

Today, we're building an MCP server that every data scientist will love to have.
It’s an MCP server that can generate any type of synthetic dataset.
Synthetic dataset is important because it gives us more data from existing samples, especially when real-world data is limited, imbalanced, or sensitive.
Here’s our tech stack:
Cursor as the MCP host.
SDV to generate realistic tabular synthetic data.
SDV is a Python library that uses ML to create synthetic data resembling real-world patterns. The process involves training a model, sampling data, and validating against the original.
Here's an illustration:
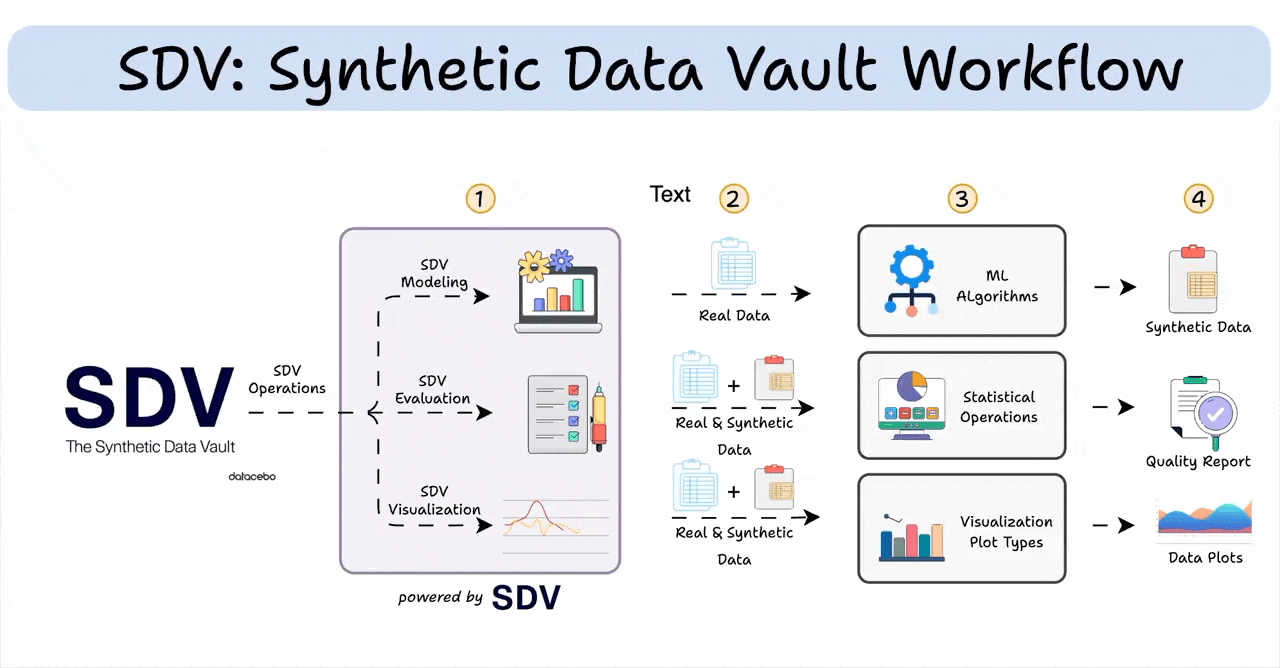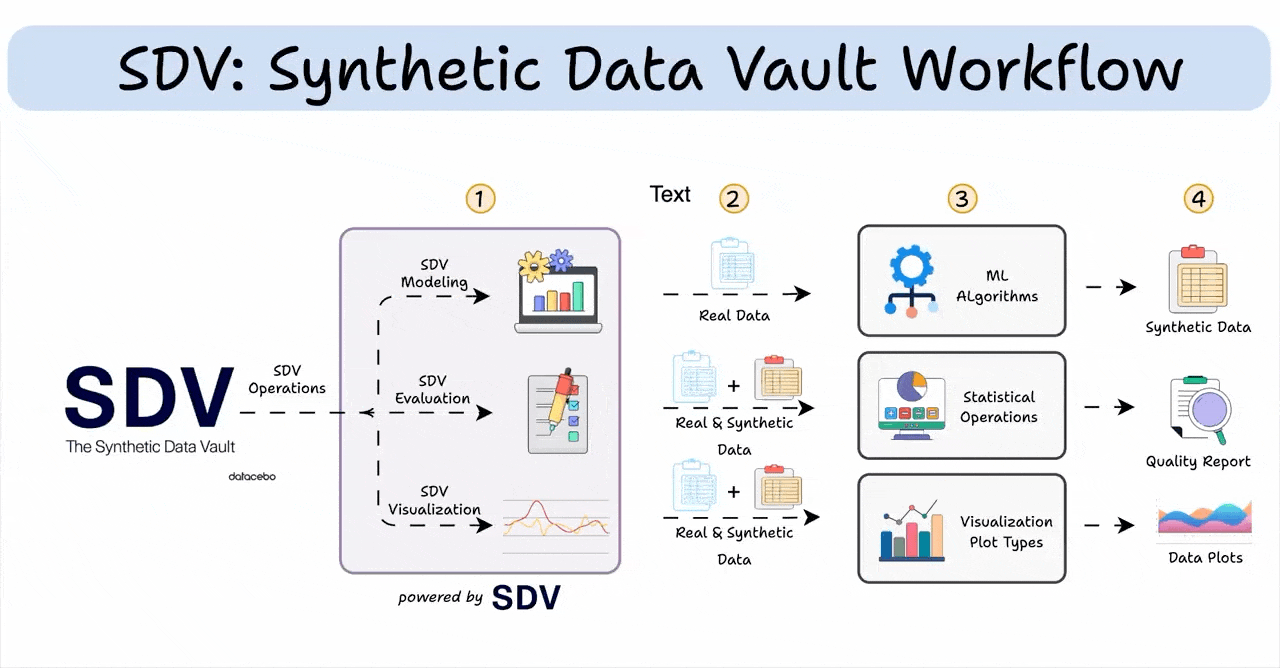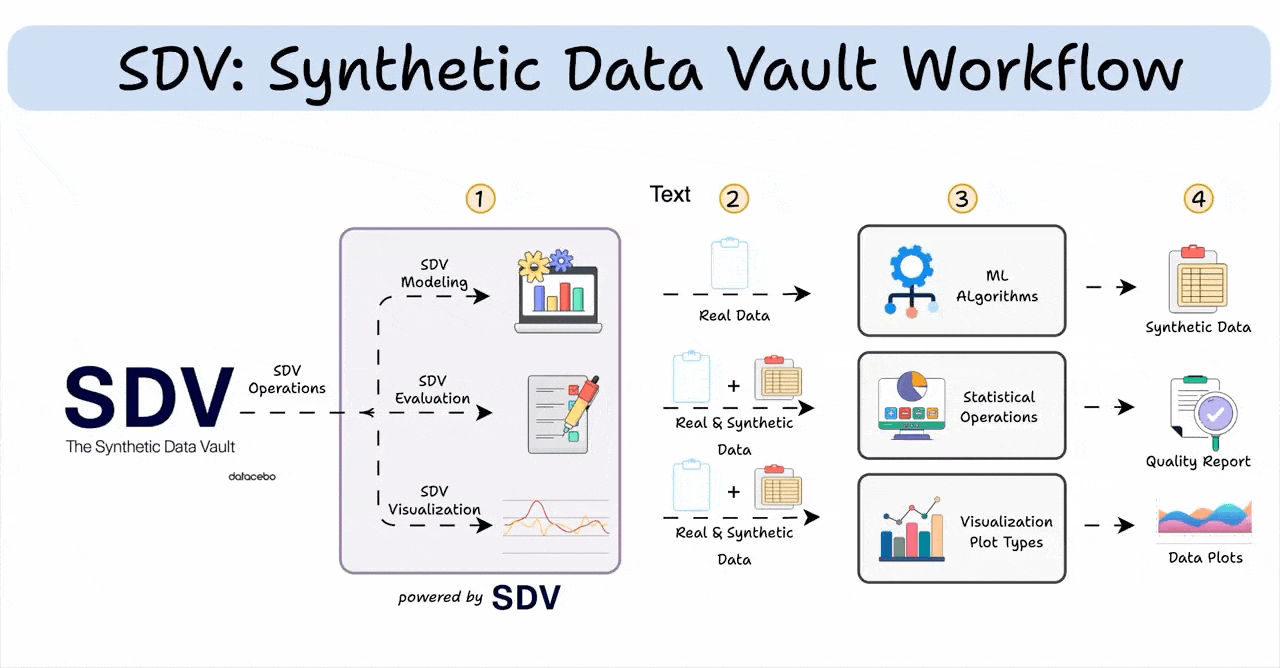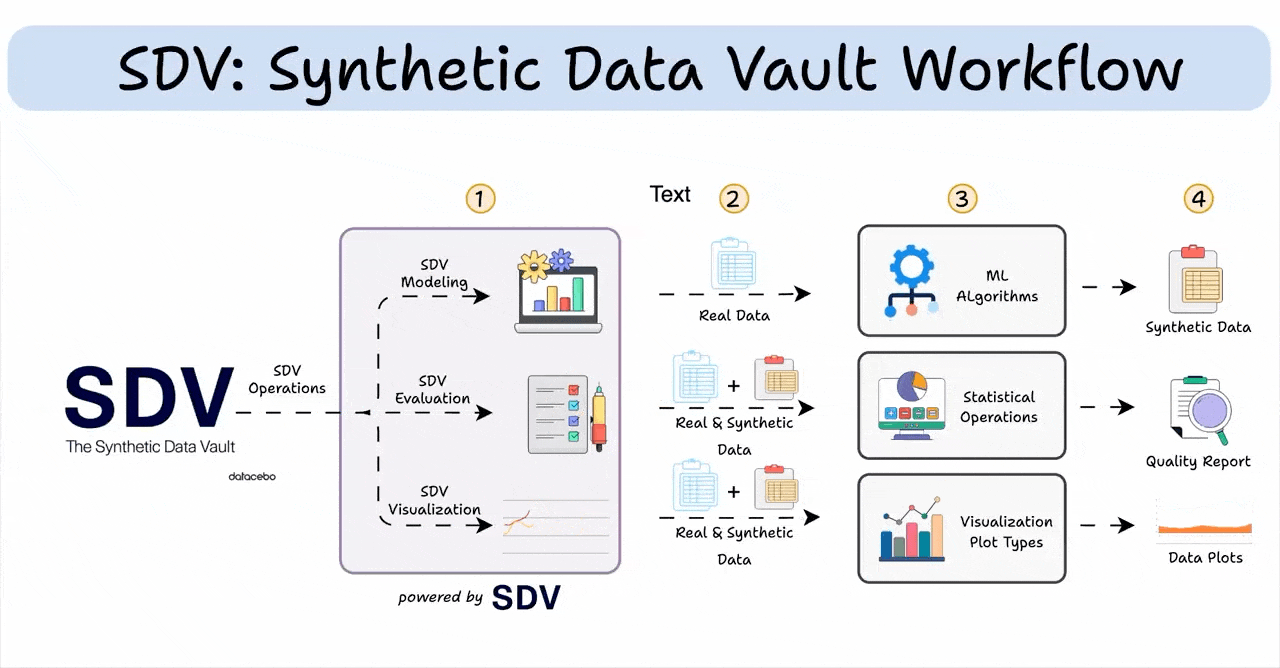
Here’s a system overview of what we are building today:
