

Real-world RAG applications have millions, if not billions, of vectors.
Thus, it is essential to be optimal at every phase of RAG—indexing, retrieval, and generation, you name it.
Today, let us show you how we built an incredibly fast RAG app that queries 36M+ vectors in less than 15 milliseconds and produces a response at 430 tokens per second.
Here’s our tech stack to build the app :
Llama Index → for orchestration.
Qdrant → for vector database (with binary quantization).
SambaNova → for the fastest LLM inference engine.
Let’s implement this now (the code is linked towards the end of the issue).
Implementation
This diagram highlights the architecture with all the key components and their interactions.
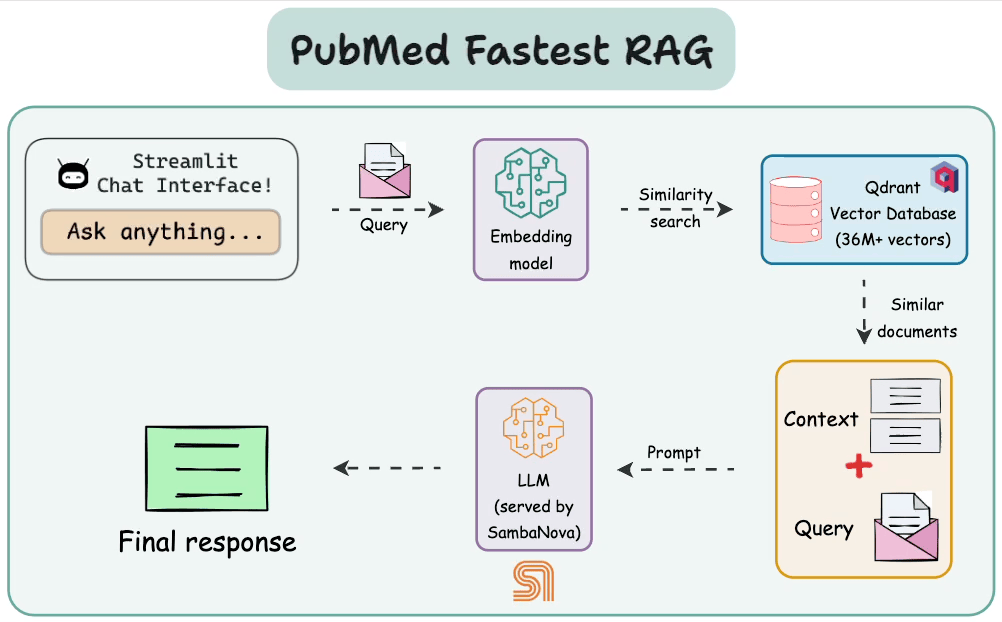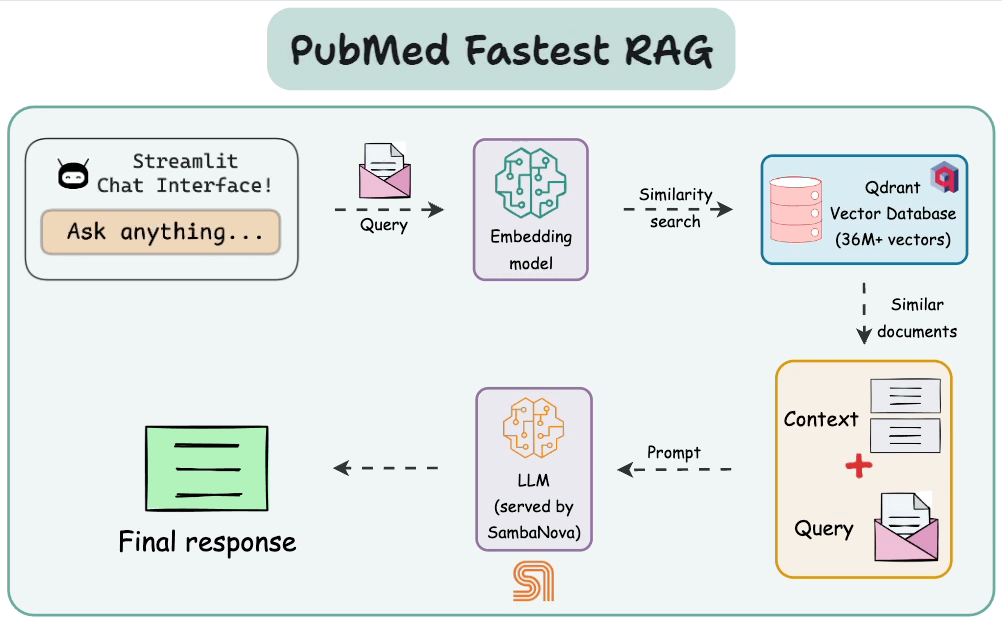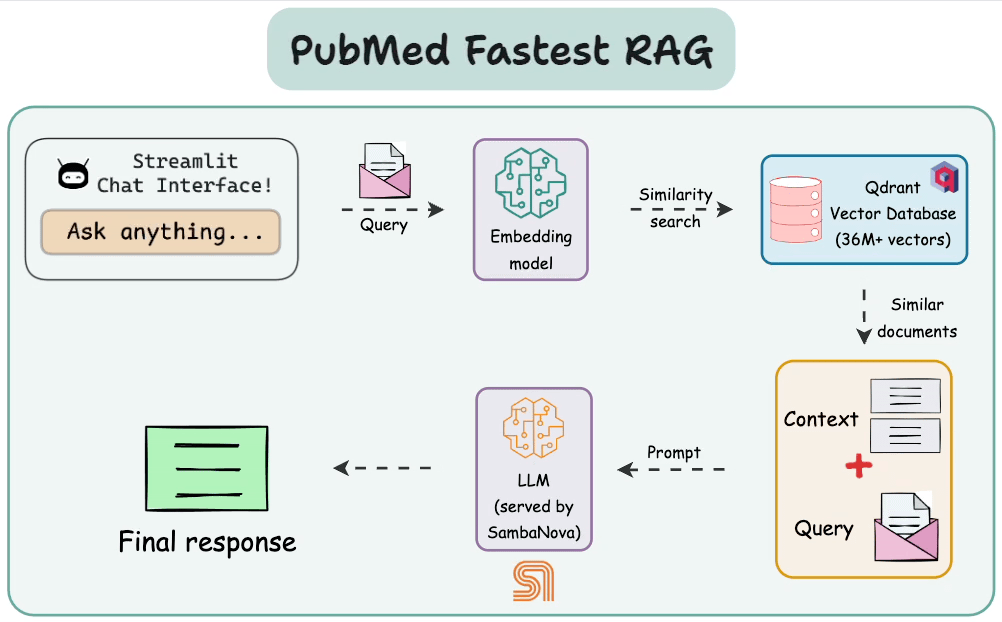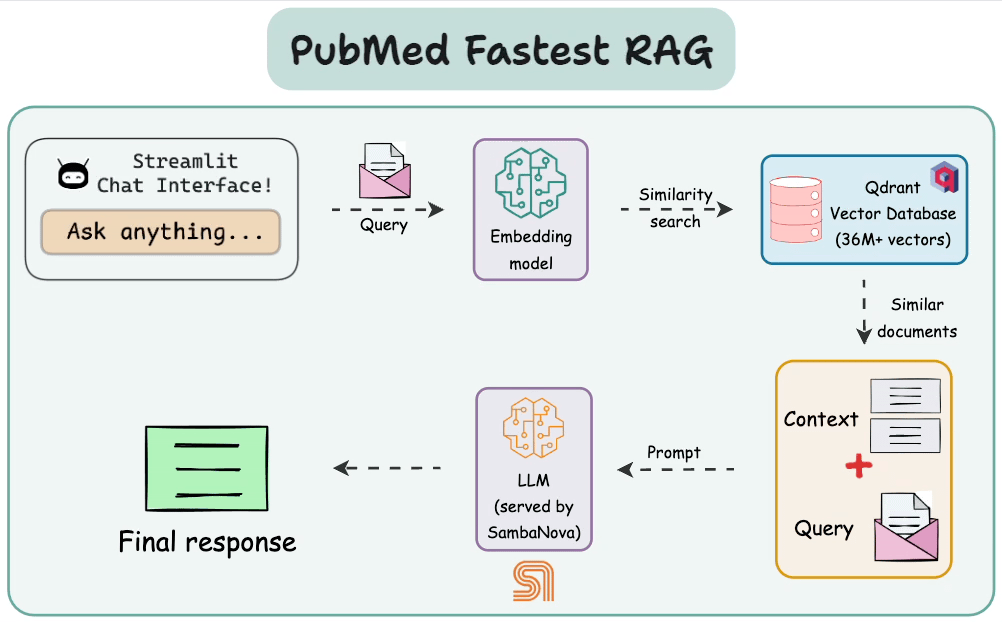
Step 0) Setup
Create a .env file and add your SambaNova API key to leverage the world's fastest AI inference.

