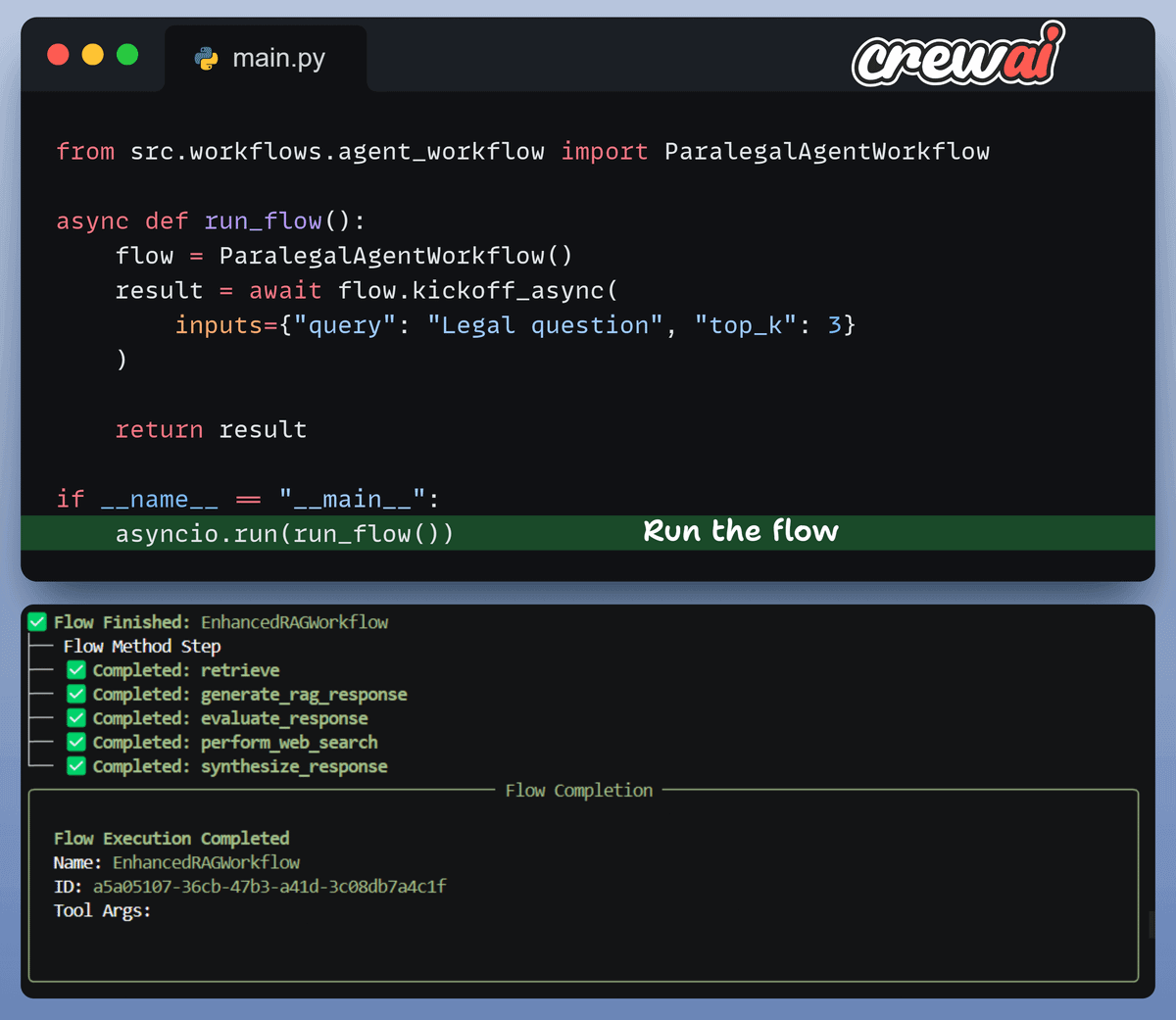
Kickoff the workflow
Finally, when we have everything ready, we kickoff our workflow.
Finally, we wrap everything in a Streamlit interface to improve accessibility.
This gives us our legal RAG assistant that
is 40x faster and 32x more memory efficient than normal setups.
provides citations for all the answers.
has web search capabilities.
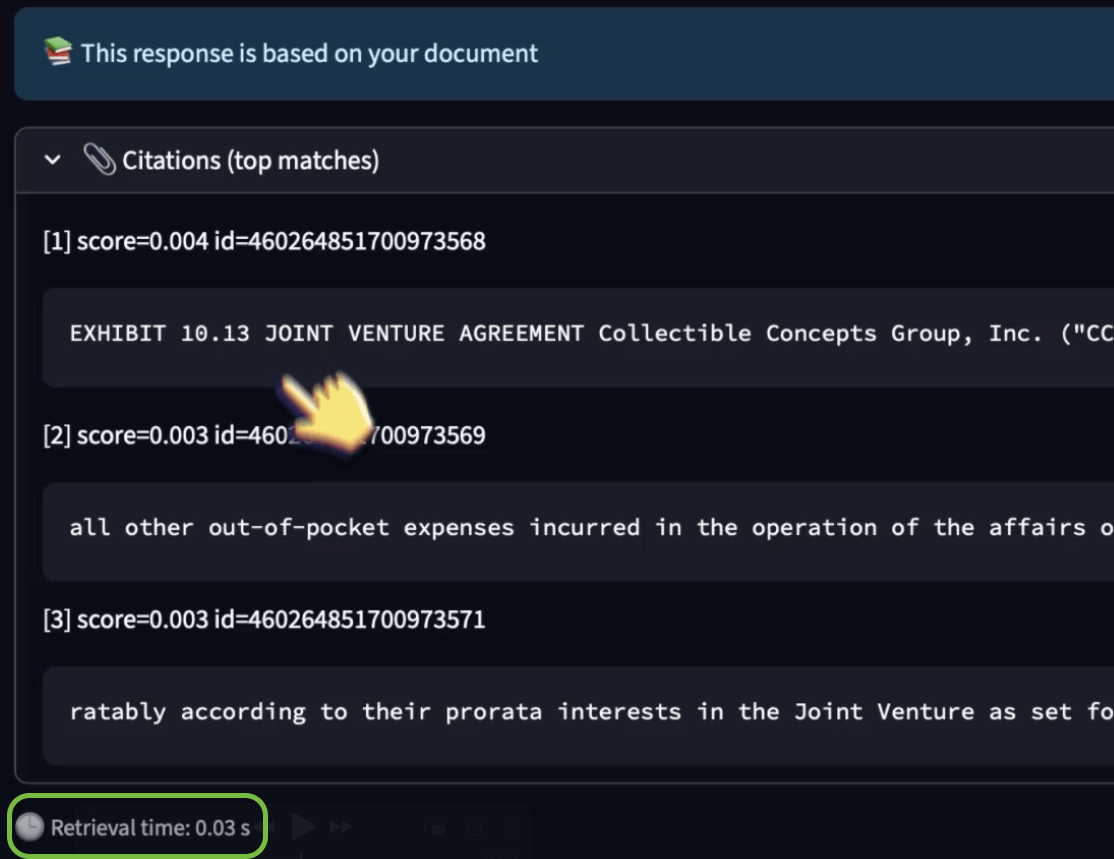
Below, we asked: “Which firm partnered with Collectible Concepts Group, and what were the terms?” and generated the correct response while querying 50M+ vectors in just 0.03 seconds:
Some more interactions are shown in the video attached at the top.
You can find the code in this Studio →
You can run it without any installations by reproducing our environment below:
Thanks for reading!