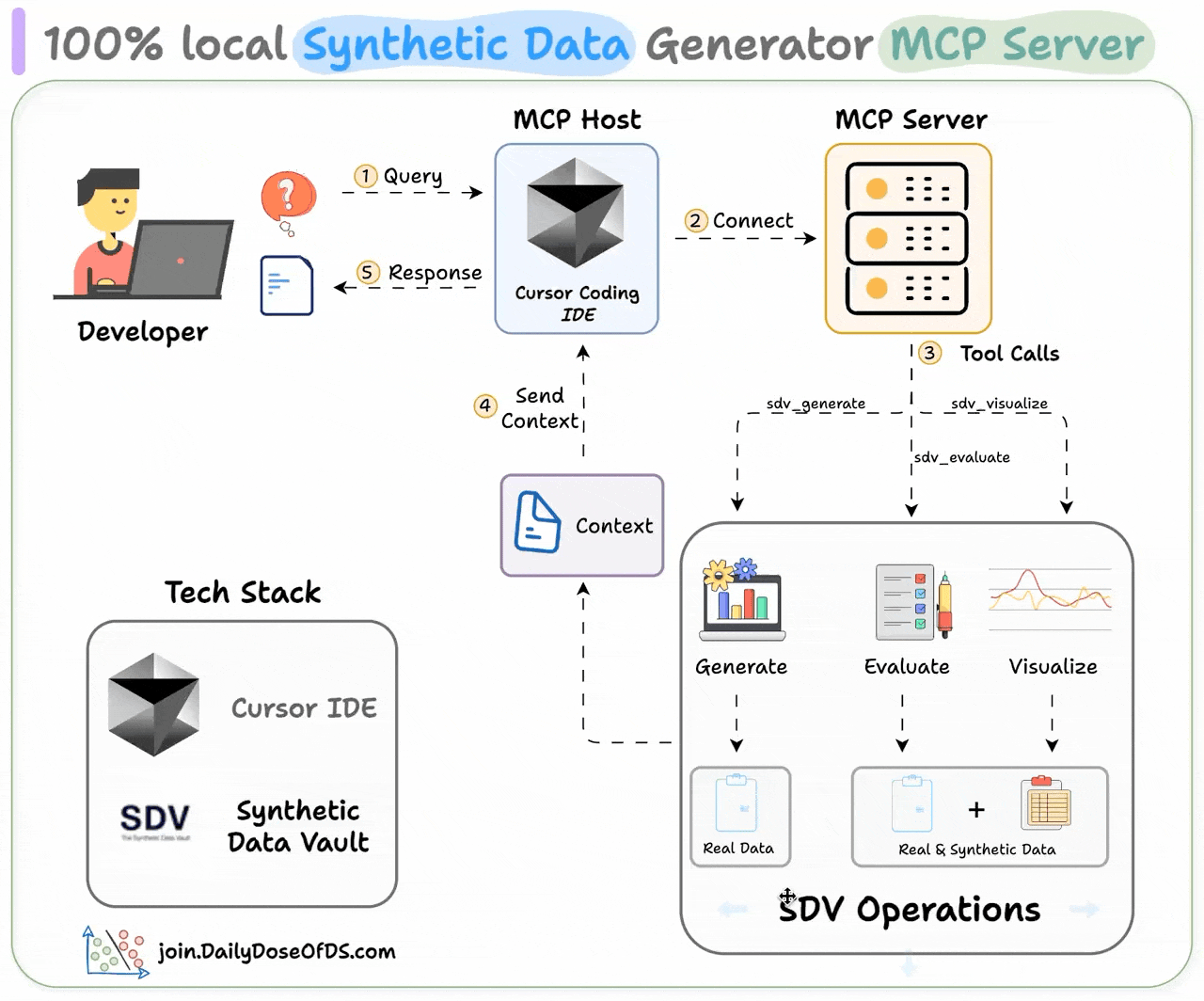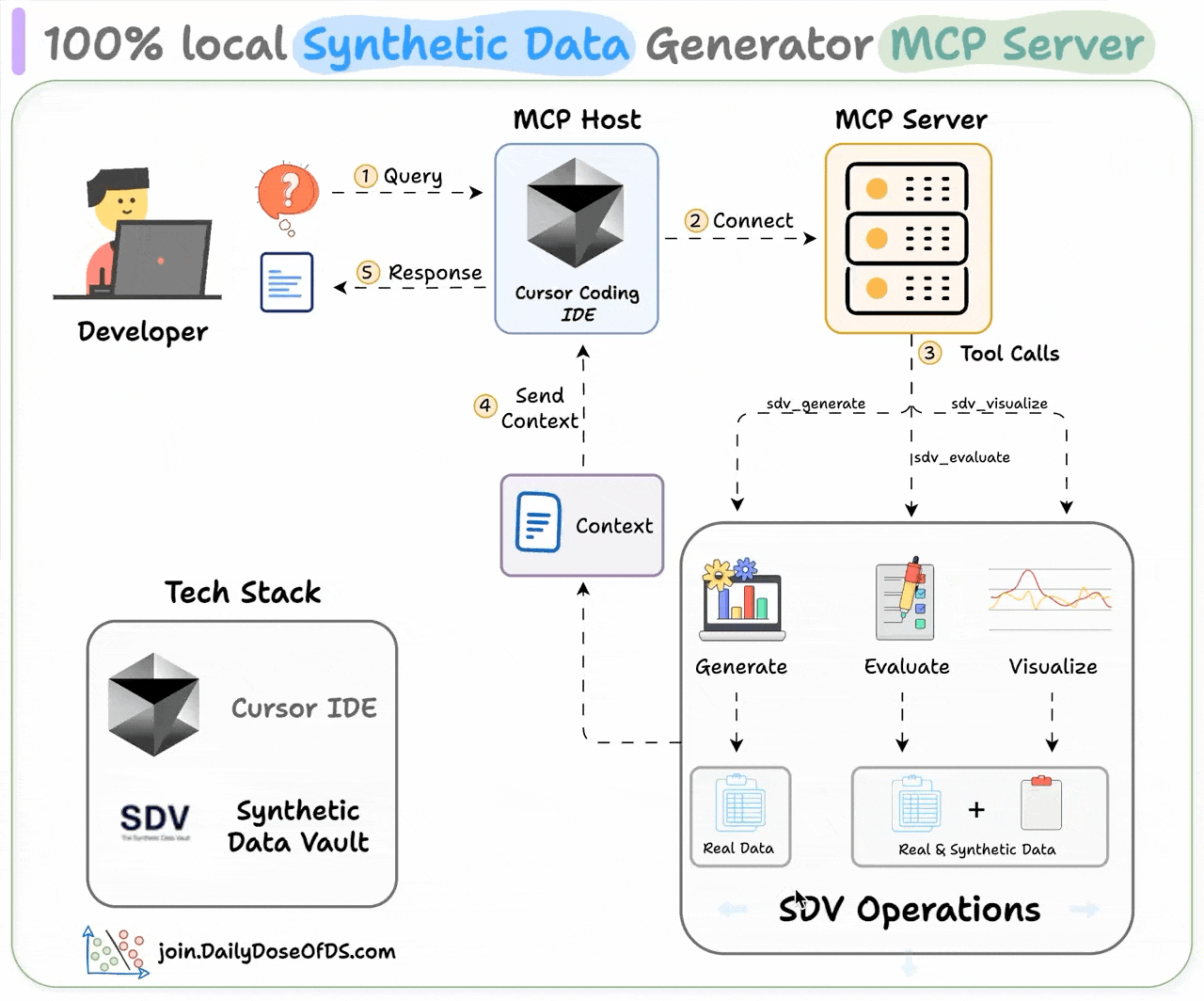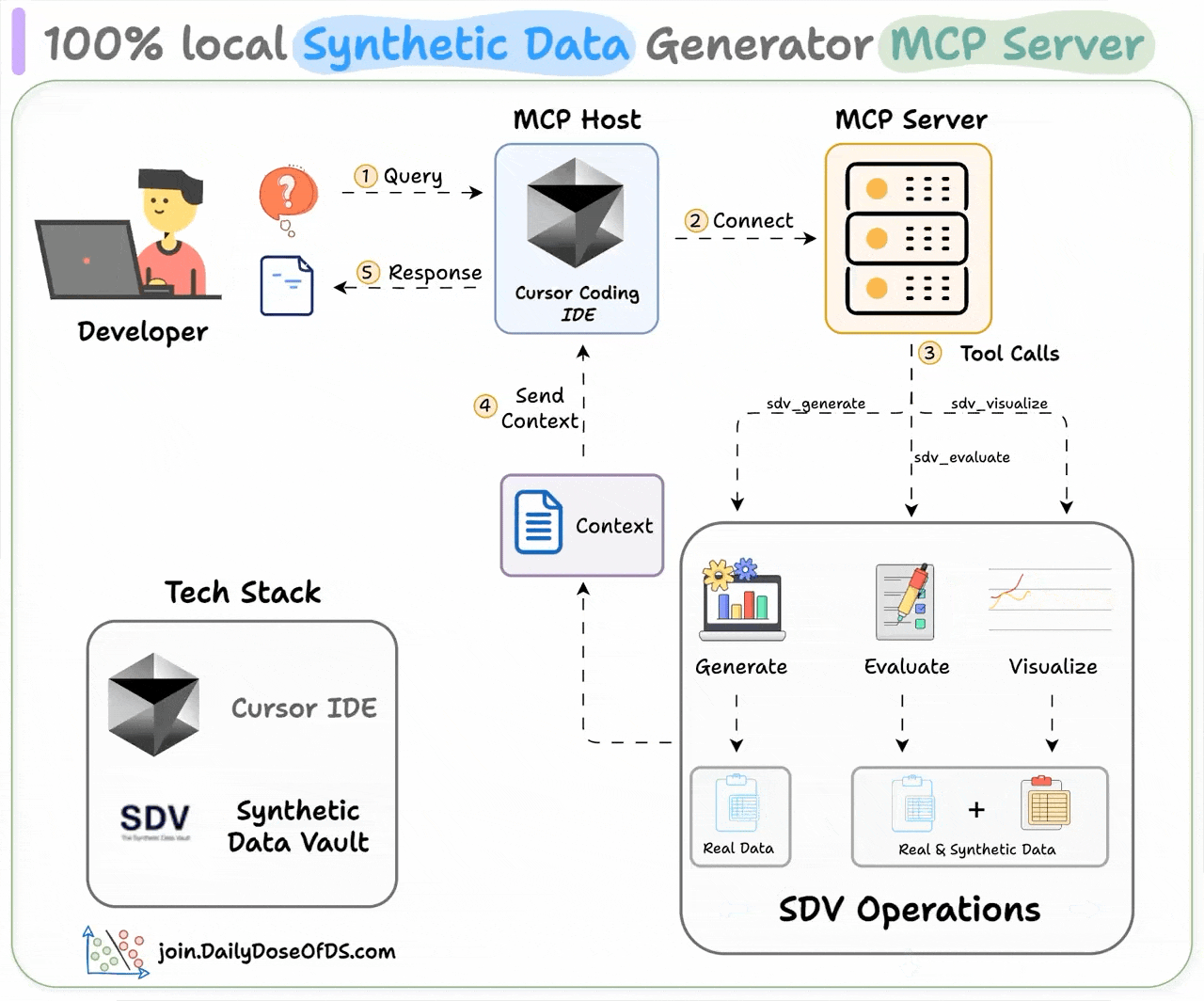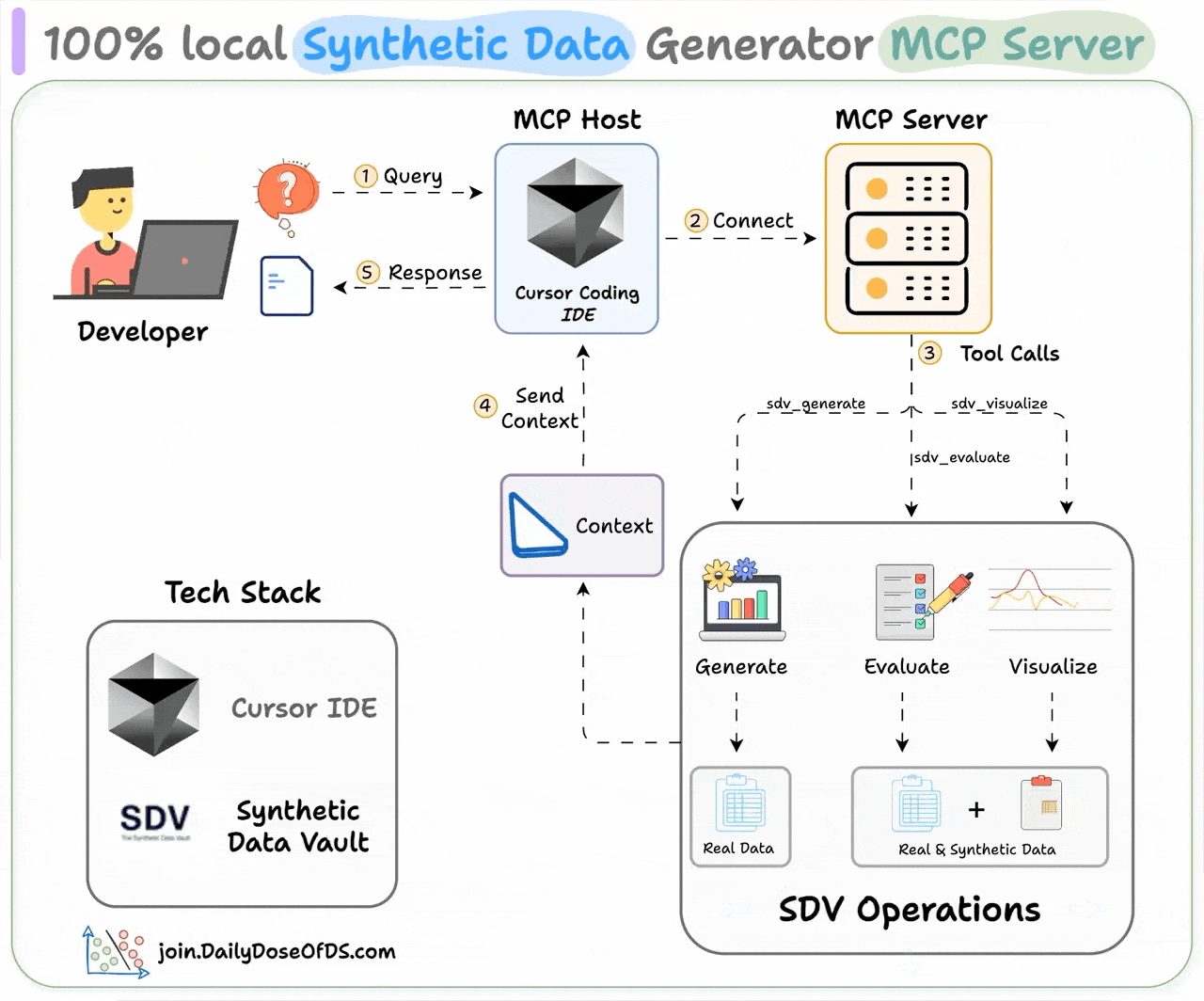
User submits a query
Agent connects to MCP server to find tools
Agent uses appropriate tool based on query
Returns response on synthetic data creation, eval, or visualization
The GitHub repo with the code is linked later in the issue.
Let's code now!
Our MCP server will have three tools:
Tool 1) SDV Generate Tool
This tool creates synthetic data from real data using the SDV Synthesizer.
SDV offers a variety of synthesizers, each utilizing different algorithms to produce synthetic data.

Tool 2) SDV Evaluate Tool
This tool evaluates the quality of synthetic data in comparison to real data.
We will assess statistical similarity to determine which real data patterns are captured by the synthetic data.

Tool 3) SDV Visualize Tool
This tool generates a visualization to compare real and synthetic data for a specific column.
Use this function to visualize a real column alongside its corresponding synthetic column.