You can get the API key here: SambaNova API key.
Step 1) Data Ingestion
This code explains how to set up a Qdrant VectorDB collection and ingest data into it with quantization enabled.
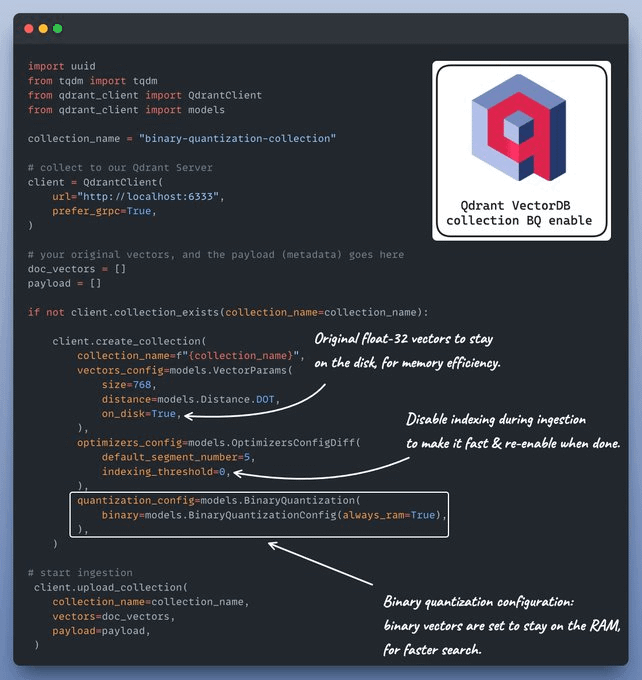
An important thing to note here is the binary quantization configuration, written in the white box above.
Step 2) Retrieval
Next, we define a retriever that uses nomic-embed-text-v1.5 as the embed_model and searches over the binary-quantized index for faster retrieval.