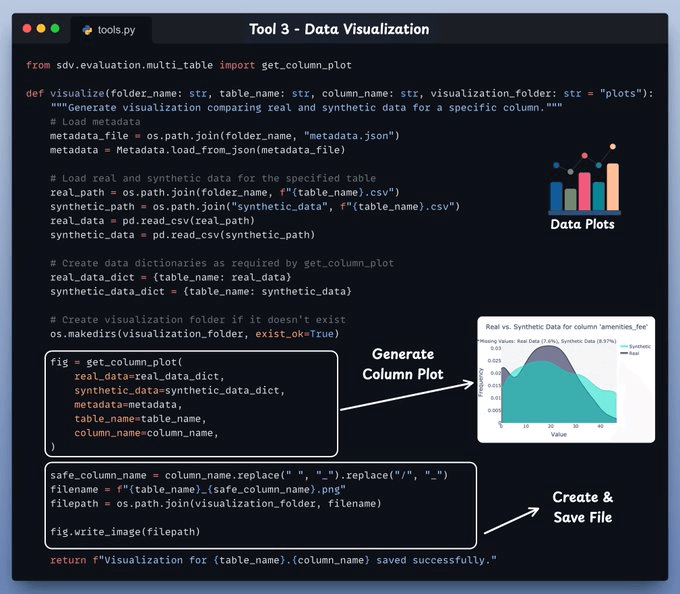
Set up the server
With the tools ready, we implement the server:
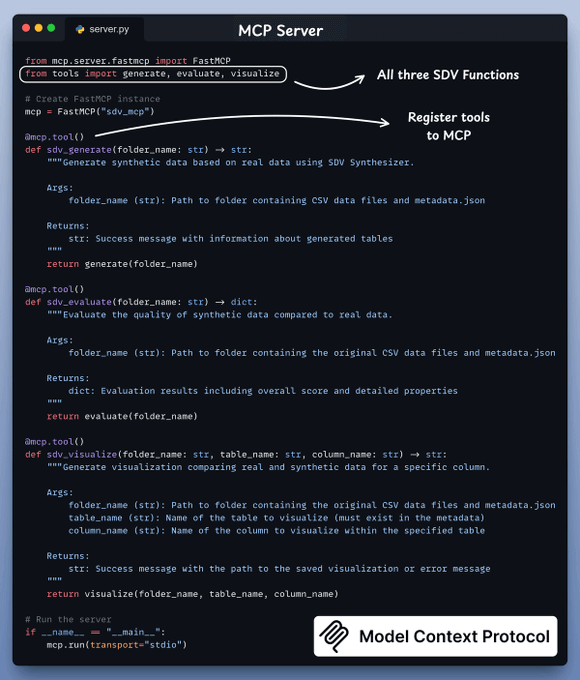
Above, we have a server script that exposes the tool using the MCP library by decorating the functions using the tool decorator.
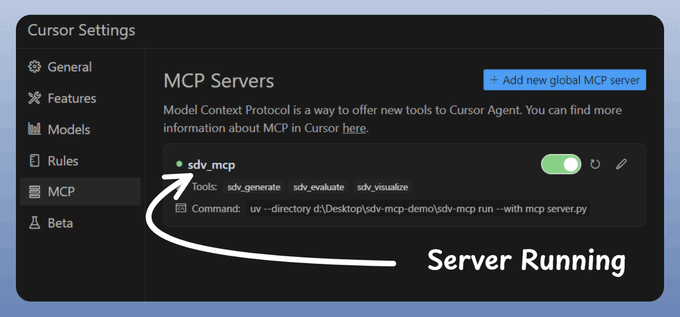
With tools and server ready, let’s integrate it with our Cursor IDE!
Go to: File → Preferences → Cursor Settings → MCP → Add new global MCP server.
In the JSON file, add what's shown below:

Done!
Your synthetic data generator MCP server is live and connected to Cursor!
We open a new chat in Cursor and ask it to generate a synthetic dataset for the available seed dataset as follows:

Here’s a sample of the synthetic dataset generated using the original seed data:

We can also use the evaluate MCP tool defined earlier to get a quantitative evaluation report using SDV.

This produces a thorough evaluation report with a remark that the generated data resembles the original dataset:

Finally, we can also use the visualization tool to generate a visualization comparing real and synthetic data for a specific column:

This produces a response in the chat stating that it has created a plot successfully:

And finally, we have the following plot generated by SDV:

Perfect!
We have personally worked on several such synthetic data generation use cases and understand its utility in the industry. That is why we mentioned earlier that this is an MCP server that every data scientist will love to have.
If you're dealing with data scarcity or class imbalance, SDV makes it effortless to generate high-quality synthetic data.
Just point it to your dataset folder, and it handles everything from generation to evaluation, right from your IDE, hands-free.
Find the SDV GitHub repo here →
GitHub the GitHub repo with the code here →
Thanks for reading!