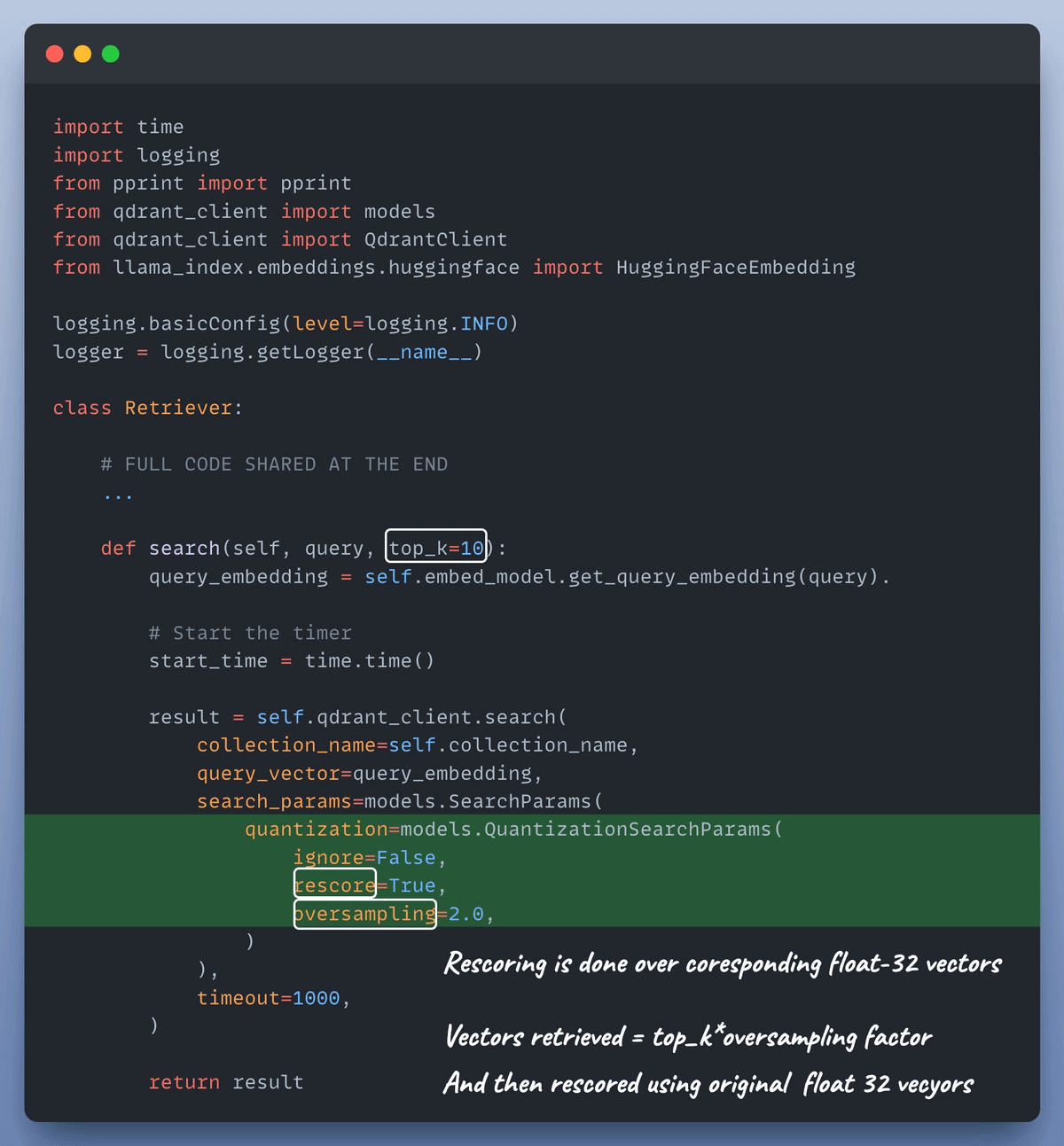
Notice the quantization search parameters used above.
Almost done!
Step 3) RAG
Once we have the retriever ready, we build a RAG pipeline that uses the world's fastest AI inference by SambaNovaAI to serve Llama-3.3-70B:

Here, we integrated SambaNova into our RAG app using its Llama-Index integration.
Done!
A demo of this app is shown below.
Why SambaNova?
GPUs are not fully efficient for AI workloads.
In fact, GPUs were not even originally designed for AI/ML workloads.
That is why engineers are now developing hardware that directly caters to AI tasks and is much more efficient.
SambaNova provides the world’s fastest AI inference using its specialized hardware stack (RDUs)—a 10x faster alternative to GPU.
RDUs are open stack (unlike CUDA), which means you can bring your own models.
Moreover, you can start using most variants of Llama3 on SambaNova for free:

Select the model.
Done.
You can also integrate inference in your LLM apps with SambaNova using its Llama-index integration as follows:
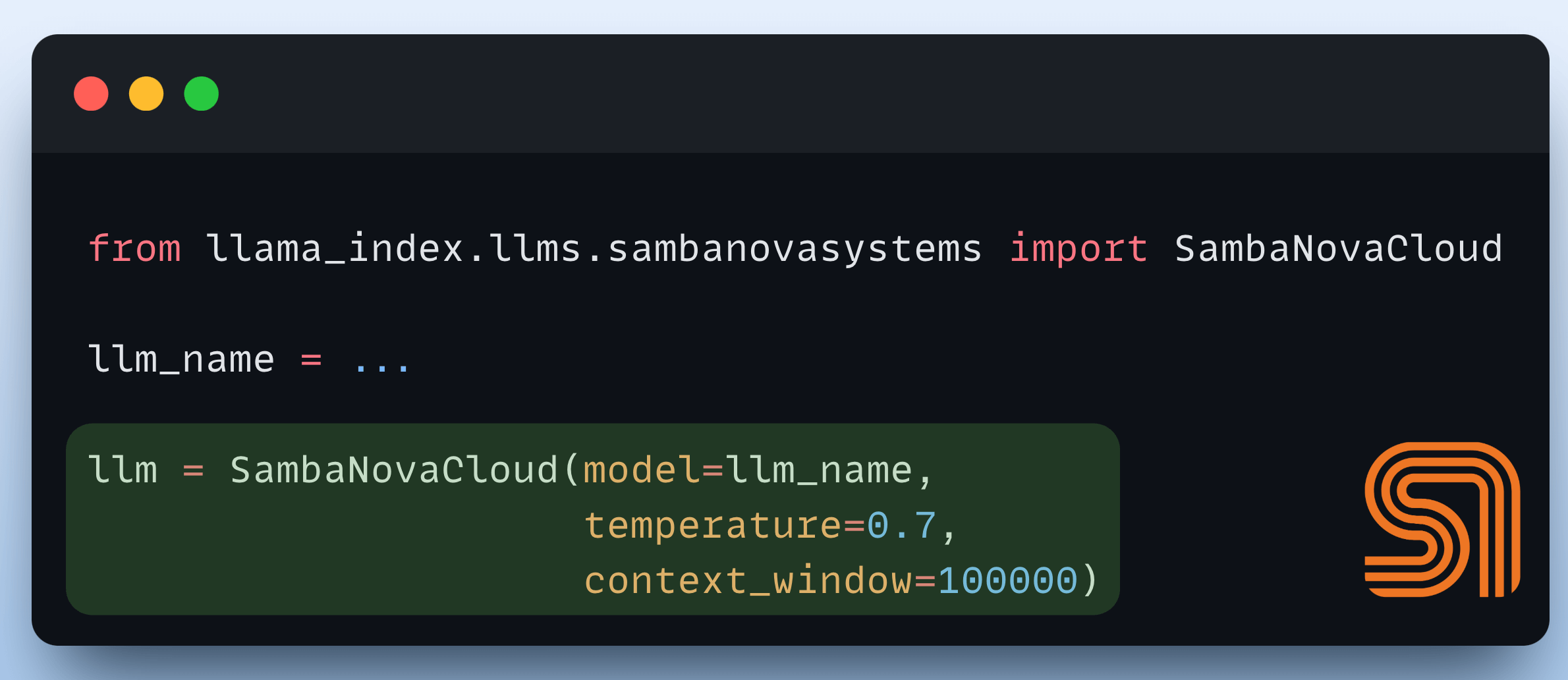
Thanks to SambaNova for showing us their inference engine and partnering with us on today's newsletter.
Find the code for today’s demo here: Fastest RAG stack.
Thanks for reading!
